Понимание выполнения запросов с помощью анализатора
ClickHouse обрабатывает запросы чрезвычайно быстро, но процесс их выполнения довольно сложен. Попробуем разобраться, как выполняется запрос SELECT. Чтобы проиллюстрировать это, добавим немного данных в таблицу ClickHouse:
CREATE TABLE session_events(
clientId UUID,
sessionId UUID,
pageId UUID,
timestamp DateTime,
type String
) ORDER BY (timestamp);
INSERT INTO session_events SELECT * FROM generateRandom('clientId UUID,
sessionId UUID,
pageId UUID,
timestamp DateTime,
type Enum(\'type1\', \'type2\')', 1, 10, 2) LIMIT 1000;
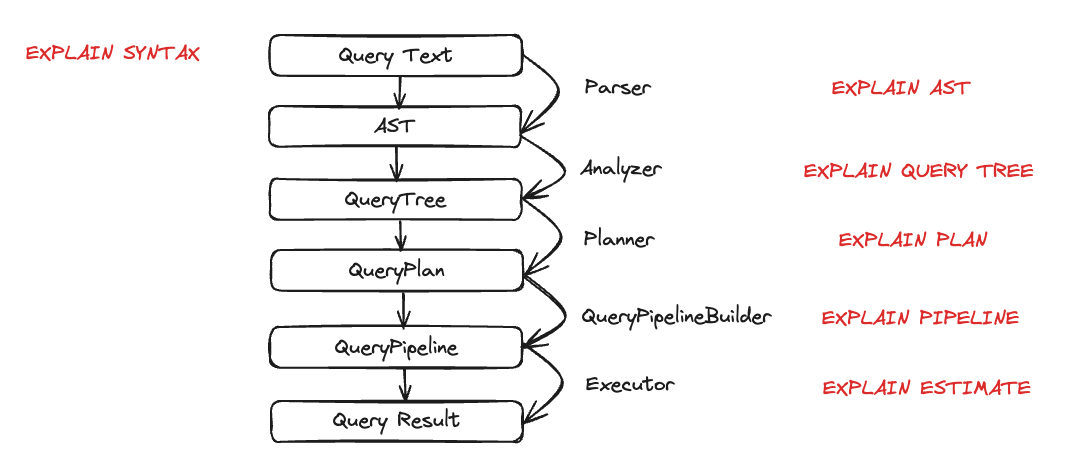
Теперь, когда в ClickHouse есть некоторые данные, мы хотим выполнить несколько запросов и разобраться, как они исполняются. Выполнение запроса разбивается на множество этапов. Каждый этап выполнения запроса можно проанализировать и диагностировать с помощью соответствующего запроса EXPLAIN. Эти этапы показаны на схеме ниже:
Давайте посмотрим на каждый объект в действии во время выполнения запроса. Мы возьмём несколько запросов и затем рассмотрим их с помощью оператора EXPLAIN.
