Слияния частей
Что такое слияния частей в ClickHouse?
ClickHouse быстр не только при выполнении запросов, но и при вставках, благодаря своей подсистеме хранения, которая работает аналогично деревьям LSM:
① Вставки (в таблицы из семейства движков MergeTree) создают отсортированные, неизменяемые части данных.
② Вся обработка данных выполняется в виде фоновых слияний частей.
Это делает операции записи лёгкими и высокоэффективными.
Чтобы контролировать количество ^^частей^^ на таблицу и реализовать пункт ② выше, ClickHouse непрерывно сливает (по партициям) более мелкие ^^части^^ в более крупные в фоновом режиме, пока они не достигнут сжатого объёма примерно ~150 GB.
На следующей диаграмме схематично показан этот фоновый процесс слияния:
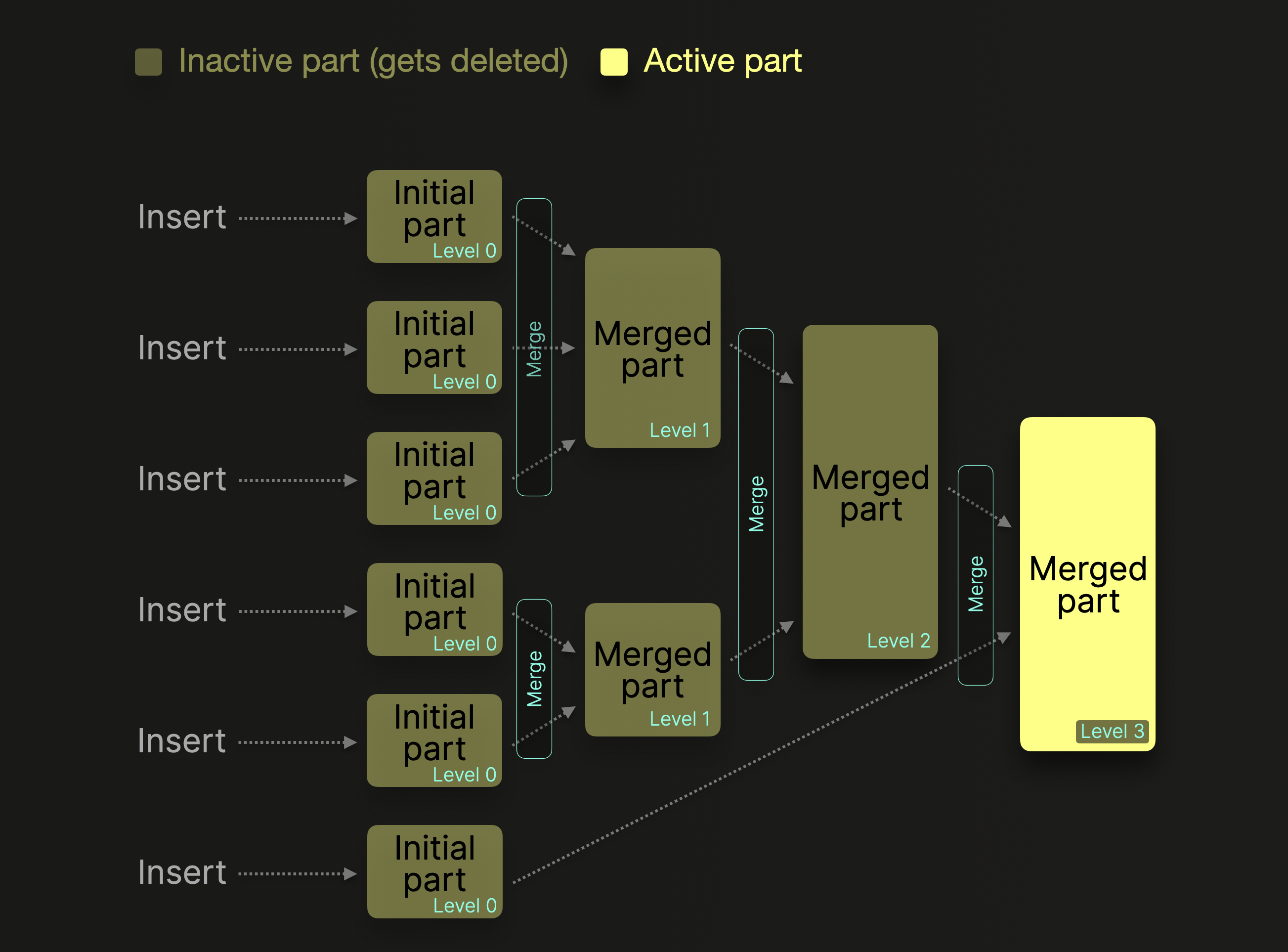
Уровень слияния части увеличивается на единицу при каждом последующем слиянии. Уровень 0 означает, что часть новая и ещё ни разу не сливалась. ^^Части^^, которые были слиты в более крупные ^^части^^, помечаются как неактивные и в конечном итоге удаляются по истечении настраиваемого времени (по умолчанию 8 минут). Со временем это создаёт дерево слитых ^^частей^^. Отсюда и название таблиц семейства MergeTree.
