Словарь
Словарь в ClickHouse предоставляет хранящееся в памяти представление данных в формате key-value из различных внутренних и внешних источников, оптимизированное для операций поиска с крайне низкой задержкой.
Словари полезны для:
- Повышения производительности запросов, особенно при использовании с операциями
JOIN - Обогащения поступающих данных «на лету» без замедления процесса ингестии
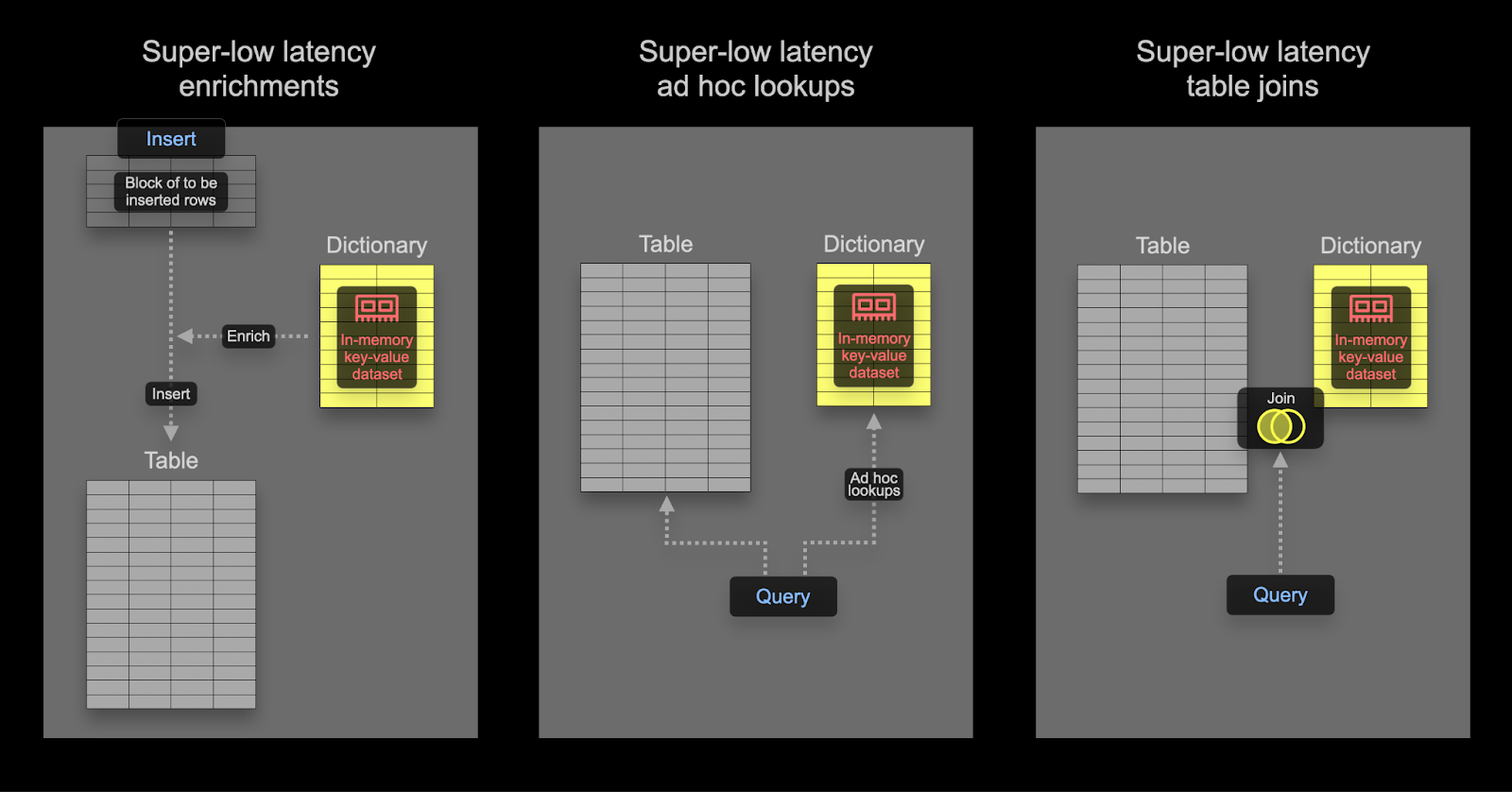
Ускорение соединений с использованием словаря
Словари можно использовать для ускорения определённого типа операции JOIN: типа LEFT ANY, когда ключ соединения совпадает с ключевым атрибутом подлежащего хранилища ключ-значение.
