Коллектор OpenTelemetry ClickStack
На этой странице представлена подробная информация по настройке официального коллектора OpenTelemetry (OTel) для ClickStack.
Роли коллектора
Коллекторы OpenTelemetry могут быть развернуты в двух основных ролях:
-
Agent — экземпляры Agent собирают данные на периферии, например на серверах или узлах Kubernetes, либо принимают события непосредственно от приложений, инструментированных с помощью OpenTelemetry SDK. В последнем случае экземпляр Agent запускается вместе с приложением или на том же хосте, что и приложение (например, как sidecar или ДемонСет). Экземпляры Agent могут либо отправлять свои данные напрямую в ClickHouse, либо в экземпляр Gateway. В первом случае это называется паттерн развертывания Agent.
-
Gateway — экземпляры Gateway предоставляют автономный сервис (например, Развертывание в Kubernetes), как правило, на кластер, дата-центр или регион. Они принимают события от приложений (или других коллекторов, работающих как Agents) через единую OTLP-конечную точку. Обычно разворачивается группа экземпляров Gateway, при этом готовый балансировщик нагрузки используется для распределения нагрузки между ними. Если все Agents и приложения отправляют свои сигналы на эту единую конечную точку, это часто называют паттерн развертывания Gateway.
Важно: Коллектор, включая вариант по умолчанию в поставке ClickStack, предполагает роль Gateway, описанную ниже, получая данные от Agents или SDK.
Пользователи, развертывающие OTel collector в роли Agent, обычно используют стандартную contrib-сборку коллектора, а не версию ClickStack, но могут свободно применять и другие технологии, совместимые с OTLP, такие как Fluentd и Vector.
Развертывание коллектора
Если вы управляете собственным коллектором OpenTelemetry в автономном развертывании — например, при использовании дистрибутива HyperDX-only, — мы по‑прежнему рекомендуем использовать официальный дистрибутив коллектора ClickStack в роли шлюза, где это возможно, но если вы решите использовать собственный вариант, убедитесь, что он включает ClickHouse exporter.
Автономный режим
Чтобы развернуть дистрибутив ClickStack коннектора OTel в автономном режиме, выполните следующую команду Docker:
Обратите внимание, что можно переопределить целевой экземпляр ClickHouse с помощью переменных окружения CLICKHOUSE_ENDPOINT, CLICKHOUSE_USERNAME и CLICKHOUSE_PASSWORD. Значение CLICKHOUSE_ENDPOINT должно быть полным HTTP-эндпоинтом ClickHouse, включая протокол и порт — например, http://localhost:8123.
Эти переменные окружения можно использовать с любыми docker-дистрибутивами, которые включают коннектор.
Переменная OPAMP_SERVER_URL должна указывать на ваше развертывание HyperDX — например, http://localhost:4320. HyperDX по умолчанию предоставляет сервер OpAMP (Open Agent Management Protocol) по пути /v1/opamp на порту 4320. Убедитесь, что этот порт проброшен из контейнера, в котором запущен HyperDX (например, с помощью -p 4320:4320).
Чтобы коллектор смог подключиться к порту OpAMP, он должен быть опубликован контейнером HyperDX, например, с помощью -p 4320:4320. Для локального тестирования пользователи macOS могут затем задать OPAMP_SERVER_URL=http://host.docker.internal:4320. Пользователи Linux могут запустить контейнер коллектора с параметром --network=host.
В продуктивной среде пользователям следует использовать учётную запись с подходящими учетными данными.
Изменение конфигурации
Использование Docker
Все образы Docker с включённым OpenTelemetry Collector можно настроить на использование экземпляра ClickHouse через переменные окружения OPAMP_SERVER_URL, CLICKHOUSE_ENDPOINT, CLICKHOUSE_USERNAME и CLICKHOUSE_PASSWORD:
Например, образ all-in-one:
Docker Compose
В Docker Compose измените конфигурацию коллектора, используя те же переменные окружения, что и выше:
Расширенная конфигурация
Дистрибутив OTel collector в составе ClickStack поддерживает расширение базовой конфигурации за счёт монтирования пользовательского конфигурационного файла и задания переменной окружения. Пользовательская конфигурация объединяется с базовой конфигурацией, управляемой HyperDX через OpAMP.