Мониторинг слияний
В примере что такое части таблицы мы показали, что ClickHouse отслеживает все части таблицы ^^parts^^ в системной таблице parts. Мы использовали следующий запрос, чтобы получить уровень слияния и количество сохранённых строк для каждой активной части таблицы из примера:
Результат ранее рассмотренного запроса показывает, что в примерной таблице было четыре активных ^^parts^^, каждый из которых был получен в результате одного слияния первоначально вставленных ^^parts^^:
Выполнив запрос, вы увидите, что четыре ^^части^^ были объединены в одну итоговую часть (при условии, что в таблицу не выполнялись новые вставки):
В ClickHouse 24.10 к встроенным панелям мониторинга была добавлена новая панель слияний. Доступная как в OSS, так и в Cloud через HTTP‑обработчик /merges, она позволяет визуализировать все слияния частей для нашей примерной таблицы:
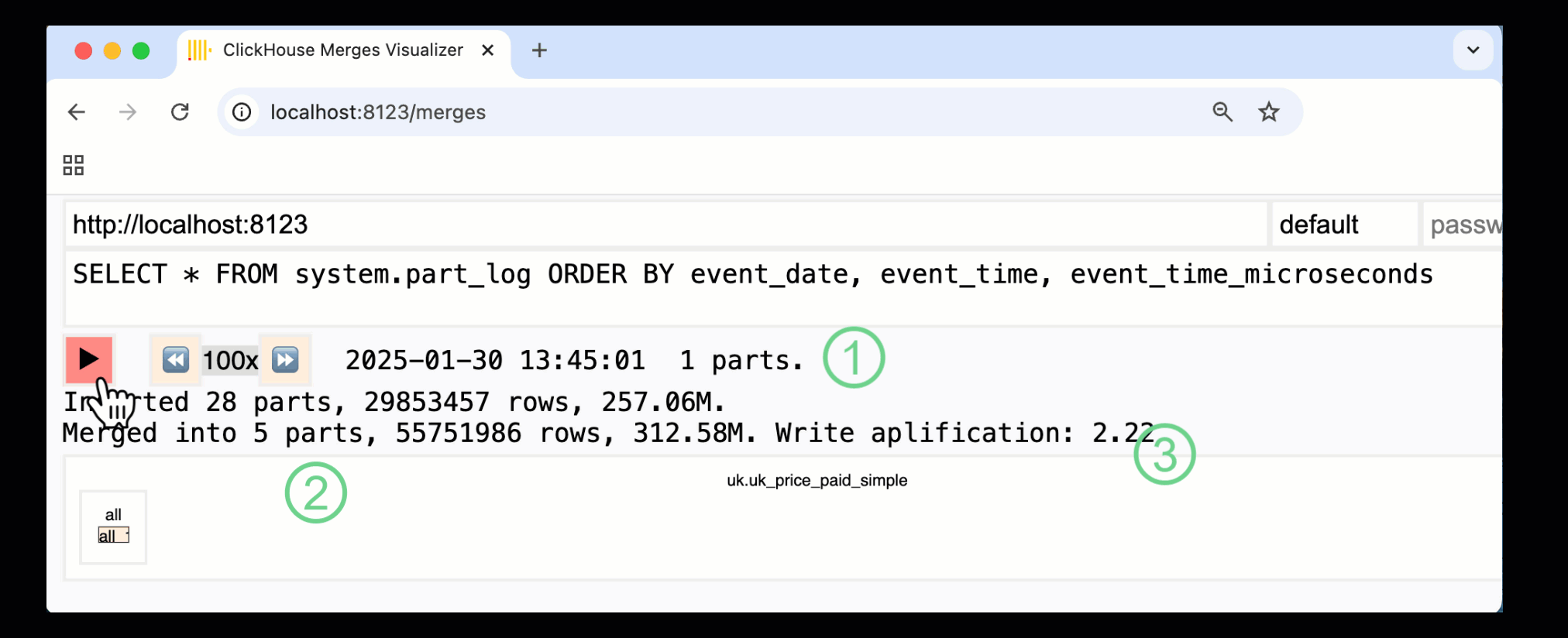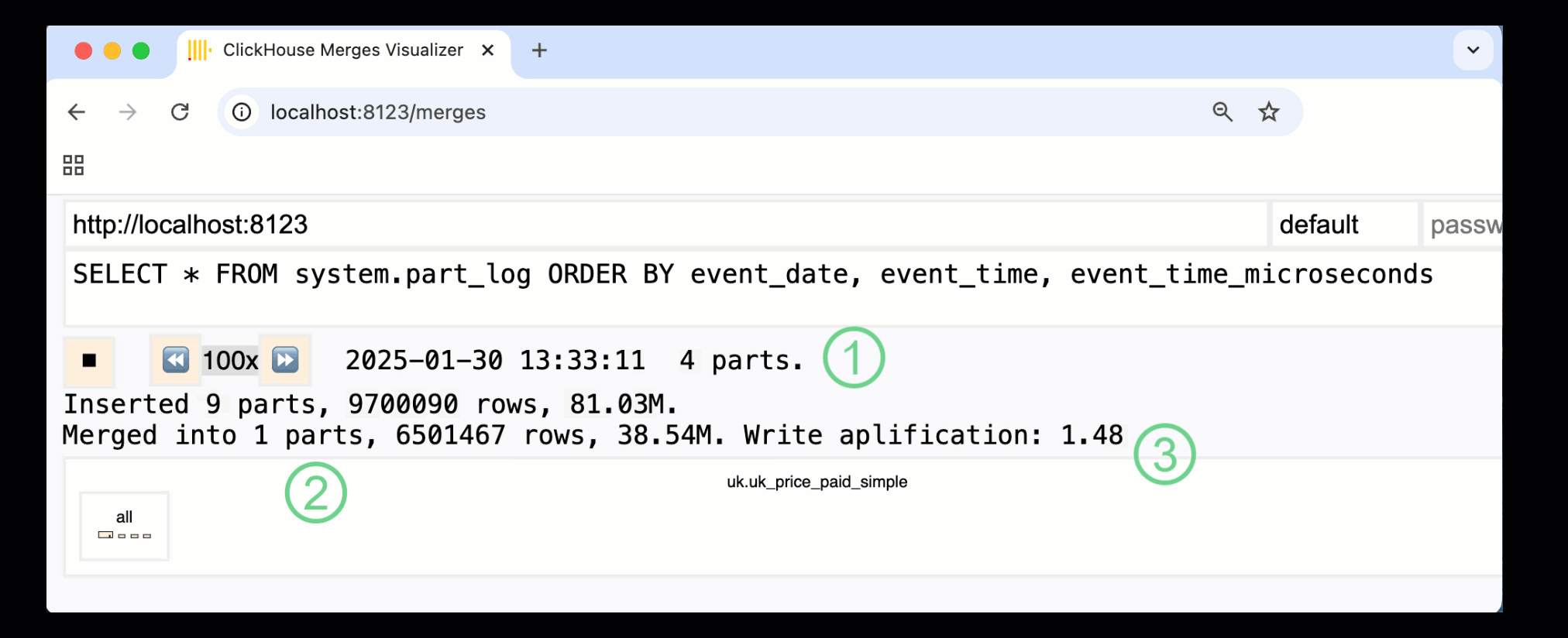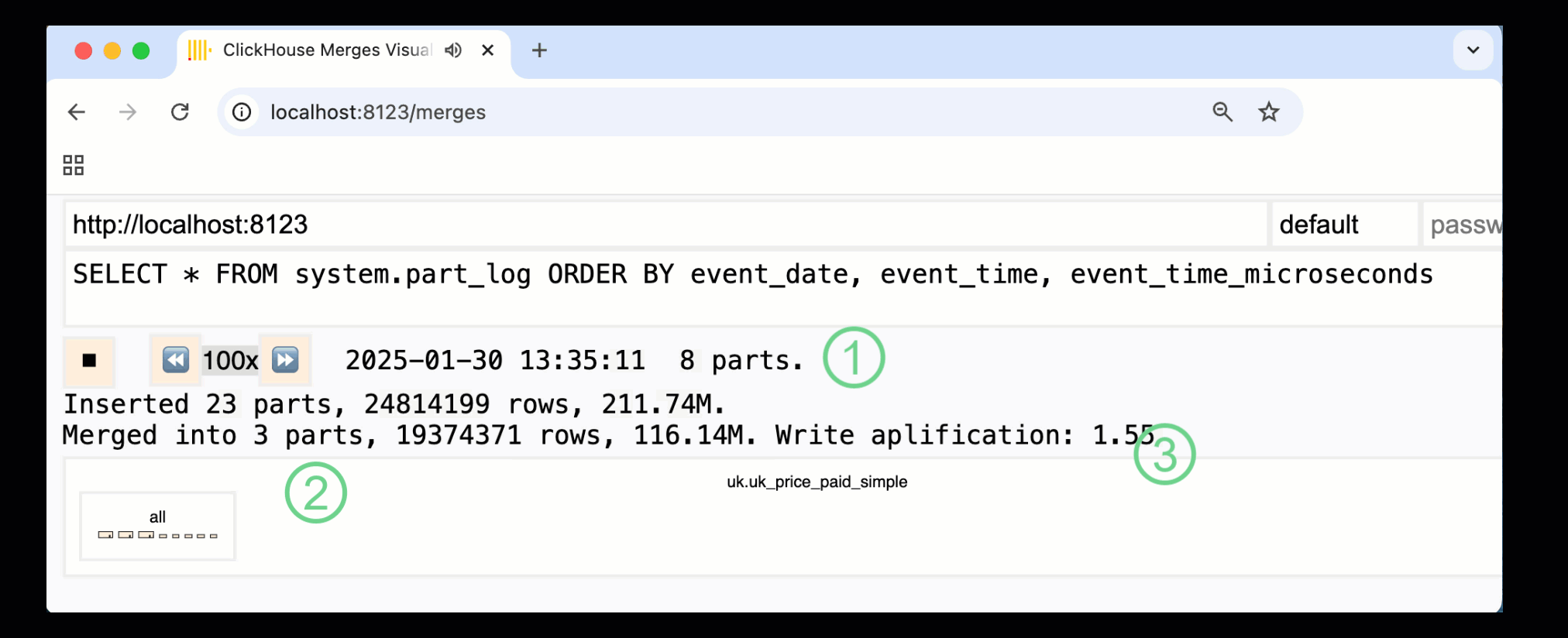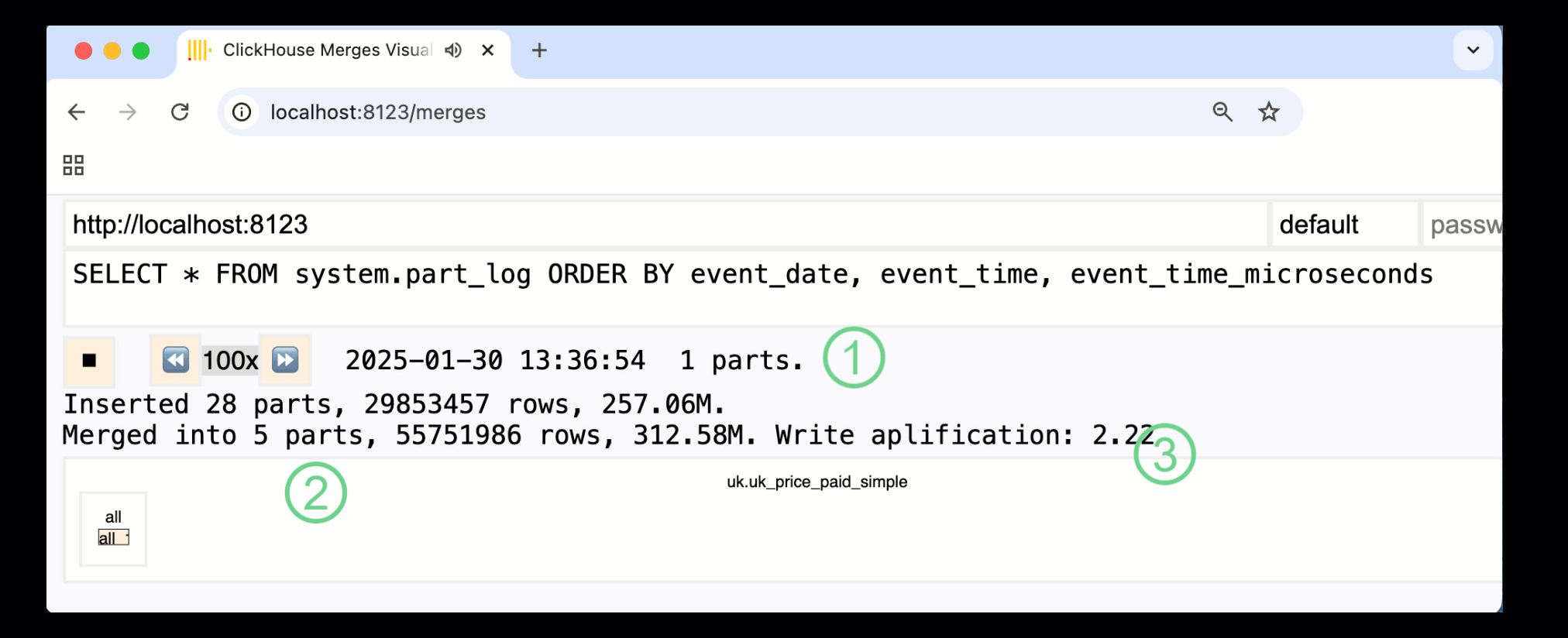
Показанная выше панель отражает весь процесс — от первоначальных вставок данных до итогового слияния в одну часть:
① Количество активных ^^частей^^.
