Эквивалентные понятия в ClickStack и Elastic
Elastic Stack и ClickStack
И Elastic Stack, и ClickStack закрывают ключевые роли платформы наблюдаемости, но реализуют их на основе разных принципов проектирования. Эти роли включают:
- UI и оповещения: инструменты для запроса данных, построения дашбордов и управления оповещениями.
- Хранилище и движок запросов: back-end‑системы, отвечающие за хранение данных наблюдаемости и выполнение аналитических запросов.
- Сбор данных и ETL: агенты и конвейеры, которые собирают телеметрию и обрабатывают её перед ингестией.
Таблица ниже показывает, как каждый стек сопоставляет свои компоненты с этими ролями:
| Роль | Elastic Stack | ClickStack | Комментарии |
|---|---|---|---|
| UI и оповещения | Kibana — дашборды, поиск и оповещения | HyperDX — UI в реальном времени, поиск и оповещения | Оба выступают в роли основного интерфейса для пользователей, включая визуализации и управление оповещениями. HyperDX специально разработан для задач наблюдаемости и тесно связан с семантикой OpenTelemetry. |
| Хранилище и движок запросов | Elasticsearch — хранилище JSON-документов с инвертированным индексом | ClickHouse — колонночная база данных с векторизованным движком | Elasticsearch использует инвертированный индекс, оптимизированный для поиска; ClickHouse использует колонночное хранение и SQL для высокопроизводительной аналитики по структурированным и полуструктурированным данным. |
| Сбор данных | Elastic Agent, Beats (например, Filebeat, Metricbeat) | OpenTelemetry Collector (edge + gateway) | Elastic поддерживает кастомные shippers и унифицированный агент, управляемый через Fleet. ClickStack опирается на OpenTelemetry, что позволяет реализовать вендор-независимый сбор и обработку данных. |
| SDK для инструментирования | Elastic APM agents (проприетарные) | OpenTelemetry SDKs (распространяются через ClickStack) | SDK от Elastic жёстко привязаны к стеку Elastic. ClickStack опирается на OpenTelemetry SDKs для логов, метрик и трассировок на основных языках программирования. |
| ETL / обработка данных | Logstash, ingest-конвейеры | OpenTelemetry Collector + материализованные представления ClickHouse | Elastic использует ingest-конвейеры и Logstash для трансформации. ClickStack переносит вычисления на момент вставки данных с помощью материализованных представлений и процессоров OTel collector, которые эффективно и поэтапно трансформируют данные. |
| Архитектурная философия | Вертикально интегрированные, проприетарные агенты и форматы | Основанные на открытых стандартах, слабо связанные компоненты | Elastic строит тесно интегрированную экосистему. ClickStack делает упор на модульность и стандарты (OpenTelemetry, SQL, объектное хранилище) для гибкости и экономичности. |
ClickStack делает акцент на открытых стандартах и совместимости, будучи полностью нативной для OpenTelemetry от сбора данных до UI. Напротив, Elastic предоставляет более вертикально интегрированную, тесно связанную экосистему с проприетарными агентами и форматами.
С учётом того, что Elasticsearch и ClickHouse — это основные движки, отвечающие за хранение, обработку и выполнение запросов к данным в своих стеках, важно понимать, чем они отличаются. Эти системы лежат в основе производительности, масштабируемости и гибкости всей архитектуры наблюдаемости. В следующем разделе рассматриваются ключевые различия между Elasticsearch и ClickHouse — включая то, как они моделируют данные, обрабатывают ингестию, выполняют запросы и управляют хранением.
Elasticsearch и ClickHouse
ClickHouse и Elasticsearch организуют данные и выполняют запросы к ним, используя разные базовые модели, но многие ключевые концепции выполняют схожие функции. В этом разделе приведены основные соответствия для пользователей, знакомых с решениями Elastic, с сопоставлением их эквивалентам в ClickHouse. Хотя терминология отличается, большинство сценариев наблюдаемости можно воспроизвести в ClickStack — зачастую более эффективно.
Ключевые структурные концепции
| Elasticsearch | ClickHouse / SQL | Описание |
|---|---|---|
| Field | Column | Базовая единица данных, содержащая одно или несколько значений определенного типа. Поля в Elasticsearch могут хранить примитивы, а также массивы и объекты. Поле может иметь только один тип. ClickHouse также поддерживает массивы и объекты (Tuples, Maps, Nested), а также динамические типы, такие как Variant и Dynamic, которые позволяют одному столбцу иметь несколько типов. |
| Document | Row | Набор полей (столбцов). Документы в Elasticsearch по умолчанию более гибкие: новые поля добавляются динамически на основе данных (тип выводится из них). Строки в ClickHouse по умолчанию привязаны к схеме: при вставке пользователям необходимо указывать все столбцы строки или их подмножество. Тип JSON в ClickHouse поддерживает эквивалентное создание полуструктурированных динамических столбцов на основе вставленных данных. |
| Index | Table | Единица выполнения запросов и хранения данных. В обеих системах запросы выполняются над индексами или таблицами, которые хранят строки/документы. |
| Implicit | Schema (SQL) | SQL-схемы группируют таблицы в пространства имен и часто используются для управления доступом. В Elasticsearch и ClickHouse нет схем, но обе системы поддерживают безопасность на уровне строк и таблиц посредством ролей и RBAC. |
| Cluster | Cluster / Database | Кластеры Elasticsearch — это рабочие инстансы, которые управляют одним или несколькими индексами. В ClickHouse базы данных организуют таблицы в рамках логического пространства имен, обеспечивая ту же логическую группировку, что и кластер в Elasticsearch. Кластер ClickHouse — это распределенный набор узлов, аналогичный Elasticsearch, но он отделен и не зависит от самих данных. |
Моделирование данных и гибкость
Elasticsearch известен своей гибкостью схемы благодаря dynamic mappings. Поля создаются по мере приёма документов, а типы определяются автоматически — если только схема не задана явно. ClickHouse по умолчанию более строгий — таблицы определяются с явными схемами — но предоставляет гибкость за счёт типов Dynamic, Variant и JSON. Они позволяют выполнять ингестию полуструктурированных данных с динамическим созданием столбцов и выводом типов, аналогичным Elasticsearch. Аналогично, тип Map позволяет хранить произвольные пары ключ-значение — хотя для ключа и значения принудительно используется один и тот же тип.
Подход ClickHouse к гибкости типов более прозрачен и управляем. В отличие от Elasticsearch, где конфликты типов могут вызывать ошибки ингестии, ClickHouse допускает данные смешанных типов в столбцах Variant и поддерживает эволюцию схемы за счёт использования типа JSON.
Если не использовать JSON, схема определяется статически. Если значения для строки не указаны, они либо будут определены как Nullable (не используется в ClickStack), либо примут значение по умолчанию для типа, например пустую строку для String.