Расширение конфигурации коллектора
Чтобы добавить пользовательские receivers, processors или pipelines:
- Создайте пользовательский файл конфигурации с дополнительными параметрами
- Смонтируйте файл по пути
/etc/otelcol-contrib/custom.config.yaml - Установите переменную окружения
CUSTOM_OTELCOL_CONFIG_FILE=/etc/otelcol-contrib/custom.config.yaml
Пример пользовательской конфигурации:
Разверните, используя образ «всё в одном»:
Развертывание с отдельным коллектором:
В пользовательской конфигурации вы определяете только новые receivers, processors и pipelines. Базовые processors (memory_limiter, batch) и exporters (clickhouse) уже определены — ссылайтесь на них по имени. Пользовательская конфигурация объединяется с базовой конфигурацией и не может переопределять существующие компоненты.
Для более сложных конфигураций обратитесь к стандартной конфигурации коллектора ClickStack и к документации по экспортёру ClickHouse.
Структура конфигурации
Подробную информацию о настройке OTel collector, включая receivers, operators и processors, см. в официальной документации по OpenTelemetry collector.
Обеспечение безопасности коллектора
Дистрибутив ClickStack с коллектором OpenTelemetry включает встроенную поддержку OpAMP (Open Agent Management Protocol), который используется для безопасной конфигурации и управления конечной точкой OTLP. При запуске пользователям необходимо указать переменную окружения OPAMP_SERVER_URL — она должна указывать на приложение HyperDX, которое предоставляет OpAMP API по адресу /v1/opamp.
Эта интеграция гарантирует, что конечная точка OTLP защищена с помощью автоматически сгенерированного ключа API для приёма данных (ingestion API key), создаваемого при развертывании приложения HyperDX. Все телеметрические данные, отправляемые в коллектор, должны включать этот API key для аутентификации. Найти ключ можно в приложении HyperDX в разделе Team Settings → API Keys.