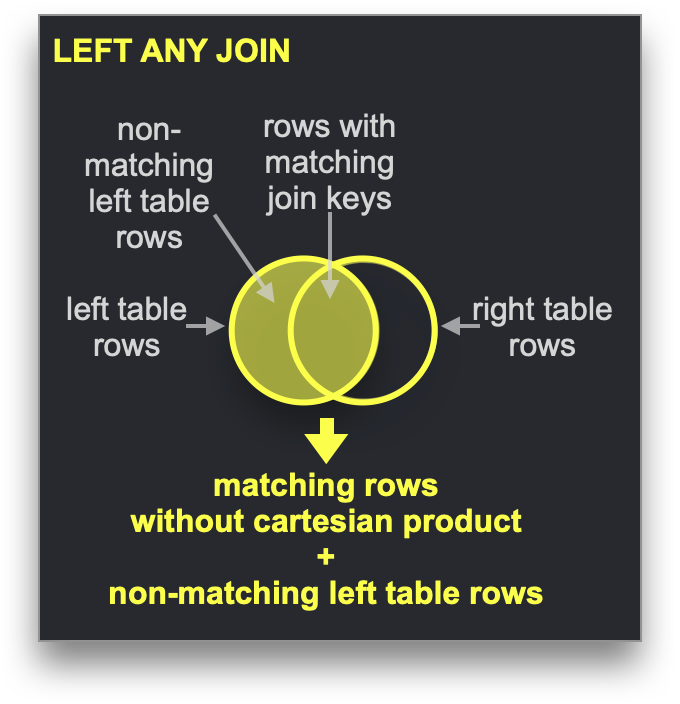
В таком случае ClickHouse может использовать словарь для выполнения Direct Join. Это самый быстрый алгоритм соединения в ClickHouse, применимый, когда базовый движок таблицы для таблицы справа поддерживает запросы к хранилищу ключ-значение с низкой задержкой. В ClickHouse есть три движка таблиц, которые это поддерживают: Join (по сути, предварительно вычисленная хеш-таблица), EmbeddedRocksDB и Dictionary. Мы опишем подход, основанный на словаре, но механика одинакова для всех трёх движков.
Алгоритм Direct Join требует, чтобы правая таблица опиралась на словарь, благодаря чему данные для соединения из этой таблицы уже находятся в памяти в виде структуры данных хранилища ключ-значение с низкой задержкой.
Пример
Используя датасет Stack Overflow, ответим на вопрос: Какой пост, касающийся SQL, является самым спорным на Hacker News?
Мы будем считать пост спорным, если у него схожее количество голосов «за» и «против». Мы вычислим абсолютную разницу между ними: чем ближе значение к 0, тем сильнее спорность. Также будем считать, что у поста должно быть как минимум 10 голосов «за» и 10 голосов «против» — посты, за которые почти не голосуют, вряд ли можно считать спорными.
При нормализованных данных этот запрос требует JOIN с использованием таблиц posts и votes:
Используйте меньшие наборы данных в правой части
JOIN: Этот запрос может показаться более многословным, чем требуется, поскольку фильтрация поPostIdвыполняется как во внешнем, так и во вложенном запросе. Это оптимизация производительности, которая обеспечивает быстрое время ответа. Для оптимальной производительности всегда следите за тем, чтобы правая сторонаJOINбыла меньшим набором данных и оставалась как можно меньше. Советы по оптимизации производительности JOIN и обзору доступных алгоритмов приведены в этой серии статей в блоге.
Хотя этот запрос и работает быстро, он требует от нас аккуратного использования JOIN, чтобы добиться хорошей производительности. В идеале мы бы просто отфильтровали записи до тех, которые содержат «SQL», прежде чем смотреть на значения UpVote и DownVote для подмножества блогов, чтобы вычислить нашу метрику.
Применение словаря
Чтобы продемонстрировать эти концепции, мы используем словарь для наших данных о голосовании. Поскольку словари обычно хранятся в памяти (ssd_cache — исключение), пользователям следует учитывать объём данных. Проверим размер нашей таблицы votes:
Данные будут храниться в нашем словаре без сжатия, поэтому нам потребуется как минимум 4 ГБ памяти, если бы мы собирались хранить все столбцы (мы не будем) в словаре. Словарь будет реплицирован по нашему кластеру, поэтому этот объём памяти должен быть зарезервирован на каждый узел.
В примере ниже данные для нашего словаря поступают из таблицы ClickHouse. Хотя это и является наиболее распространённым источником словарей, поддерживается ряд источников, включая файлы, HTTP и базы данных, в том числе Postgres. Как мы покажем, словари могут автоматически обновляться, что делает их идеальным способом обеспечить доступность небольших наборов данных, подверженных частым изменениям, для прямых JOIN.