② Слияния частей, визуально представленные в виде прямоугольников (размер соответствует размеру части).
Параллельные слияния
Один сервер ClickHouse использует несколько фоновых потоков слияния для выполнения параллельных слияний частей:
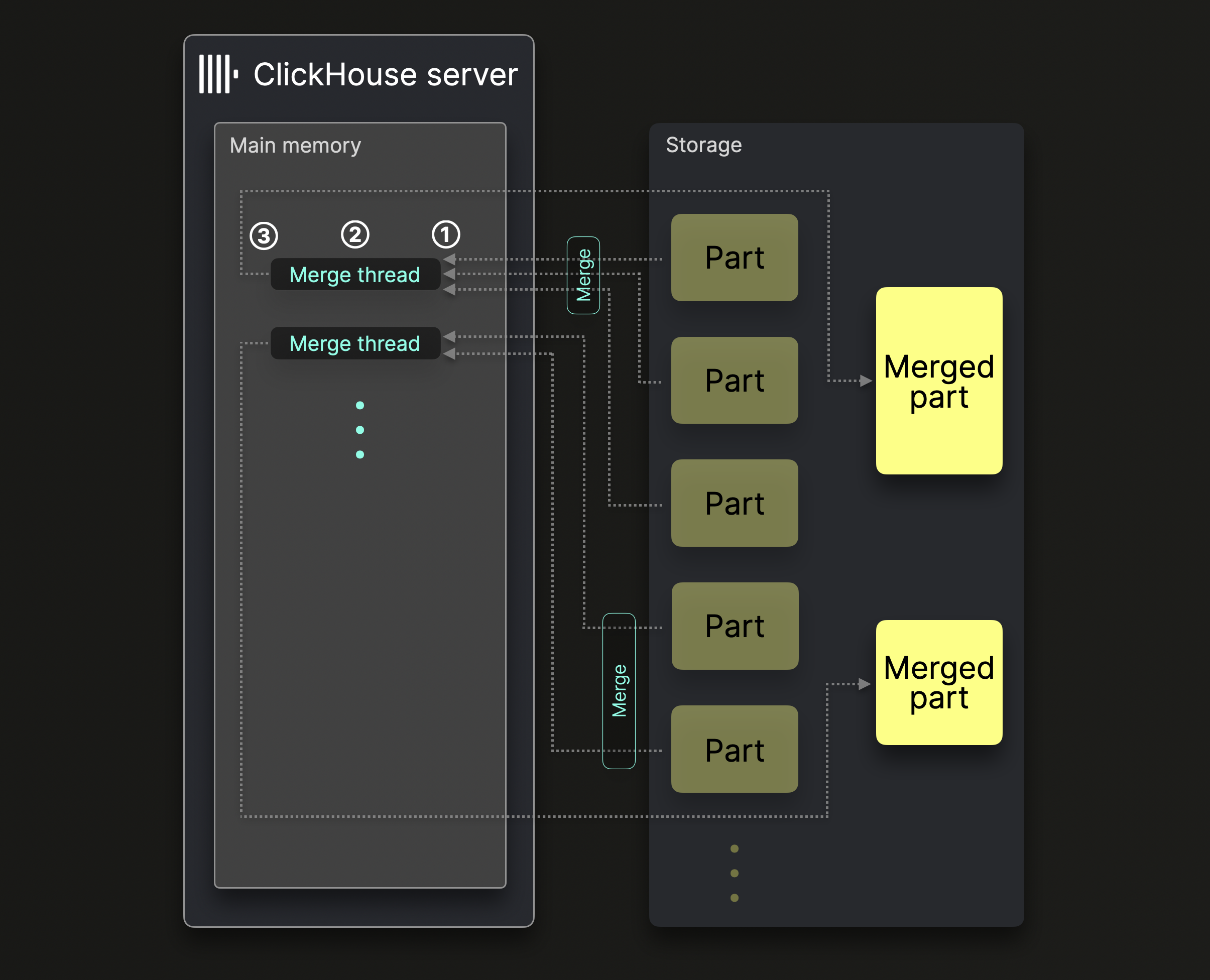
Каждый поток слияния выполняет цикл:
① Определить, какие ^^части^^ сливать следующими, и загрузить эти ^^части^^ в память.
② Слить ^^части^^ в памяти в одну более крупную часть.
③ Записать слитую часть на диск.
Перейти к ①.
Обратите внимание, что увеличение количества ядер CPU и объёма оперативной памяти позволяет повысить производительность фоновых слияний.
Слияния с оптимизированным использованием памяти
ClickHouse не обязательно загружает все ^^parts^^, подлежащие слиянию, в память одновременно, как показано в предыдущем примере. В зависимости от нескольких факторов и для снижения потребления памяти (ценой скорости слияния) так называемое вертикальное слияние загружает и сливает ^^parts^^ по блокам, а не за один проход.