Парсер
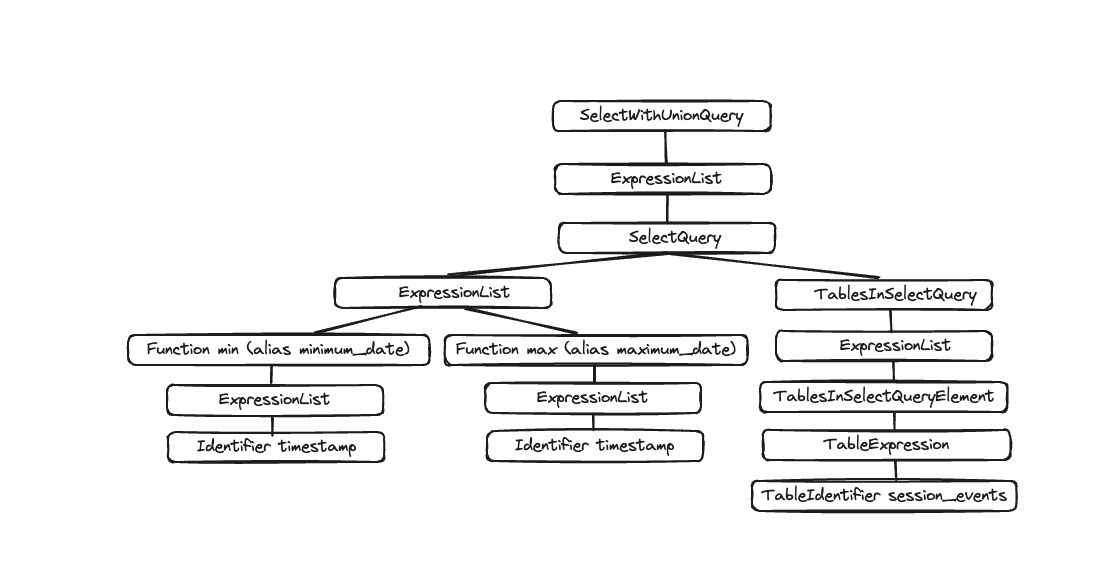
Задача парсера — преобразовать текст запроса в AST (Abstract Syntax Tree, абстрактное синтаксическое дерево). Этот шаг можно визуализировать с помощью EXPLAIN AST:
EXPLAIN AST SELECT min(timestamp), max(timestamp) FROM session_events;
┌─explain────────────────────────────────────────────┐
│ SelectWithUnionQuery (children 1) │
│ ExpressionList (children 1) │
│ SelectQuery (children 2) │
│ ExpressionList (children 2) │
│ Function min (alias minimum_date) (children 1) │
│ ExpressionList (children 1) │
│ Identifier timestamp │
│ Function max (alias maximum_date) (children 1) │
│ ExpressionList (children 1) │
│ Identifier timestamp │
│ TablesInSelectQuery (children 1) │
│ TablesInSelectQueryElement (children 1) │
│ TableExpression (children 1) │
│ TableIdentifier session_events │
└────────────────────────────────────────────────────┘
Результатом является абстрактное синтаксическое дерево (AST), которое можно визуализировать как показано ниже:
Каждый узел имеет соответствующие дочерние элементы, а дерево целиком представляет структуру вашего запроса. Это логическая структура, помогающая при обработке запроса. С точки зрения конечного пользователя (если только его не интересует выполнение запроса) она не особенно полезна; этот инструмент в основном используется разработчиками.
Анализатор
В ClickHouse в настоящее время есть две архитектуры анализатора. Вы можете использовать старую архитектуру, установив enable_analyzer=0. Новая архитектура включена по умолчанию. Здесь мы будем описывать только новую архитектуру, поскольку старая будет признана устаревшей, как только новый анализатор станет общедоступным.
Примечание
Новая архитектура должна обеспечить более удобную основу для дальнейшего повышения производительности ClickHouse. Однако, поскольку это базовый компонент этапов обработки запроса, она также может оказывать негативное влияние на некоторые запросы, и существуют известные несовместимости. Вы можете вернуться к старому анализатору, изменив настройку enable_analyzer на уровне запроса или пользователя.