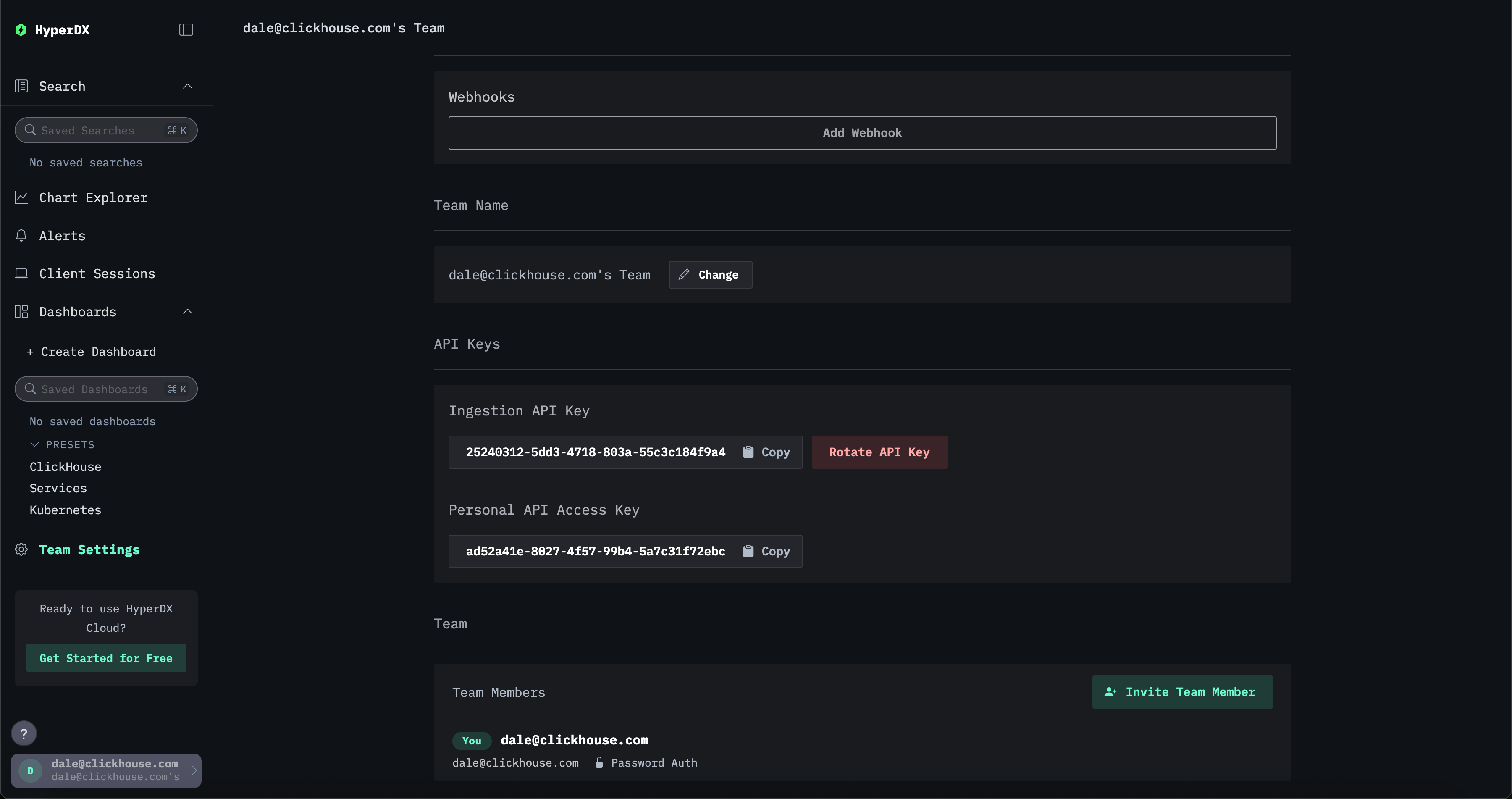
Для дополнительной защиты вашего развертывания мы рекомендуем:
- Настроить коллектор на взаимодействие с ClickHouse по HTTPS.
- Создать отдельного пользователя для приёма данных с ограниченными правами — см. ниже.
- Включить TLS для конечной точки OTLP, обеспечив шифрованное взаимодействие между SDKs/агентами и коллектором. Это можно настроить через пользовательскую конфигурацию коллектора.
Создание пользователя для ингестии
Мы рекомендуем создать отдельную базу данных и пользователя для коллектора OTel для ингестии данных в ClickHouse. У этого пользователя должны быть права на создание и вставку данных в таблицы, созданные и используемые ClickStack.
Предполагается, что коллектор настроен на использование базы данных otel. Этим можно управлять через переменную окружения HYPERDX_OTEL_EXPORTER_CLICKHOUSE_DATABASE. Передайте её в образ контейнера с коллектором аналогично другим переменным окружения.
Обработка — фильтрация, трансформация и обогащение
Пользователям в большинстве случаев потребуется фильтровать, трансформировать и обогащать сообщения событий во время ингестии. Поскольку конфигурацию коннектора ClickStack нельзя изменить, мы рекомендуем пользователям, которым требуется дополнительная фильтрация и обработка событий, либо:
- Развернуть собственную версию OTel collector, выполняющего фильтрацию и обработку, отправляя события в ClickStack collector по OTLP для ингестии в ClickHouse.
- Развернуть собственную версию OTel collector и отправлять события напрямую в ClickHouse с использованием ClickHouse exporter.