Механика слияний
Диаграмма ниже иллюстрирует, как один фоновый поток слияния в ClickHouse сливает ^^части^^ (по умолчанию без вертикального слияния):
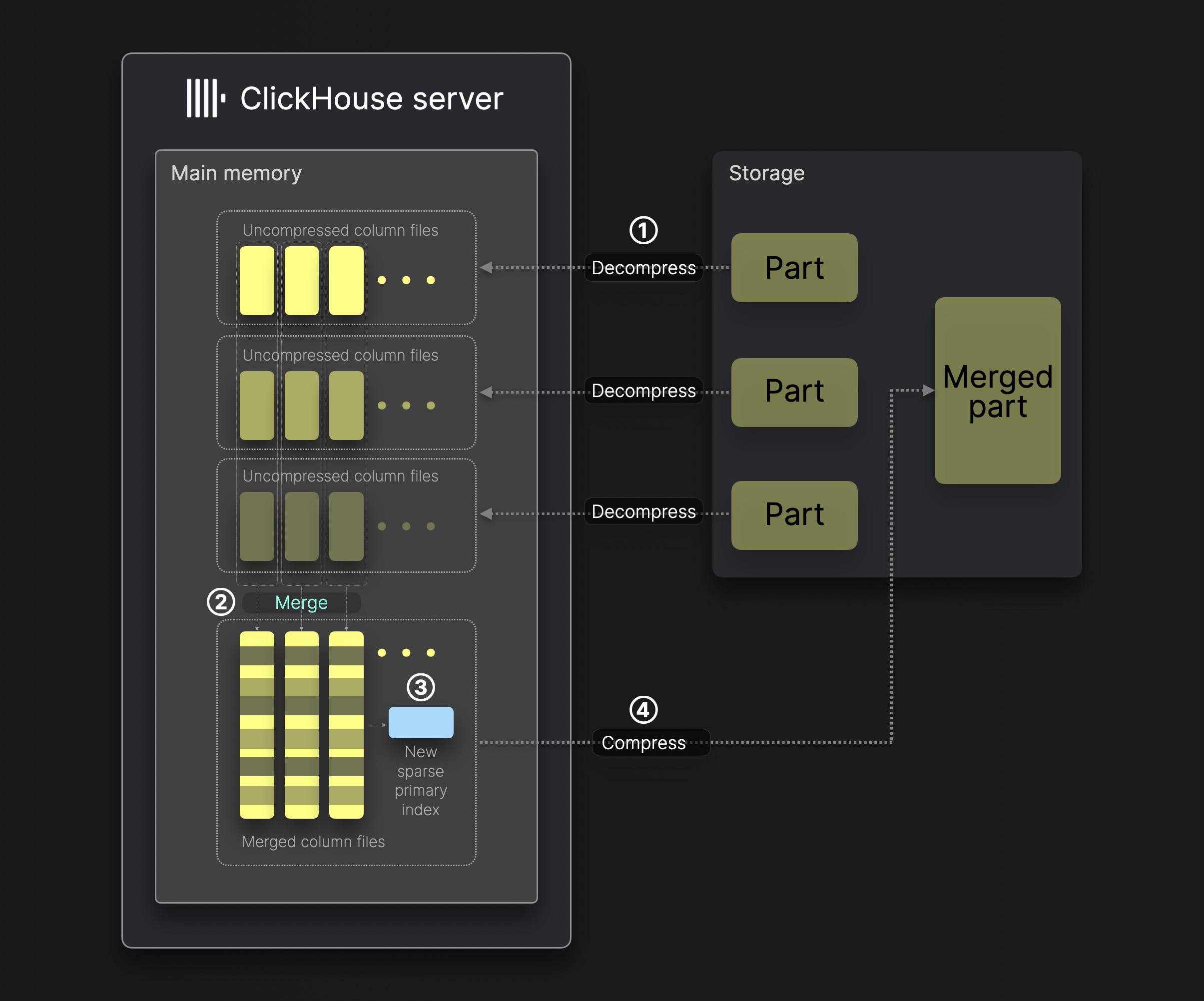
Слияние частей выполняется в несколько шагов:
① Декомпрессия и загрузка: Сжатые двоичные файлы столбцов из сливаемых ^^частей^^ распаковываются и загружаются в память.
② Слияние: Данные объединяются в более крупные файлы столбцов.
③ Индексация: Для объединённых файлов столбцов создаётся новый разрежённый первичный индекс.
④ Сжатие и сохранение: Новые файлы столбцов и индекс сжимаются и сохраняются в новом каталоге, представляющем объединённую часть данных.
Дополнительные метаданные в частях данных, такие как вторичные индексы пропуска данных, статистика по столбцам, контрольные суммы и min-max индексы, также заново создаются на основе объединённых файлов столбцов. Для простоты мы опустили эти детали.
Механика шага ② зависит от конкретного движка MergeTree, так как разные движки по-разному обрабатывают слияние. Например, строки могут агрегироваться или заменяться, если они устарели. Как уже упоминалось, такой подход выносит всю обработку данных во фоновые слияния, что позволяет обеспечить сверхбыстрые вставки, делая операции записи лёгкими и эффективными.
Далее мы кратко рассмотрим механику слияний конкретных движков из семейства ^^MergeTree^^.