Анализатор — это важный этап выполнения запроса. Он принимает AST и преобразует его в дерево запроса. Основное преимущество дерева запроса по сравнению с AST заключается в том, что множество компонентов будет разрешено, например хранилище. Мы также знаем, из какой таблицы читать данные, разрешены алиасы, и дерево знает различные используемые типы данных. Обладая всеми этими преимуществами, анализатор может применять оптимизации. Эти оптимизации реализуются с помощью «проходов». Каждый проход ищет свои варианты оптимизаций. Вы можете увидеть все проходы здесь; давайте посмотрим на это на практике на примере нашего предыдущего запроса:
EXPLAIN QUERY TREE passes=0 SELECT min(timestamp) AS minimum_date, max(timestamp) AS maximum_date FROM session_events SETTINGS allow_experimental_analyzer=1;
┌─explain────────────────────────────────────────────────────────────────────────────────┐
│ QUERY id: 0 │
│ PROJECTION │
│ LIST id: 1, nodes: 2 │
│ FUNCTION id: 2, alias: minimum_date, function_name: min, function_type: ordinary │
│ ARGUMENTS │
│ LIST id: 3, nodes: 1 │
│ IDENTIFIER id: 4, identifier: timestamp │
│ FUNCTION id: 5, alias: maximum_date, function_name: max, function_type: ordinary │
│ ARGUMENTS │
│ LIST id: 6, nodes: 1 │
│ IDENTIFIER id: 7, identifier: timestamp │
│ JOIN TREE │
│ IDENTIFIER id: 8, identifier: session_events │
│ SETTINGS allow_experimental_analyzer=1 │
└────────────────────────────────────────────────────────────────────────────────────────┘
EXPLAIN QUERY TREE passes=20 SELECT min(timestamp) AS minimum_date, max(timestamp) AS maximum_date FROM session_events SETTINGS allow_experimental_analyzer=1;
┌─explain───────────────────────────────────────────────────────────────────────────────────┐
│ QUERY id: 0 │
│ PROJECTION COLUMNS │
│ minimum_date DateTime │
│ maximum_date DateTime │
│ PROJECTION │
│ LIST id: 1, nodes: 2 │
│ FUNCTION id: 2, function_name: min, function_type: aggregate, result_type: DateTime │
│ ARGUMENTS │
│ LIST id: 3, nodes: 1 │
│ COLUMN id: 4, column_name: timestamp, result_type: DateTime, source_id: 5 │
│ FUNCTION id: 6, function_name: max, function_type: aggregate, result_type: DateTime │
│ ARGUMENTS │
│ LIST id: 7, nodes: 1 │
│ COLUMN id: 4, column_name: timestamp, result_type: DateTime, source_id: 5 │
│ JOIN TREE │
│ TABLE id: 5, alias: __table1, table_name: default.session_events │
│ SETTINGS allow_experimental_analyzer=1 │
└───────────────────────────────────────────────────────────────────────────────────────────┘
Между двумя выполнениями вы можете увидеть, как разрешаются псевдонимы и проекции.
Планировщик
Планировщик принимает дерево запроса и на его основе строит план запроса. Дерево запроса описывает, что мы хотим сделать с конкретным запросом, а план запроса описывает, как мы это сделаем. Дополнительные оптимизации выполняются на этапе построения плана запроса. Вы можете использовать EXPLAIN PLAN или EXPLAIN, чтобы посмотреть план запроса (EXPLAIN выполнит EXPLAIN PLAN).
EXPLAIN PLAN WITH
(
SELECT count(*)
FROM session_events
) AS total_rows
SELECT type, min(timestamp) AS minimum_date, max(timestamp) AS maximum_date, count(*) /total_rows * 100 AS percentage FROM session_events GROUP BY type
┌─explain──────────────────────────────────────────┐
│ Expression ((Projection + Before ORDER BY)) │
│ Aggregating │
│ Expression (Before GROUP BY) │
│ ReadFromMergeTree (default.session_events) │
└──────────────────────────────────────────────────┘
Хотя это уже даёт нам какую-то информацию, мы можем получить и больше. Например, нам может понадобиться узнать имя столбца, на основе которого нужны проекции. Для этого можно добавить заголовок к запросу:
EXPLAIN header = 1
WITH (
SELECT count(*)
FROM session_events
) AS total_rows
SELECT
type,
min(timestamp) AS minimum_date,
max(timestamp) AS maximum_date,
(count(*) / total_rows) * 100 AS percentage
FROM session_events
GROUP BY type
┌─explain──────────────────────────────────────────┐
│ Expression ((Projection + Before ORDER BY)) │
│ Header: type String │
│ minimum_date DateTime │
│ maximum_date DateTime │
│ percentage Nullable(Float64) │
│ Aggregating │
│ Header: type String │
│ min(timestamp) DateTime │
│ max(timestamp) DateTime │
│ count() UInt64 │
│ Expression (Before GROUP BY) │
│ Header: timestamp DateTime │
│ type String │
│ ReadFromMergeTree (default.session_events) │
│ Header: timestamp DateTime │
│ type String │
└──────────────────────────────────────────────────┘
Теперь вы знаете названия столбцов, которые нужно создать для последней проекции (minimum_date, maximum_date и percentage), но, возможно, вы также захотите получить подробные сведения обо всех действиях, которые должны быть выполнены. Для этого установите actions=1.