Ингестия и преобразование
Elasticsearch использует конвейеры ингестии (ingest pipelines) с процессорами (например, enrich, rename, grok) для преобразования документов перед индексированием. В ClickHouse аналогичная функциональность реализуется с помощью инкрементальных материализованных представлений, которые могут фильтровать и преобразовывать или обогащать входящие данные и вставлять результаты в целевые таблицы. Вы также можете вставлять данные в движок таблицы Null, если вам нужно сохранять только результаты материализованного представления. Это означает, что сохраняются только результаты любых материализованных представлений, а исходные данные отбрасываются — тем самым экономится дисковое пространство.
Для обогащения Elasticsearch поддерживает специализированные enrich-процессоры для добавления контекста к документам. В ClickHouse словари могут использоваться как во время выполнения запроса, так и на этапе ингестии для обогащения строк — например, чтобы сопоставлять IP-адреса с местоположениями или применять поиск по user agent при вставке.
Языки запросов
Elasticsearch поддерживает ряд языков запросов, включая запросы DSL, ES|QL, EQL и KQL (в стиле Lucene), но имеет ограниченную поддержку соединений — доступны только левые внешние соединения с помощью ES|QL. ClickHouse поддерживает полный синтаксис SQL, включая все типы соединений, оконные функции, подзапросы (включая коррелированные) и CTE. Это существенное преимущество для пользователей, которым необходимо коррелировать сигналы наблюдаемости с бизнес-данными или данными об инфраструктуре.
В ClickStack HyperDX предоставляет интерфейс поиска, совместимый с Lucene для упрощения перехода, а также полную поддержку SQL через бэкенд ClickHouse. Этот синтаксис аналогичен синтаксису Elastic query string. Подробное сравнение этого синтаксиса см. в разделе "Поиск в ClickStack и Elastic".
Форматы файлов и интерфейсы
Elasticsearch поддерживает приём данных в формате JSON (и ограниченно — CSV). ClickHouse поддерживает более 70 форматов файлов, включая Parquet, Protobuf, Arrow, CSV и другие — как для ингестии, так и для экспорта. Это упрощает интеграцию с внешними конвейерами и инструментами.
Обе системы предлагают REST API, но ClickHouse также предоставляет родной протокол для взаимодействия с низкой задержкой и высокой пропускной способностью. Родной интерфейс эффективнее HTTP обрабатывает отслеживание прогресса выполнения запросов, сжатие и потоковую передачу и используется по умолчанию в большинстве боевых сценариев ингестии.
Индексация и хранение
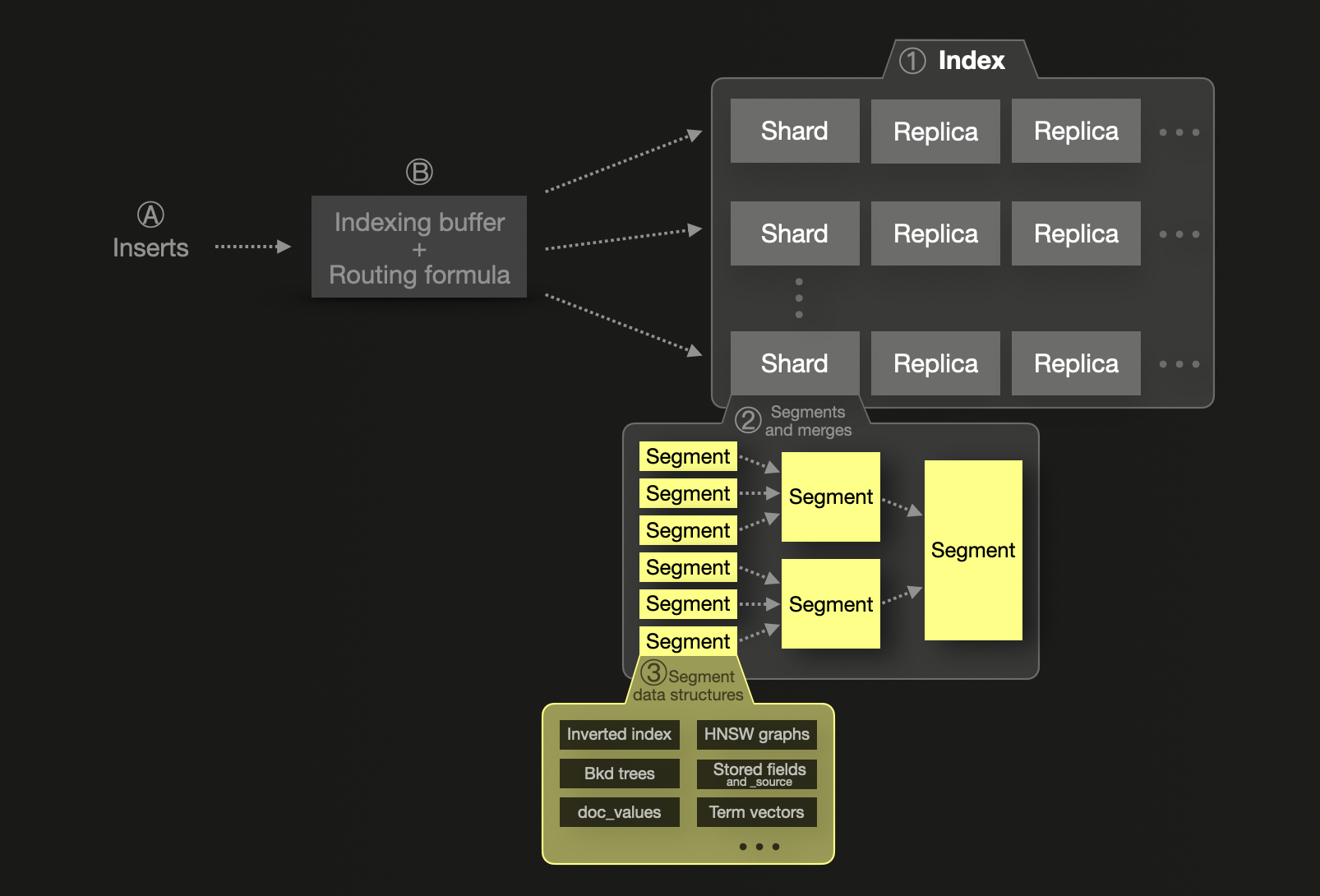
Концепция шардирования является фундаментальной для модели масштабирования Elasticsearch. Каждый ① индекс разбивается на шарды, каждый из которых представляет собой физический индекс Lucene, хранящийся как сегменты на диске. Шард может иметь одну или несколько физических копий, называемых репликами шардов, для обеспечения отказоустойчивости. Для масштабирования шарды и реплики могут быть распределены по нескольким узлам. Один шард ② состоит из одного или нескольких неизменяемых сегментов. Сегмент — это базовая структура индексации Lucene, библиотеки на Java, предоставляющей возможности индексации и поиска, на которой основан Elasticsearch.