Для нашего словаря требуется первичный ключ, по которому будут выполняться обращения. Концептуально это идентично первичному ключу транзакционной базы данных и должно быть уникальным. Наш запрос выше требует обращения по ключу соединения — PostId. Словарь, в свою очередь, должен быть заполнен суммарными значениями голосов «за» и «против» по PostId из нашей таблицы votes. Ниже приведён запрос для получения данных этого словаря:
Для создания нашего словаря используем следующий DDL — обратите внимание на использование приведённого выше запроса:
В самоуправляемой OSS-установке указанную выше команду нужно выполнить на всех узлах. В ClickHouse Cloud словарь будет автоматически реплицирован на все узлы. Эта команда была выполнена на узле ClickHouse Cloud с 64 ГБ ОЗУ, загрузка заняла 36 секунд.
Чтобы подтвердить объём памяти, потребляемый нашим словарём:
Получить количество голосов «за» и «против» для конкретного PostId теперь можно с помощью простой функции dictGet. Ниже мы получаем значения для поста 11227902:
Этот запрос не только гораздо проще, но и более чем в два раза быстрее! Его можно дополнительно оптимизировать, загружая в словарь только посты с более чем 10 голосами «за» и «против» и сохраняя только предварительно вычисленное значение степени спорности.
Обогащение при выполнении запроса
Словари можно использовать для поиска значений при выполнении запроса. Эти значения могут возвращаться в результатах или использоваться в агрегациях. Предположим, мы создаём словарь для отображения идентификаторов пользователей на их местоположения:
Мы можем использовать этот словарь для обогащения результатов по постам:
Аналогично нашему примеру выше с JOIN, мы можем использовать тот же словарь, чтобы эффективно определить, откуда происходит большинство постов:
Обогащение на этапе вставки (index time)
В приведённом выше примере мы использовали словарь на этапе выполнения запроса, чтобы убрать операцию JOIN. Словари также можно использовать для обогащения строк на этапе вставки. Это обычно целесообразно, если значение для обогащения не меняется и существует во внешнем источнике, который можно использовать для заполнения словаря. В этом случае обогащение строки на этапе вставки позволяет избежать поиска в словаре во время выполнения запроса.
Предположим, что Location пользователя в Stack Overflow никогда не меняется (в реальности это не так), а именно столбец Location таблицы users. Допустим, мы хотим выполнить аналитический запрос к таблице posts по местоположению. В ней содержится столбец UserId.
Словарь задаёт соответствие между идентификатором пользователя и его местоположением, опираясь на таблицу users:
Мы исключаем пользователей с
Id < 0, что позволяет нам использовать тип словаряHashed. Пользователи сId < 0являются системными пользователями.
Чтобы использовать этот словарь при вставке данных в таблицу posts, нам нужно изменить схему:
В приведённом выше примере Location объявлен как столбец типа MATERIALIZED. Это означает, что значение может быть указано в запросе INSERT и при этом всегда будет вычислено.
ClickHouse также поддерживает
DEFAULTстолбцы (когда значение может быть вставлено или вычислено, если оно не указано).
Чтобы заполнить таблицу, мы можем использовать привычный INSERT INTO SELECT из S3:
Теперь мы можем узнать название места, из которого поступает большинство записей:
Расширенные темы о словарях
Выбор LAYOUT словаря
Клауза LAYOUT управляет внутренней структурой данных словаря. Существует несколько вариантов, описанных здесь. Некоторые рекомендации по выбору подходящего LAYOUT можно найти здесь.
Обновление словарей
Мы указали для словаря LIFETIME со значением MIN 600 MAX 900. LIFETIME — это интервал обновления словаря; в данном случае значения приводят к периодической перезагрузке через случайный интервал между 600 и 900 секундами. Такой случайный интервал необходим для распределения нагрузки на источник словаря при обновлении на большом числе серверов. Во время обновления старая версия словаря по-прежнему может использоваться в запросах, при этом только начальная загрузка блокирует запросы. Обратите внимание, что задание (LIFETIME(0)) предотвращает обновление словарей.
Принудительную перезагрузку словарей можно выполнить с помощью команды SYSTEM RELOAD DICTIONARY.
Для источников данных, таких как ClickHouse и Postgres, вы можете настроить запрос, который будет обновлять словари только в том случае, если они действительно изменились (это определяется ответом на запрос), а не с периодическим интервалом. Дополнительные подробности можно найти здесь.
Другие типы словарей
ClickHouse также поддерживает иерархические, многоугольные и словарі на основе регулярных выражений словари.