EXPLAIN actions = 1
WITH (
SELECT count(*)
FROM session_events
) AS total_rows
SELECT
type,
min(timestamp) AS minimum_date,
max(timestamp) AS maximum_date,
(count(*) / total_rows) * 100 AS percentage
FROM session_events
GROUP BY type
┌─explain────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ Выражение ((Projection + Before ORDER BY)) │
│ Действия: INPUT :: 0 -> type String : 0 │
│ INPUT : 1 -> min(timestamp) DateTime : 1 │
│ INPUT : 2 -> max(timestamp) DateTime : 2 │
│ INPUT : 3 -> count() UInt64 : 3 │
│ COLUMN Const(Nullable(UInt64)) -> total_rows Nullable(UInt64) : 4 │
│ COLUMN Const(UInt8) -> 100 UInt8 : 5 │
│ ALIAS min(timestamp) :: 1 -> minimum_date DateTime : 6 │
│ ALIAS max(timestamp) :: 2 -> maximum_date DateTime : 1 │
│ FUNCTION divide(count() :: 3, total_rows :: 4) -> divide(count(), total_rows) Nullable(Float64) : 2 │
│ FUNCTION multiply(divide(count(), total_rows) :: 2, 100 :: 5) -> multiply(divide(count(), total_rows), 100) Nullable(Float64) : 4 │
│ ALIAS multiply(divide(count(), total_rows), 100) :: 4 -> percentage Nullable(Float64) : 5 │
│ Позиции: 0 6 1 5 │
│ Aggregating │
│ Ключи: type │
│ Агрегаты: │
│ min(timestamp) │
│ Функция: min(DateTime) → DateTime │
│ Аргументы: timestamp │
│ max(timestamp) │
│ Функция: max(DateTime) → DateTime │
│ Аргументы: timestamp │
│ count() │
│ Функция: count() → UInt64 │
│ Аргументы: нет │
│ Пропуск слияния: 0 │
│ Выражение (Before GROUP BY) │
│ Действия: INPUT :: 0 -> timestamp DateTime : 0 │
│ INPUT :: 1 -> type String : 1 │
│ Позиции: 0 1 │
│ ReadFromMergeTree (default.session_events) │
│ Тип чтения: Default │
│ Частей: 1 │
│ Гранул: 1 │
└────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
Теперь вы можете видеть все входные данные, функции, псевдонимы и типы данных, которые используются. Некоторые оптимизации, которые будет применять планировщик, можно посмотреть [здесь](https://github.com/ClickHouse/ClickHouse/blob/master/src/Processors/QueryPlan/Optimizations/Optimizations.h).