Ⓐ Вновь вставленные документы Ⓑ сначала попадают во входной буфер индексации в памяти, который по умолчанию сбрасывается раз в секунду. Для определения целевого шарда для сброшенных документов используется формула маршрутизации, и для этого шарда на диск записывается новый сегмент. Для повышения эффективности запросов и обеспечения физического удаления удалённых или обновлённых документов сегменты в фоне постоянно сливаются в более крупные сегменты, пока не достигнут максимального размера 5 ГБ. При необходимости можно принудительно выполнить слияние в ещё более крупные сегменты.
Elasticsearch рекомендует размер шардов около 50 GB или 200 миллионов документов из‑за накладных расходов на кучу JVM и метаданные. Также существует жёсткий лимит в 2 миллиарда документов на шард. Elasticsearch распараллеливает запросы по шардам, но каждый шард обрабатывается с использованием одного потока, что делает чрезмерный шардинг и дорогостоящим, и контрпродуктивным. Это по своей сути жёстко связывает шардинг и масштабирование: для увеличения производительности требуются дополнительные шарды (и узлы).
Elasticsearch индексирует все поля в инвертированные индексы для быстрого поиска, при необходимости используя doc values для агрегаций, сортировки и доступа к вычисляемым полям. Числовые и гео‑поля используют Block K-D trees для поиска по геопространственным данным, а также по числовым диапазонам и диапазонам дат.
Важно, что Elasticsearch хранит полный исходный документ в _source (сжатый с помощью LZ4, Deflate или ZSTD), тогда как ClickHouse не хранит отдельное представление документа. Данные реконструируются из столбцов во время выполнения запроса, что экономит место на диске. Аналогичную возможность для Elasticsearch предоставляет Synthetic _source, но с рядом ограничений. Отключение _source также имеет последствия, которые не применимы к ClickHouse.
В Elasticsearch мэппинги индекса (эквивалент схем таблиц в ClickHouse) управляют типами полей и структурами данных, используемыми для хранения и выполнения запросов.
ClickHouse, напротив, является колоночной системой — каждый столбец хранится независимо, но всегда отсортирован по первичному/упорядочивающему ключу таблицы. Эта упорядоченность позволяет использовать разрежённые первичные индексы, которые дают ClickHouse возможность эффективно пропускать данные при выполнении запросов. Когда запросы фильтруются по полям первичного ключа, ClickHouse считывает только соответствующие части каждого столбца, что значительно снижает объём дисковых операций ввода‑вывода и повышает производительность — даже без полного индекса по каждому столбцу.
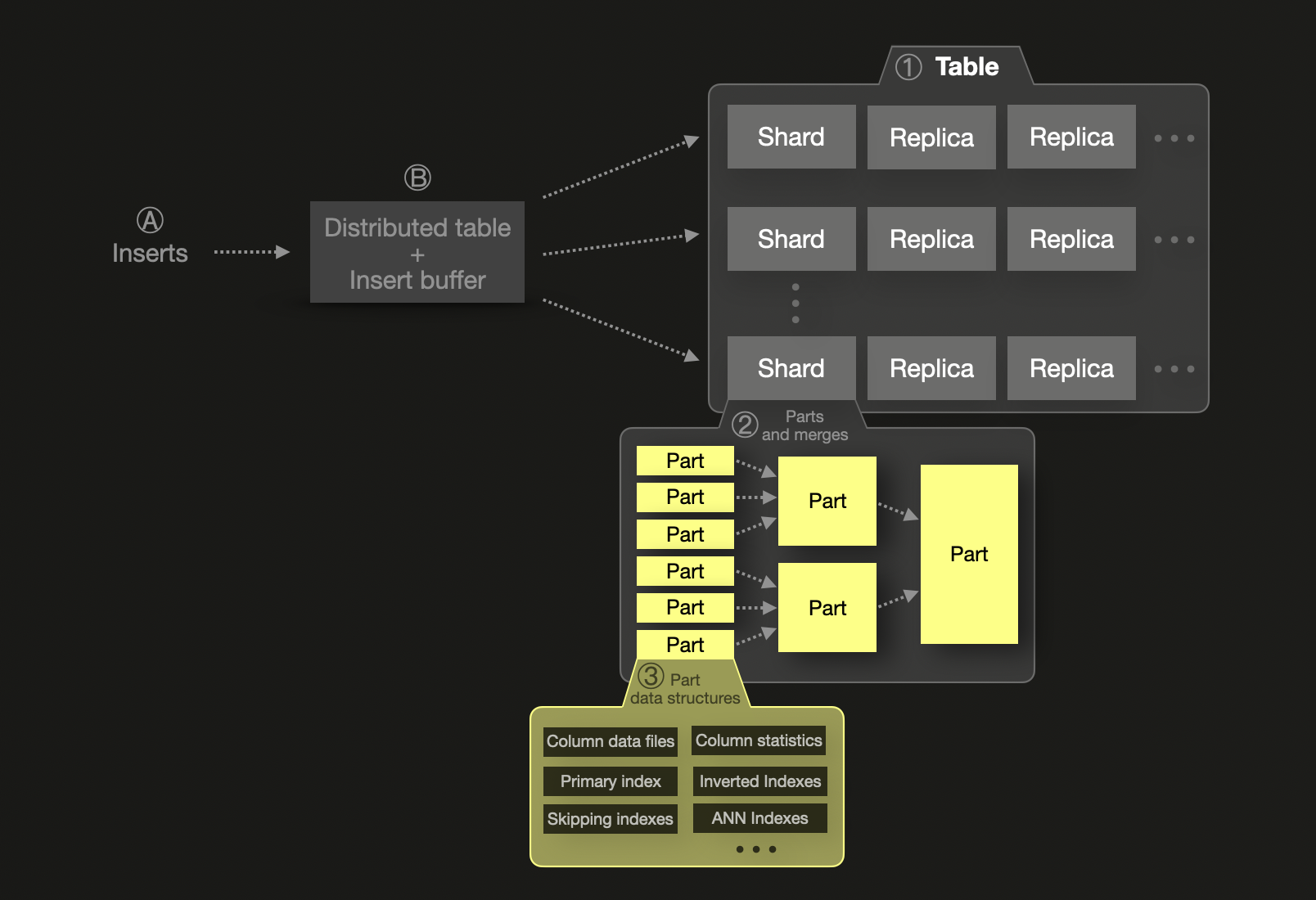
ClickHouse также поддерживает skip‑индексы, которые ускоряют фильтрацию за счёт предварительного вычисления индексных данных для выбранных столбцов. Их необходимо явно определять, но они могут существенно повысить производительность. Кроме того, ClickHouse позволяет пользователям задавать кодеки сжатия и алгоритмы сжатия для каждого столбца — чего Elasticsearch не поддерживает (его сжатие применяется только к хранению JSON в _source).