Стандартные слияния
Диаграмма ниже показывает, как сливаются ^^части^^ в стандартной таблице MergeTree:
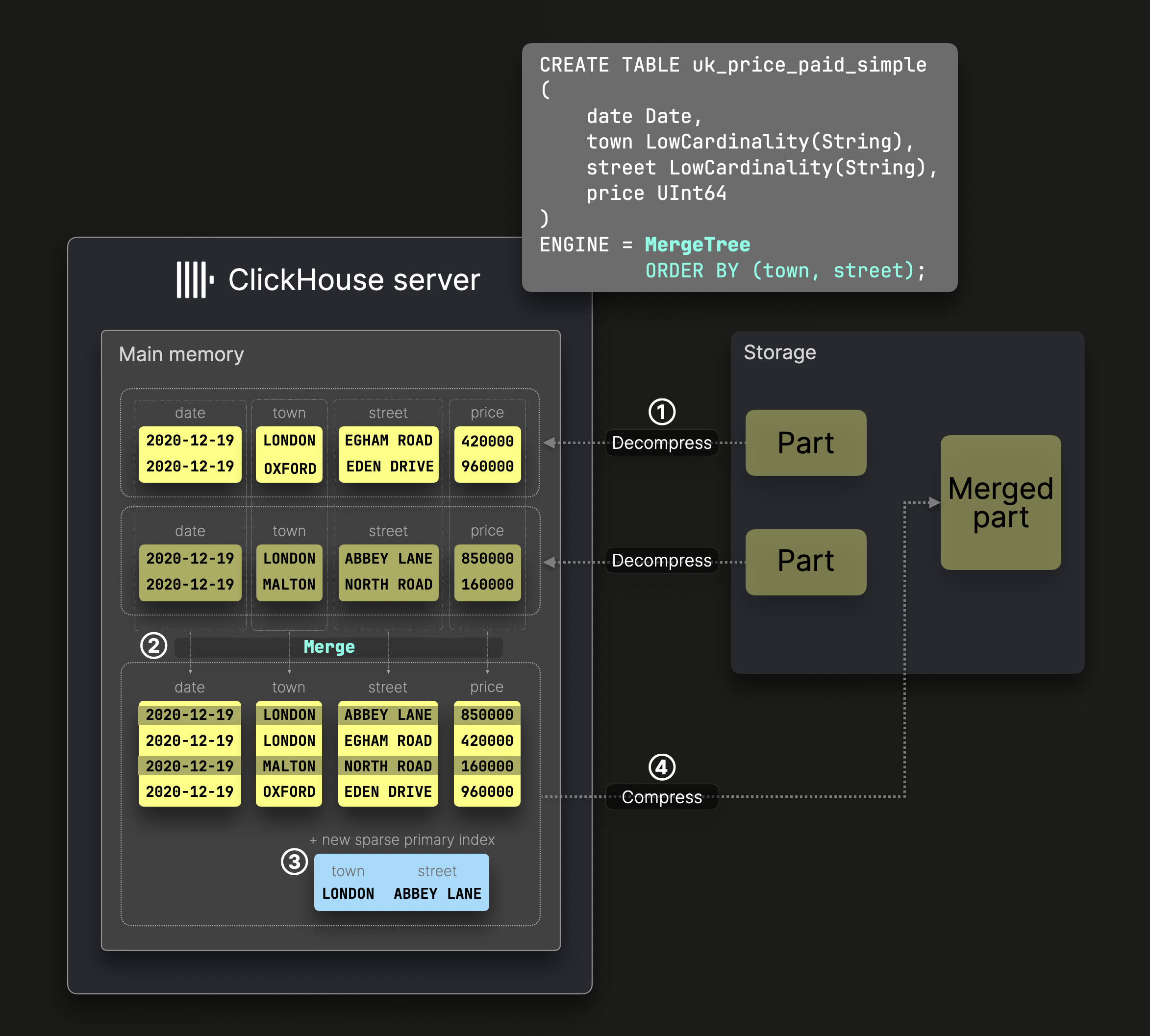
Оператор DDL на диаграмме выше создаёт таблицу MergeTree с ^^ключом сортировки^^ (town, street), что означает, что данные на диске отсортированы по этим столбцам и для них соответствующим образом генерируется разреженный первичный индекс.
① Распакованные, предварительно отсортированные столбцы таблицы ② сливаются с сохранением глобального порядка сортировки таблицы, определённого её ^^ключом сортировки^^, ③ создаётся новый разреженный первичный индекс, и ④ объединённые файлы столбцов и индекс сжимаются и сохраняются на диск как новая часть данных.
Замещающие слияния
Слияния частей в таблице ReplacingMergeTree работают аналогично стандартным слияниям, но при этом сохраняется только самая новая версия каждой строки, а устаревшие версии отбрасываются:
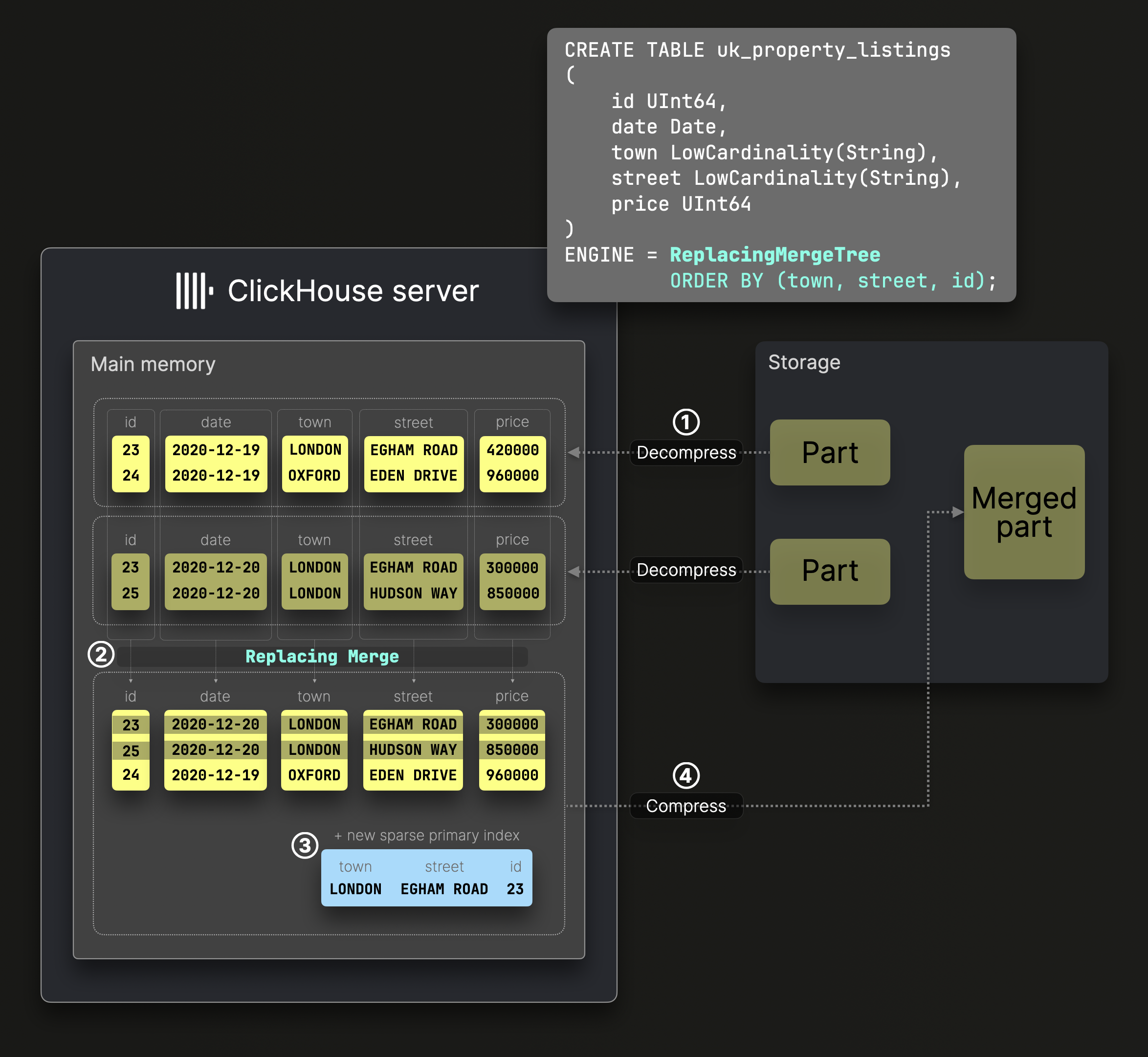