Конвейер запроса
Конвейер запроса генерируется из плана запроса. Конвейер запроса очень похож на план запроса, но представляет собой не дерево, а граф. Он показывает, как ClickHouse будет выполнять запрос и какие ресурсы будут использоваться. Анализ конвейера запроса очень полезен для выявления узких мест с точки зрения ввода/вывода. Возьмём наш предыдущий запрос и посмотрим на выполнение конвейера запроса:
EXPLAIN PIPELINE
WITH (
SELECT count(*)
FROM session_events
) AS total_rows
SELECT
type,
min(timestamp) AS minimum_date,
max(timestamp) AS maximum_date,
(count(*) / total_rows) * 100 AS percentage
FROM session_events
GROUP BY type;
┌─explain────────────────────────────────────────────────────────────────────┐
│ (Expression) │
│ ExpressionTransform × 2 │
│ (Aggregating) │
│ Resize 1 → 2 │
│ AggregatingTransform │
│ (Expression) │
│ ExpressionTransform │
│ (ReadFromMergeTree) │
│ MergeTreeSelect(pool: PrefetchedReadPool, algorithm: Thread) 0 → 1 │
└────────────────────────────────────────────────────────────────────────────┘
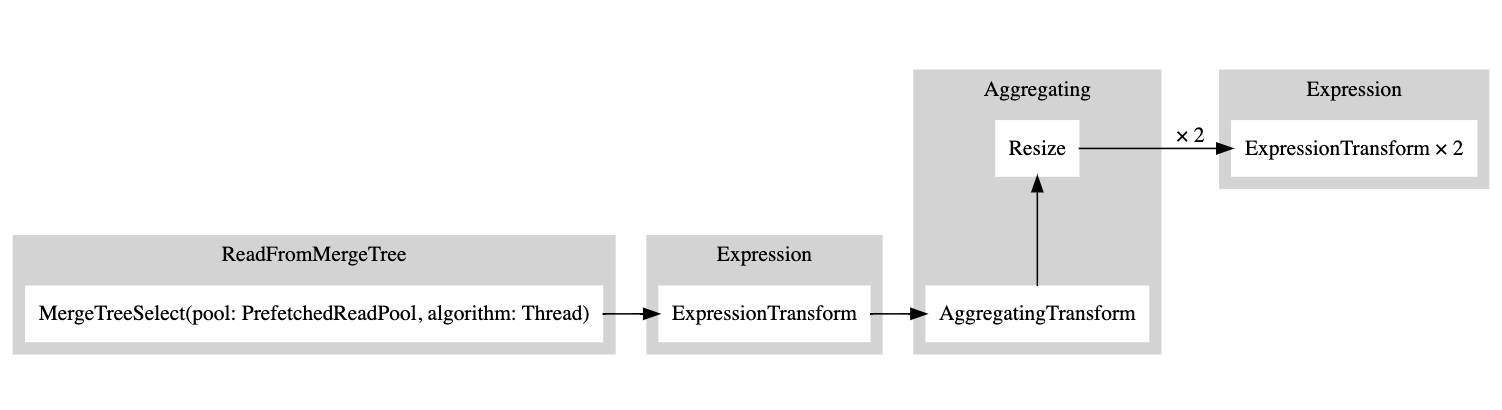
В скобках указан шаг плана запроса, а рядом — процессор. Это полезная информация, но, учитывая, что перед нами граф, было бы удобно визуализировать его соответственно. У нас есть настройка graph, которую можно установить в 1 и задать TSV в качестве формата вывода:
EXPLAIN PIPELINE graph=1 WITH
(
SELECT count(*)
FROM session_events
) AS total_rows
SELECT type, min(timestamp) AS minimum_date, max(timestamp) AS maximum_date, count(*) /total_rows * 100 AS percentage FROM session_events GROUP BY type FORMAT TSV;
digraph
{
rankdir="LR";
{ node [shape = rect]
subgraph cluster_0 {
label ="Выражение";
style=filled;
color=lightgrey;
node [style=filled,color=white];
{ rank = same;
n5 [label="ExpressionTransform × 2"];
}
}
subgraph cluster_1 {
label ="Агрегирование";
style=filled;
color=lightgrey;
node [style=filled,color=white];
{ rank = same;
n3 [label="AggregatingTransform"];
n4 [label="Resize"];
}
}
subgraph cluster_2 {
label ="Выражение";
style=filled;
color=lightgrey;
node [style=filled,color=white];
{ rank = same;
n2 [label="ExpressionTransform"];
}
}
subgraph cluster_3 {
label ="ЧтениеИзMergeTree";
style=filled;
color=lightgrey;
node [style=filled,color=white];
{ rank = same;
n1 [label="MergeTreeSelect(pool: PrefetchedReadPool, algorithm: Thread)"];
}
}
}
n3 -> n4 [label=""];
n4 -> n5 [label="× 2"];
n2 -> n3 [label=""];
n1 -> n2 [label=""];
}
Затем вы можете скопировать этот вывод и вставить его сюда, после чего будет построен следующий граф:
Белый прямоугольник соответствует узлу пайплайна, серый прямоугольник — шагам плана запроса, а x, за которым следует число, обозначает количество используемых входов/выходов. Если вы не хотите видеть граф в компактном виде, вы всегда можете добавить compact=0:
EXPLAIN PIPELINE graph = 1, compact = 0
WITH (
SELECT count(*)
FROM session_events
) AS total_rows
SELECT
type,
min(timestamp) AS minimum_date,
max(timestamp) AS maximum_date,
(count(*) / total_rows) * 100 AS percentage
FROM session_events
GROUP BY type
FORMAT TSV
digraph
{
rankdir="LR";
{ node [shape = rect]
n0[label="MergeTreeSelect(pool: PrefetchedReadPool, algorithm: Thread)"];
n1[label="ExpressionTransform"];
n2[label="AggregatingTransform"];
n3[label="Resize"];
n4[label="ExpressionTransform"];
n5[label="ExpressionTransform"];
}
n0 -> n1;
n1 -> n2;
n2 -> n3;
n3 -> n4;
n3 -> n5;
}
Почему ClickHouse не читает из таблицы, используя несколько потоков? Попробуем добавить больше данных в таблицу:
INSERT INTO session_events SELECT * FROM generateRandom('clientId UUID,
sessionId UUID,
pageId UUID,
timestamp DateTime,
type Enum(\'type1\', \'type2\')', 1, 10, 2) LIMIT 1000000;
Теперь снова выполним запрос EXPLAIN:
EXPLAIN PIPELINE graph = 1, compact = 0
WITH (
SELECT count(*)
FROM session_events
) AS total_rows
SELECT
type,
min(timestamp) AS minimum_date,
max(timestamp) AS maximum_date,
(count(*) / total_rows) * 100 AS percentage
FROM session_events
GROUP BY type
FORMAT TSV
digraph
{
rankdir="LR";
{ node [shape = rect]
n0[label="MergeTreeSelect(pool: PrefetchedReadPool, algorithm: Thread)"];
n1[label="MergeTreeSelect(pool: PrefetchedReadPool, algorithm: Thread)"];
n2[label="ExpressionTransform"];
n3[label="ExpressionTransform"];
n4[label="StrictResize"];
n5[label="AggregatingTransform"];
n6[label="AggregatingTransform"];
n7[label="Resize"];
n8[label="ExpressionTransform"];
n9[label="ExpressionTransform"];
}
n0 -> n2;
n1 -> n3;
n2 -> n4;
n3 -> n4;
n4 -> n5;
n4 -> n6;
n5 -> n7;
n6 -> n7;
n7 -> n8;
n7 -> n9;
}
Таким образом, исполнитель запроса решил не параллелизировать операции, поскольку объем данных был недостаточно большим. После того как было добавлено больше строк, исполнитель запроса решил использовать несколько потоков, как видно на графике.
Исполнитель
На последнем шаге запрос выполняется исполнителем. Он берёт конвейер запроса и запускает его. Существуют разные типы исполнителей в зависимости от того, выполняете ли вы SELECT, INSERT или INSERT SELECT.