ClickHouse также поддерживает шардинг, но его модель спроектирована с приоритетом на вертикальное масштабирование. Один шард может хранить триллионы строк и продолжает эффективно работать до тех пор, пока это позволяют память, CPU и диск. В отличие от Elasticsearch, жёсткого лимита на количество строк в шарде нет. Шарды в ClickHouse являются логическими — по сути, это отдельные таблицы — и не требуют партиционирования, если только набор данных не превышает возможности одного узла. Обычно это происходит из‑за ограничений по размеру диска, при этом шардинг ① используется только тогда, когда требуется горизонтальное масштабирование, — что снижает сложность и накладные расходы. В этом случае, аналогично Elasticsearch, шард будет содержать подмножество данных. Данные внутри одного шарда организованы как набор ② неизменяемых частей данных (data parts), содержащих ③ несколько структур данных.
Обработка внутри шарда ClickHouse полностью параллелизована, и пользователям рекомендуется масштабировать систему вертикально, чтобы избежать сетевых затрат, связанных с перемещением данных между узлами.
Вставки в ClickHouse по умолчанию синхронные — запись подтверждается только после фиксации (commit), — но могут быть настроены асинхронные вставки, чтобы обеспечить буферизацию и пакетирование данных, подобные Elasticsearch. Если используются асинхронные вставки данных, то Ⓐ вновь вставляемые строки сначала попадают в Ⓑ буфер вставки в памяти (insert buffer), который по умолчанию сбрасывается каждые 200 миллисекунд. Если используется несколько шардов, распределённая таблица применяется для маршрутизации вновь вставляемых строк в целевой шард. Для шарда на диске создаётся новая part.
Распределение и репликация
Хотя и Elasticsearch, и ClickHouse используют кластеры, шарды и реплики для обеспечения масштабируемости и отказоустойчивости, их модели существенно различаются по реализации и характеристикам производительности.
Elasticsearch использует модель репликации primary–secondary. Когда данные записываются в первичный шард, они синхронно копируются в одну или несколько реплик. Эти реплики сами по себе являются полноценными шардами, распределёнными по узлам для обеспечения избыточности. Elasticsearch подтверждает запись только после того, как все обязательные реплики подтвердят операцию — модель, обеспечивающая семантику, близкую к последовательной согласованности, хотя грязные чтения с реплик возможны до полной синхронизации. Master-узел координирует кластер, управляя размещением шардов, их состоянием и выборами лидера.
Напротив, ClickHouse по умолчанию использует eventual consistency, координируемую с помощью Keeper — лёгкой альтернативы ZooKeeper. Записи могут отправляться на любую реплику напрямую или через distributed table, которая автоматически выбирает реплику. Репликация асинхронная — изменения распространяются на другие реплики после подтверждения записи. Для более строгих гарантий ClickHouse поддерживает последовательную согласованность, при которой записи подтверждаются только после фиксации на всех репликах, хотя этот режим используется редко из‑за влияния на производительность. Distributed tables унифицируют доступ к нескольким шардам, перенаправляя запросы SELECT на все шарды и объединяя результаты. Для операций INSERT они балансируют нагрузку, равномерно распределяя данные по шардам. Репликация в ClickHouse очень гибкая: любая реплика (копия шарда) может принимать записи, а все изменения асинхронно синхронизируются с остальными. Такая архитектура позволяет продолжать обслуживать запросы при сбоях или в ходе обслуживания, при этом ресинхронизация выполняется автоматически — отпадает необходимость в принудительной модели primary–secondary на уровне данных.
В ClickHouse Cloud архитектура использует модель вычислений без общих ресурсов (shared-nothing), при которой один шард поддерживается объектным хранилищем. Это заменяет традиционную высокую доступность на основе реплик и позволяет одному шарду одновременно читаться и записываться несколькими узлами. Разделение хранилища и вычислений обеспечивает эластичное масштабирование без явного управления репликами.
Подводя итог:
- Elastic: шарды — это физические структуры Lucene, привязанные к памяти JVM. Чрезмерное дробление на шарды приводит к ухудшению производительности. Репликация синхронная и координируется master-узлом.
- ClickHouse: шарды логические и вертикально масштабируемые, с высокоэффективным локальным исполнением. Репликация асинхронная (но может быть и последовательной), а координация — лёгкая.
В конечном счёте, ClickHouse делает ставку на простоту и производительность при масштабировании, минимизируя необходимость тонкой настройки шардов и при этом предоставляя при необходимости сильные гарантии согласованности.
Дедупликация и маршрутизация
Elasticsearch выполняет дедупликацию документов на основе их _id, маршрутизируя их на соответствующие шарды. ClickHouse не хранит идентификатор строки по умолчанию, но поддерживает дедупликацию на этапе вставки, позволяя пользователям безопасно повторять неудачные вставки. Для более тонкого контроля ReplacingMergeTree и другие движки таблиц позволяют выполнять дедупликацию по определённым столбцам.
Маршрутизация индекса в Elasticsearch гарантирует, что конкретные документы всегда направляются на конкретные шарды. В ClickHouse пользователи могут определять ключи шардинга или использовать таблицы Distributed для достижения аналогичной локальности данных.
Агрегации и модель выполнения
Хотя обе системы поддерживают агрегацию данных, ClickHouse предоставляет значительно больше функций, включая статистические, приближённые и специализированные аналитические функции.
В сценариях наблюдаемости одним из наиболее распространённых применений агрегаций является подсчёт того, как часто возникают определённые сообщения логов или события (и оповещение, если частота выглядит аномальной).
Эквивалентом SQL-запроса ClickHouse SELECT count(*) FROM ... GROUP BY ... в Elasticsearch является агрегация terms, которая относится к агрегациям типа bucket в Elasticsearch.
GROUP BY с count(*) в ClickHouse и агрегация terms в Elasticsearch в целом эквивалентны по функциональности, но сильно различаются по реализации, производительности и качеству результатов.
Эта агрегация в Elasticsearch оценивает результаты в запросах формата "top-N" (например, топ 10 хостов по количеству), когда запрашиваемые данные распределены по нескольким шардам. Такая оценка повышает скорость, но может снижать точность. Пользователи могут уменьшить эту погрешность, анализируя doc_count_error_upper_bound и увеличивая параметр shard_size — ценой большего потребления памяти и более медленного выполнения запросов.
Elasticsearch также требует задать параметр size для всех агрегирований с разбиением на buckets — нет способа вернуть все уникальные группы без явного указания лимита. Агрегации с высокой кардинальностью рискуют достичь ограничений max_buckets или требуют постраничного обхода с помощью composite aggregation, что часто бывает сложно и неэффективно.