Если обработка выполняется с использованием OTel collector, мы рекомендуем выполнять трансформации на экземплярах gateway и минимизировать объём работ, выполняемых на экземплярах agent. Это позволит свести к минимуму потребление ресурсов агентами на периферии, работающими на серверах. Как правило, мы видим, что пользователи выполняют только фильтрацию (для минимизации ненужного сетевого трафика), установку временных меток (через операторы) и обогащение, которое требует контекста в агентах. Например, если экземпляры gateway находятся в другом Kubernetes‑кластере, k8s‑обогащение должно выполняться в агенте.
OpenTelemetry поддерживает следующие возможности обработки и фильтрации, которыми могут пользоваться пользователи:
-
Processors — processors принимают данные, собранные receivers, и модифицируют или трансформируют их перед отправкой в exporters. Processors применяются в порядке, указанном в секции
processorsконфигурации collector. Они необязательны, но минимальный набор обычно рекомендуется. При использовании OTel collector с ClickHouse мы рекомендуем ограничиться следующими processors: -
memory_limiter используется для предотвращения ситуаций с нехваткой памяти на collector. См. рекомендации в разделе Estimating Resources.
-
Любой processor, который выполняет обогащение на основе контекста. Например, Kubernetes Attributes Processor позволяет автоматически устанавливать resource‑атрибуты spans, metrics и logs с k8s‑метаданными, например обогащать события идентификатором исходного пода.
-
Tail или head sampling, если это требуется для трейсов.
-
Базовая фильтрация — отбрасывание ненужных событий, если это нельзя сделать через operator (см. ниже).
-
Batching — критически важно при работе с ClickHouse, чтобы данные отправлялись пакетами. См. "Optimizing inserts".
-
Operators — operators предоставляют самый базовый уровень обработки, доступный на стороне receiver. Поддерживается базовый парсинг, позволяющий устанавливать такие поля, как Severity и Timestamp. Здесь поддерживаются JSON‑ и regex‑парсинг, а также фильтрация событий и базовые трансформации. Мы рекомендуем выполнять фильтрацию событий на этом уровне.
Мы рекомендуем пользователям избегать чрезмерной обработки событий с использованием operators или transform processors. Они могут приводить к значительным накладным расходам по памяти и CPU, особенно при JSON‑парсинге. Возможно выполнять всю обработку в ClickHouse на этапе вставки с помощью материализованных представлений и столбцов с некоторыми исключениями — в частности, для контекстно‑зависимого обогащения, например добавления k8s‑метаданных. Для более подробной информации см. Extracting structure with SQL.
Пример
Следующая конфигурация демонстрирует сбор данных из этого неструктурированного файла логов. Эту конфигурацию может использовать коллектор в роли агента, отправляющий данные на шлюз ClickStack.
Обратите внимание на использование операторов для извлечения структуры из строк логов (regex_parser) и фильтрации событий, а также процессора для пакетирования событий и ограничения потребления памяти.
Обратите внимание на необходимость добавлять заголовок авторизации с вашим ключом API для приёма данных API key во все OTLP-запросы.
Для более сложной конфигурации мы рекомендуем обратиться к документации по OpenTelemetry collector.
Оптимизация вставок
Чтобы обеспечить высокую производительность операций вставки при одновременном соблюдении строгих гарантий согласованности, пользователям следует придерживаться нескольких простых правил при вставке данных наблюдаемости в ClickHouse через коллектор ClickStack. При корректной настройке OTel collector следовать этим правилам должно быть несложно. Это также позволяет избежать распространённых проблем, с которыми пользователи сталкиваются при первом знакомстве с ClickHouse.
Пакетирование
По умолчанию каждый запрос INSERT, отправленный в ClickHouse, приводит к немедленному созданию части данных, содержащей данные из этого INSERT вместе с другой метаинформацией, которую нужно сохранять. Поэтому отправка меньшего количества INSERT‑запросов, каждый из которых содержит больше данных, по сравнению с отправкой большего количества INSERT‑запросов с меньшим объемом данных, уменьшит число необходимых операций записи. Мы рекомендуем вставлять данные достаточно крупными пакетами — как минимум по 1 000 строк за раз. Дополнительные подробности приведены здесь.