Оператор DDL на диаграмме выше создаёт таблицу ReplacingMergeTree с ^^ключом сортировки^^ (town, street, id). Это означает, что данные на диске отсортированы по этим столбцам, а для них генерируется разреженный первичный индекс.
Слияния ② выполняются аналогично тому, как это происходит в стандартной таблице MergeTree: объединяются декомпрессированные, предварительно отсортированные столбцы с сохранением глобального порядка сортировки.
Однако ReplacingMergeTree удаляет дубликаты строк с одинаковым ^^ключом сортировки^^, сохраняя только самую новую строку на основе временной метки создания содержащей её части.
Суммирующие слияния
Числовые данные автоматически суммируются во время слияния ^^частей^^ таблицы SummingMergeTree:
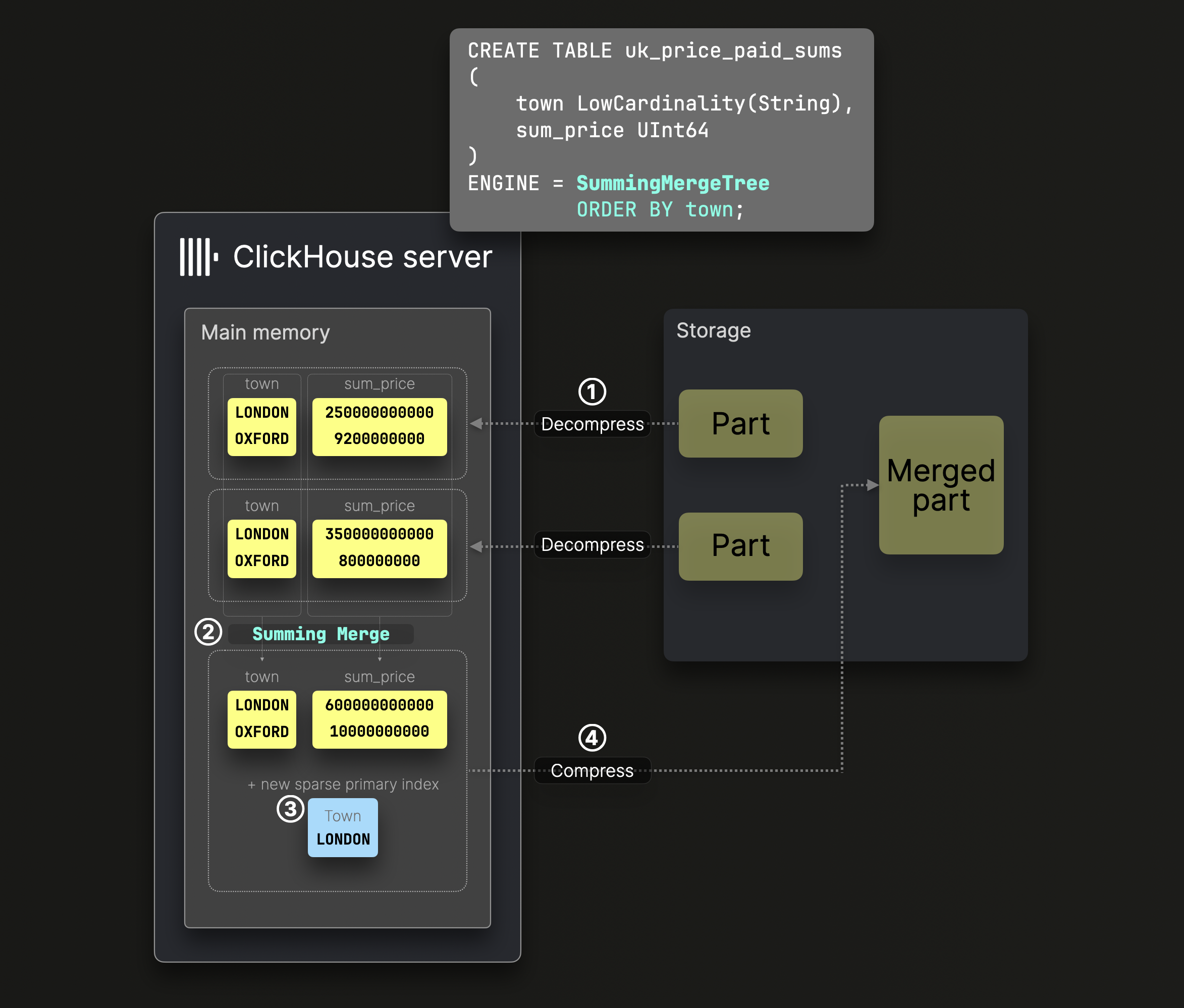
DDL-инструкция на диаграмме выше определяет таблицу SummingMergeTree с town в качестве ^^ключа сортировки^^, что означает, что данные на диске отсортированы по этому столбцу и соответственно создаётся разреженный первичный индекс.