ClickHouse, напротив, по умолчанию выполняет точные агрегации. Такие функции, как count(*), возвращают точные результаты без необходимости дополнительной настройки, что делает поведение запросов проще и более предсказуемым.
ClickHouse не накладывает ограничений по размеру. Вы можете выполнять неограниченные запросы с GROUP BY по большим наборам данных. Если пороги по памяти превышаются, ClickHouse может использовать диск. Агрегации, группирующие по префиксу первичного ключа, особенно эффективны и часто выполняются с минимальным потреблением памяти.
Модель выполнения
Вышеописанные различия обусловлены моделями выполнения Elasticsearch и ClickHouse, которые принципиально по-разному подходят к выполнению запросов и параллелизму.
ClickHouse был спроектирован для максимальной эффективности на современном оборудовании. По умолчанию ClickHouse выполняет SQL‑запрос с N параллельными линиями выполнения на машине с N ядрами CPU:
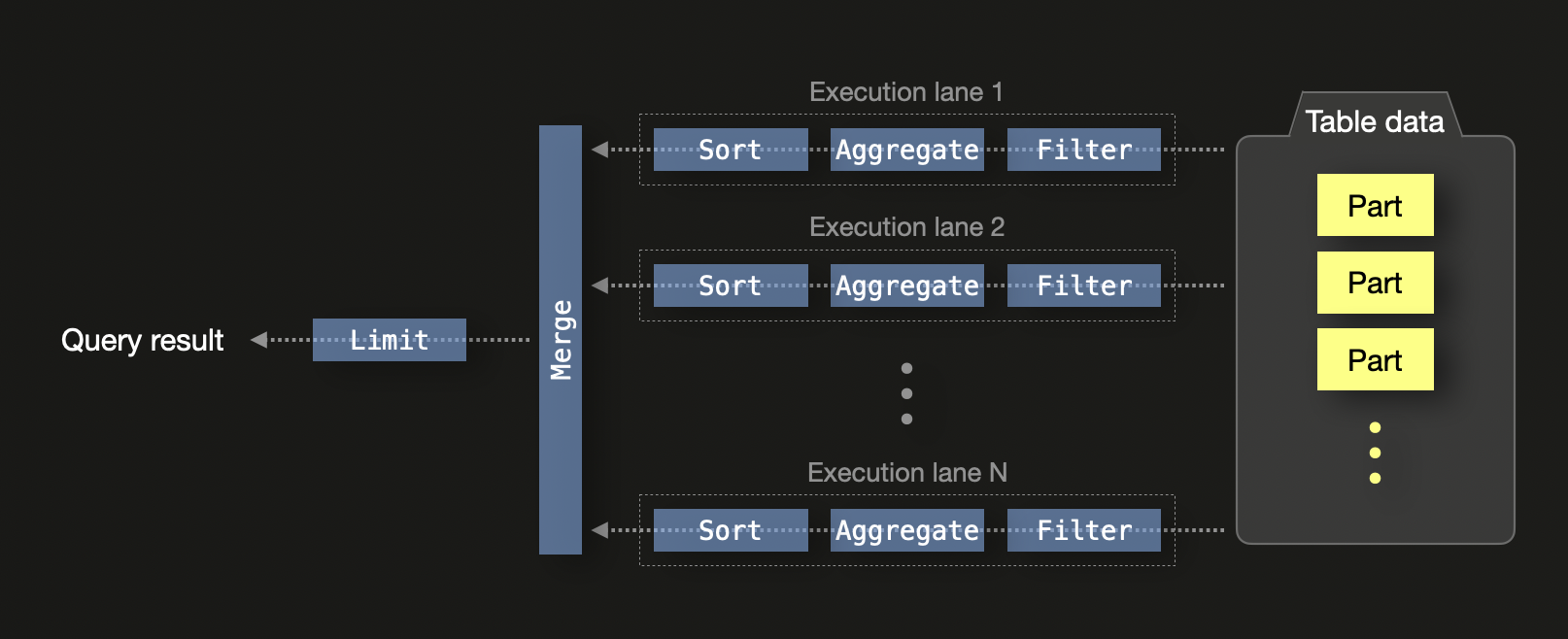
На одном узле линии выполнения разбивают данные на независимые диапазоны, что позволяет одновременно обрабатывать их в нескольких потоках CPU. Это включает фильтрацию, агрегацию и сортировку. Локальные результаты от каждой линии в итоге объединяются, и применяется оператор LIMIT, если в запросе присутствует соответствующая секция.
Выполнение запроса дополнительно параллелизуется за счет:
- SIMD‑векторизации: операции над колоночными данными используют SIMD‑инструкции CPU (например, AVX512), что позволяет выполнять пакетную обработку значений.
- Параллелизма на уровне кластера: в распределённых конфигурациях каждый узел локально обрабатывает запрос. Частичные состояния агрегации передаются инициирующему узлу и объединяются. Если ключи
GROUP BYв запросе совпадают с ключами шардинга, слияние может быть минимизировано или полностью исключено.
Эта модель позволяет эффективно масштабировать выполнение по ядрам и узлам, делая ClickHouse хорошо подходящим для крупномасштабной аналитики. Использование частичных состояний агрегации позволяет объединять промежуточные результаты от разных потоков и узлов без потери точности.
Elasticsearch, напротив, назначает по одному потоку на шард для большинства агрегаций, независимо от количества доступных ядер CPU. Эти потоки возвращают локальные для шарда top‑N результатов, которые затем объединяются на координирующем узле. Такой подход может приводить к неполному использованию ресурсов системы и потенциальной неточности глобальных агрегаций, особенно когда часто встречающиеся значения распределены по нескольким шардам. Точность можно повысить, увеличив параметр shard_size, но это приводит к росту потребления памяти и увеличению задержки выполнения запросов.