По умолчанию вставки в ClickHouse являются синхронными и идемпотентными, если данные идентичны. Для таблиц семейства движков MergeTree ClickHouse по умолчанию автоматически дедуплицирует вставки. Это означает, что вставки устойчивы к сбоям в следующих случаях:
- (1) Если у узла, принимающего данные, возникают проблемы, запрос
INSERTзавершится по таймауту (или выдаст более специфичную ошибку) и не получит подтверждения. - (2) Если данные были записаны узлом, но подтверждение не может быть возвращено отправителю запроса из‑за перебоев в сети, отправитель получит либо таймаут, либо сетевую ошибку.
С точки зрения коллектора различить (1) и (2) может быть сложно. Однако в обоих случаях неподтвержденную вставку можно просто немедленно повторить. Пока повторный запрос INSERT содержит те же данные в том же порядке, ClickHouse автоматически проигнорирует повторную вставку, если исходная (неподтвержденная) вставка уже была успешно выполнена.
По этой причине дистрибутив ClickStack с OTel collector использует batch processor. Это гарантирует, что вставки отправляются как согласованные пакеты строк, удовлетворяющие указанным выше требованиям. Если от коллектора ожидается высокая пропускная способность (событий в секунду) и в каждой вставке можно отправлять как минимум 5 000 событий, этого пакетирования обычно достаточно для всего конвейера. В этом случае коллектор будет отправлять пакеты до того, как будет достигнут timeout batch processor, обеспечивая низкую сквозную задержку конвейера и стабильный размер пакетов.
Используйте асинхронные вставки
Обычно пользователи вынуждены отправлять меньшие батчи, когда пропускная способность коллектора низкая, при этом они все равно ожидают доставки данных в ClickHouse с минимальной сквозной задержкой. В этом случае маленькие батчи отправляются при истечении timeout у batch processor. Это может вызывать проблемы и в таких сценариях требуются асинхронные вставки. Такая ситуация встречается редко, если пользователи отправляют данные в коллектор ClickStack, работающий в роли Gateway: выступая в качестве агрегатора, он сглаживает эту проблему — см. Collector roles.