На этапе слияния ② ClickHouse заменяет все строки с одним и тем же ^^ключом сортировки^^ одной строкой, суммируя значения числовых столбцов.
Агрегирующие слияния
Приведённый выше пример таблицы SummingMergeTree является специализированным вариантом таблицы AggregatingMergeTree, которая позволяет выполнять автоматическое инкрементальное преобразование данных, применяя любую из 90+ агрегатных функций во время слияния частей:
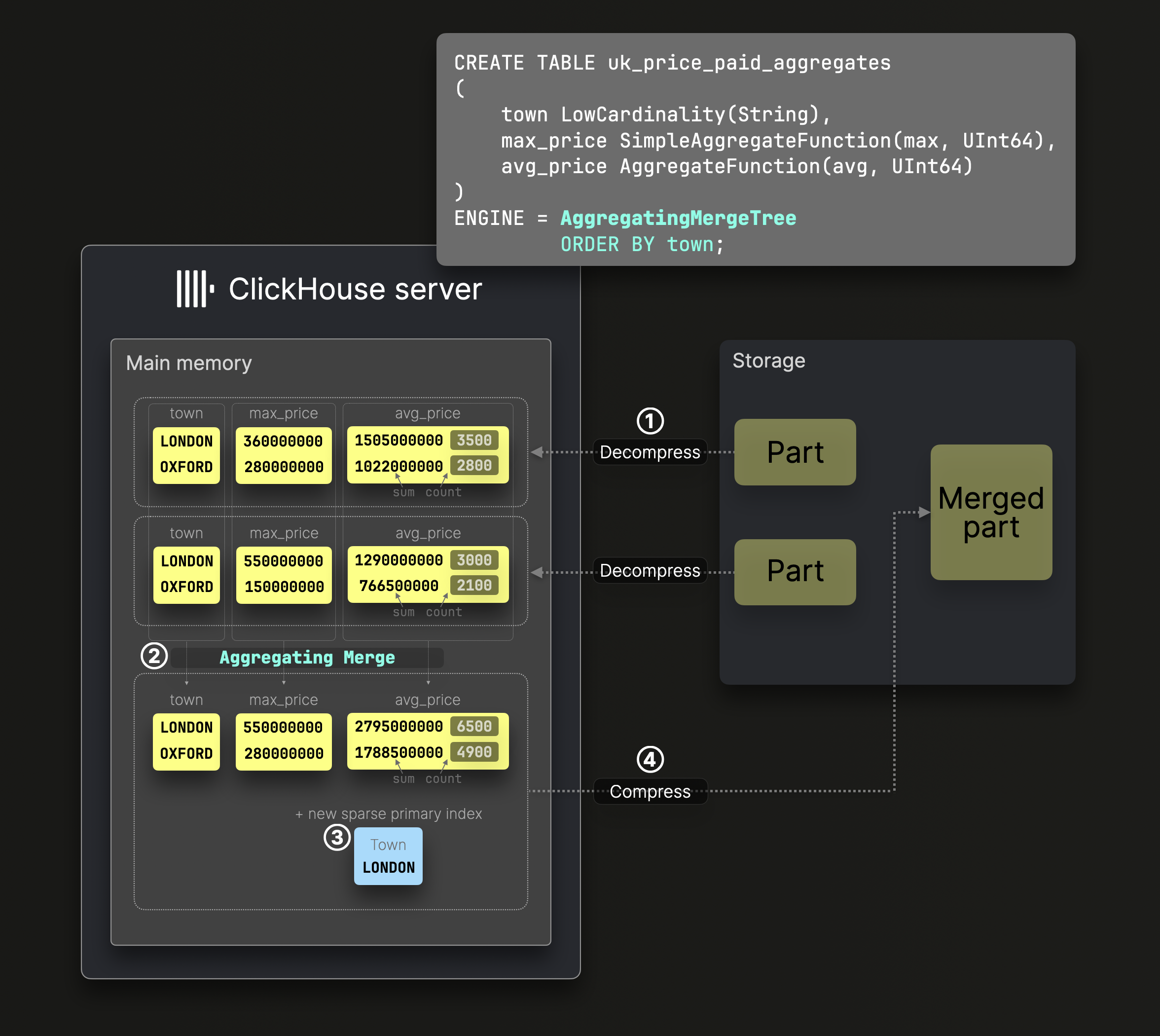
Оператор DDL на приведённой выше диаграмме создаёт таблицу AggregatingMergeTree с полем town в качестве ^^ключа сортировки^^, гарантируя упорядочивание данных по этому столбцу на диске и создание соответствующего разреженного первичного индекса.
Во время слияния ② ClickHouse заменяет все строки с одинаковым ^^ключом сортировки^^ одной строкой, в которой хранятся частичные состояния агрегации (например, sum и count для avg()). Эти состояния обеспечивают точные результаты за счёт инкрементальных фоновых слияний.