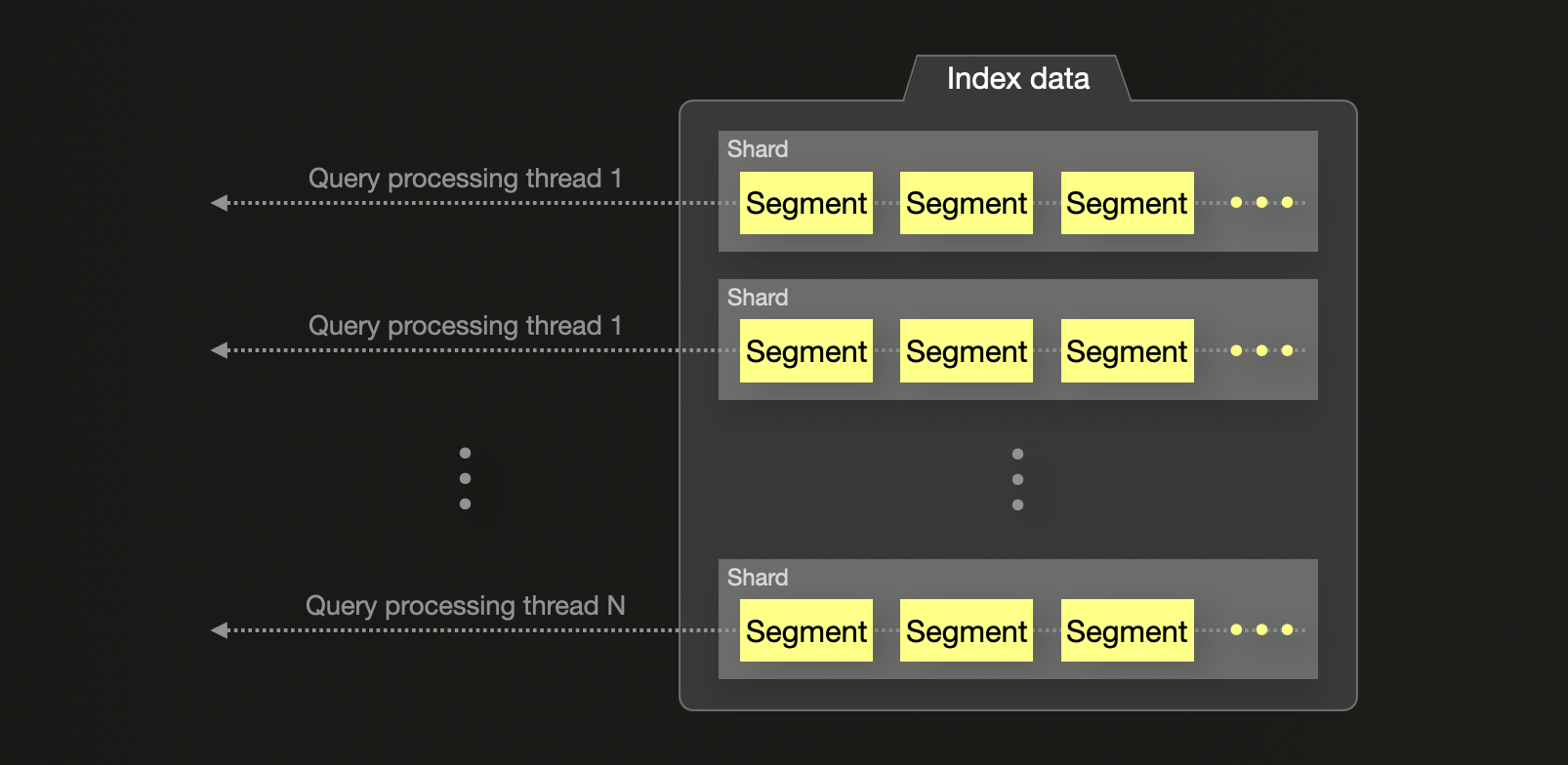
В итоге ClickHouse выполняет агрегации и запросы с более тонкой степенью параллелизма и большим контролем над аппаратными ресурсами, тогда как Elasticsearch опирается на выполнение на уровне шардов с более жёсткими ограничениями.
За дополнительными подробностями о механизмах агрегаций в этих технологиях рекомендуем обратиться к публикации в блоге "ClickHouse vs. Elasticsearch: The Mechanics of Count Aggregations".
Управление данными
Elasticsearch и ClickHouse используют принципиально разные подходы к управлению данными наблюдаемости по временным рядам — особенно в части управления сроками хранения, ротацией и многоуровневым хранением данных.
Управление жизненным циклом индексов vs встроенный TTL
В Elasticsearch долгосрочное управление данными осуществляется с помощью Index Lifecycle Management (ILM) и Data Streams. Эти функции позволяют задавать политики, которые определяют, когда индексы должны переключаться на новые (ролловер, например после достижения определённого размера или возраста), когда старые индексы переносятся в более дешёвое хранилище (например, в warm- или cold-тира), и когда они в конечном итоге удаляются. Это необходимо, потому что Elasticsearch не поддерживает повторную разбивку на шарды (re-sharding), и шарды не могут расти бесконечно без ухудшения производительности. Чтобы управлять размерами шардов и обеспечивать эффективное удаление данных, необходимо периодически создавать новые индексы и удалять старые — по сути, выполнять ротацию данных на уровне индексов.
ClickHouse использует другой подход. Данные, как правило, хранятся в единой таблице и управляются с помощью выражений TTL (time-to-live) на уровне столбца или партиции. Данные могут быть разделены на партиции по дате, что позволяет эффективно удалять их без необходимости создавать новые таблицы или выполнять ролловер индексов. По мере устаревания данных и выполнения TTL-условия ClickHouse автоматически удаляет их — для управления ротацией не требуется дополнительная инфраструктура.
Уровни хранения и архитектуры hot-warm
Elasticsearch поддерживает архитектуры хранения hot-warm-cold-frozen, где данные перемещаются между уровнями хранения с разными характеристиками производительности. Обычно это настраивается через ILM и привязывается к ролям узлов в кластере.
ClickHouse поддерживает многоуровневое хранение через нативные движки таблиц, такие как MergeTree, которые могут автоматически перемещать старые данные между разными томами (например, с SSD на HDD и далее в объектное хранилище) на основе пользовательских правил. Это позволяет имитировать подход hot-warm-cold в Elastic — но без сложности управления несколькими ролями узлов или кластерами.
В ClickHouse Cloud это становится ещё более бесшовным: все данные хранятся в объектном хранилище (например, S3), а вычислительные ресурсы отделены. Данные могут оставаться в объектном хранилище до тех пор, пока к ним не выполнен запрос; в этот момент они извлекаются и кэшируются локально (или в распределённом кэше), обеспечивая тот же профиль затрат, что и уровень frozen в Elastic, но с лучшими характеристиками производительности. Такой подход означает, что данные не нужно перемещать между уровнями хранения, делая архитектуры hot-warm избыточными.
Rollups и инкрементальные агрегации
В Elasticsearch rollups или aggregates реализуются с помощью механизма под названием transforms. Они используются для агрегирования временных рядов по фиксированным интервалам (например, по часам или дням) с использованием модели скользящего окна. Transforms настраиваются как периодически запускаемые фоновые задания, которые агрегируют данные из одного индекса и записывают результаты в отдельный rollup index. Это помогает снизить стоимость выполнения долгосрочных запросов по большим периодам за счёт предотвращения повторных сканирований исходных данных с высокой кардинальностью.
Следующая диаграмма абстрактно иллюстрирует, как работают transforms (обратите внимание, что мы используем синий цвет для всех документов, относящихся к одному и тому же бакету, для которого мы хотим предварительно вычислить агрегированные значения):
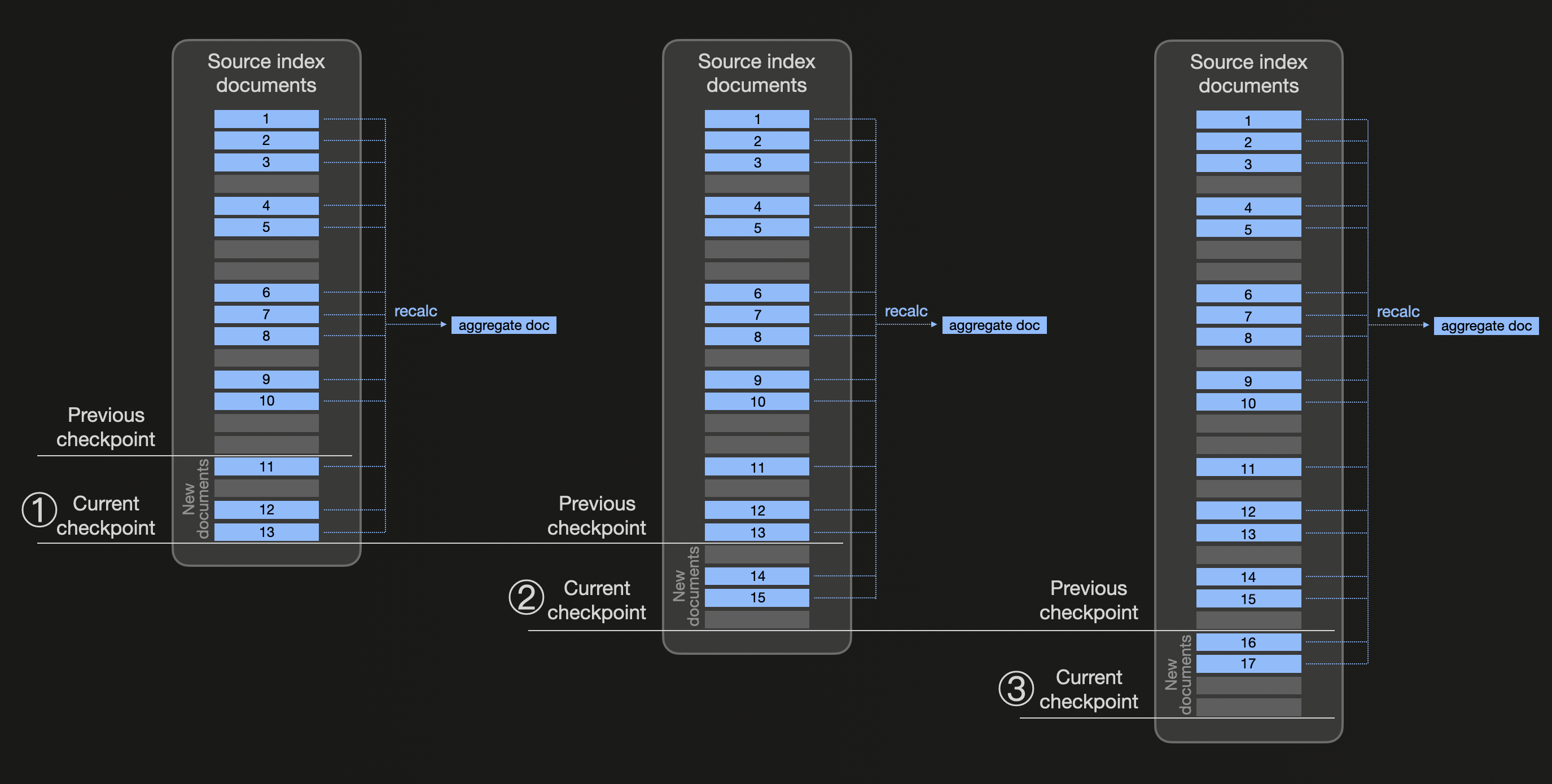
Непрерывные transforms используют checkpoints, основанные на настраиваемом интервале проверки (параметр transform frequency со значением по умолчанию 1 минута). На диаграмме выше мы предполагаем, что ① создаётся новый checkpoint после истечения интервала проверки. Elasticsearch проверяет изменения в исходном индексе трансформации и обнаруживает три новых blue документа (11, 12 и 13), появившихся после предыдущего checkpoint. Поэтому исходный индекс фильтруется по всем существующим blue документам и с помощью composite aggregation (для использования pagination результатов) агрегированные значения пересчитываются (и целевой индекс обновляется документом, который заменяет документ с предыдущими агрегированными значениями). Аналогично, в точках ② и ③ новые checkpoints обрабатываются путём проверки изменений и пересчёта агрегированных значений по всем существующим документам, принадлежащим тому же blue бакету.
ClickHouse использует принципиально иной подход. Вместо периодического переагрегирования данных ClickHouse поддерживает инкрементальные материализованные представления, которые трансформируют и агрегируют данные в момент вставки. Когда новые данные записываются в исходную таблицу, материализованное представление выполняет предопределённый SQL-запрос с агрегацией только над новыми вставленными блоками и записывает агрегированные результаты в целевую таблицу.
Эта модель становится возможной благодаря поддержке в ClickHouse частичных состояний агрегатных функций — промежуточных представлений агрегатных функций, которые могут быть сохранены и позже объединены. Это позволяет поддерживать частично агрегированные результаты, которые быстро читаются и дёшево обновляются. Поскольку агрегация выполняется по мере поступления данных, нет необходимости запускать дорогостоящие периодические задания или повторно агрегировать старые данные.
Ниже схематично показана механика инкрементальных материализованных представлений (обратите внимание, что мы используем синий цвет для всех строк, относящихся к одной и той же группе, для которой мы хотим предварительно вычислить агрегированные значения):
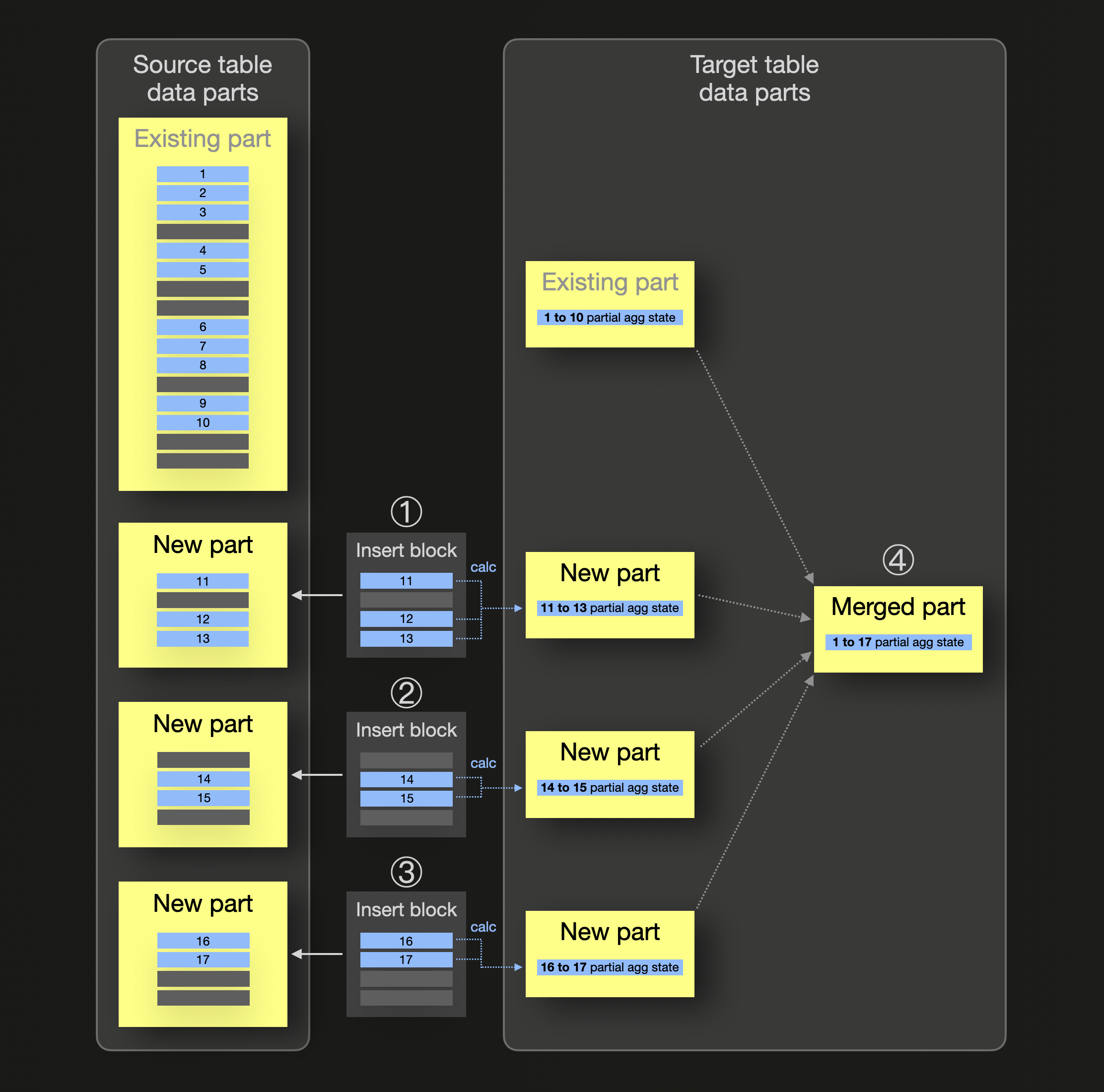
На диаграмме выше исходная таблица материализованного представления уже содержит часть данных, хранящую некоторые blue строки (1–10), относящиеся к одной и той же группе. Для этой группы уже существует и часть данных в целевой таблице представления, которая хранит частичное состояние агрегации для группы blue. Когда выполняются вставки ① ② ③ новых строк в исходную таблицу, для каждой вставки создаётся соответствующая часть данных исходной таблицы и параллельно (только) для каждого блока вновь вставленных строк вычисляется частичное состояние агрегации, которое в виде части данных вставляется в целевую таблицу материализованного представления. ④ Во время фонового слияния частей частичные состояния агрегации объединяются, что приводит к инкрементальной агрегации данных.
Обратите внимание, что все агрегатные функции (их более 90), включая их комбинации с комбинаторами агрегатных функций, поддерживают частичные состояния агрегации.
Более конкретный пример сравнения Elasticsearch и ClickHouse для инкрементальных агрегаций приведён в этом примере.
Преимущества подхода ClickHouse включают:
- Всегда актуальные агрегаты: материализованные представления всегда синхронизированы с исходной таблицей.
- Без фоновых заданий: агрегации выполняются во время вставки, а не во время запроса.
- Лучшая производительность в реальном времени: идеально подходит для нагрузок по наблюдаемости и аналитики в реальном времени, когда свежие агрегаты требуются немедленно.
- Комбинируемость: материализованные представления можно накладывать друг на друга или соединять с другими представлениями и таблицами для более сложных стратегий ускорения запросов.
- Разные TTL: к исходной таблице и целевой таблице материализованного представления можно применять разные настройки TTL.
Эта модель особенно эффективна для сценариев наблюдаемости, когда пользователям нужно вычислять метрики, такие как поминутные показатели ошибок, задержки или топ‑N разбивки, без сканирования миллиардов сырых записей для каждого запроса.
Поддержка lakehouse
ClickHouse и Elasticsearch используют принципиально разные подходы к интеграции с lakehouse. ClickHouse — это полноценный движок выполнения запросов, способный выполнять запросы к данным в форматах lakehouse, таких как Iceberg и Delta Lake, а также интегрироваться с каталогами data lake, такими как AWS Glue и Unity catalog. Эти форматы опираются на эффективное выполнение запросов к файлам Parquet, которые ClickHouse полностью поддерживает. ClickHouse может напрямую читать как таблицы Iceberg, так и Delta Lake, что обеспечивает бесшовную интеграцию с современными архитектурами data lake.
В отличие от него, Elasticsearch тесно связан со своим внутренним форматом хранения данных и движком на базе Lucene. Он не может напрямую выполнять запросы к форматам lakehouse или файлам Parquet, что ограничивает его возможности участия в современных архитектурах data lake. Перед выполнением запросов Elasticsearch требует преобразования данных и загрузки их в собственный проприетарный формат.
Возможности ClickHouse в области lakehouse выходят далеко за рамки простого чтения данных:
- Интеграция с каталогами данных: ClickHouse поддерживает интеграцию с каталогами данных, такими как AWS Glue, что обеспечивает автоматическое обнаружение и доступ к таблицам в объектном хранилище.
- Поддержка объектного хранилища: нативная поддержка выполнения запросов к данным, размещённым в S3, GCS и Azure Blob Storage, без необходимости перемещения данных.
- Федерация запросов: возможность выполнять запросы, коррелирующие данные из нескольких источников, включая таблицы lakehouse, традиционные базы данных и таблицы ClickHouse, с использованием external dictionaries и table functions.
- Инкрементальная загрузка: поддержка непрерывной загрузки из таблиц lakehouse во внутренние таблицы MergeTree с использованием таких механизмов, как S3Queue и ClickPipes.
- Оптимизация производительности: распределённое выполнение запросов по данным lakehouse с использованием cluster functions для повышения производительности.
Эти возможности делают ClickHouse естественным выбором для организаций, внедряющих архитектуры lakehouse, позволяя им использовать как гибкость data lake, так и производительность колонночной базы данных.