Если невозможно гарантировать большие батчи, пользователи могут делегировать пакетирование ClickHouse, используя Asynchronous Inserts. При асинхронных вставках данные сначала вставляются в буфер, а затем записываются в хранилище базы данных позже, то есть асинхронно.
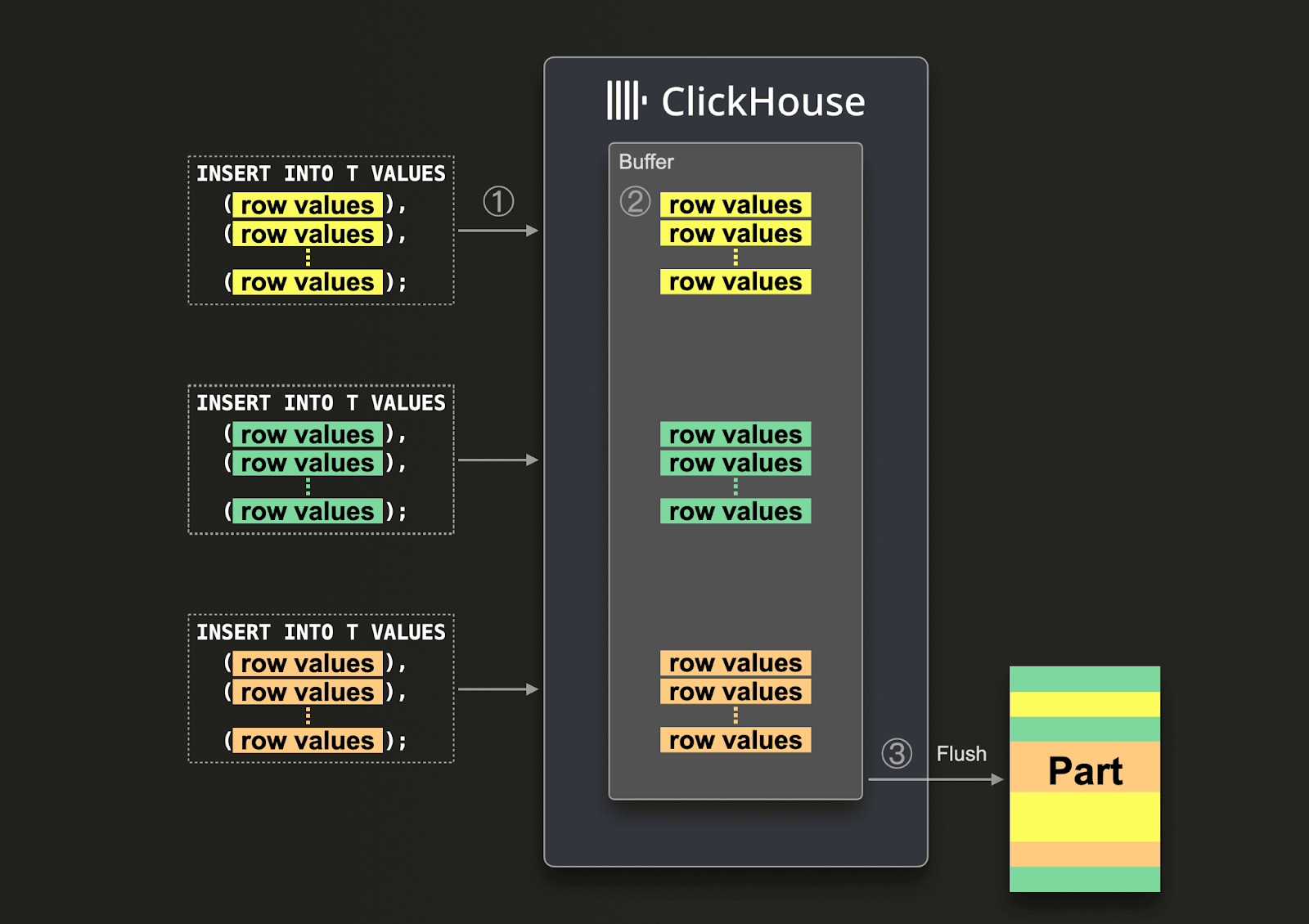
При включенных асинхронных вставках, когда ClickHouse ① получает запрос INSERT, данные запроса ② сразу же записываются сначала во внутренний буфер в памяти. Когда ③ происходит следующий сброс (flush) буфера, данные из буфера сортируются и записываются как part в хранилище базы данных. Обратите внимание, что данные недоступны для запросов до тех пор, пока не будут сброшены в хранилище базы данных; параметры сброса буфера настраиваются.
Чтобы включить асинхронные вставки для коллектора, добавьте async_insert=1 в строку подключения. Мы рекомендуем использовать wait_for_async_insert=1 (значение по умолчанию), чтобы получить гарантии доставки — см. здесь подробности.
Данные из асинхронной вставки записываются после того, как буфер ClickHouse будет сброшен. Это происходит либо после превышения async_insert_max_data_size, либо по истечении async_insert_busy_timeout_ms миллисекунд с момента первого запроса INSERT. Если async_insert_stale_timeout_ms установлено в ненулевое значение, данные вставляются по прошествии async_insert_stale_timeout_ms миллисекунд с момента последнего запроса. Пользователи могут настраивать эти параметры для управления сквозной задержкой своего конвейера. Дополнительные параметры, которые можно использовать для настройки сброса буфера, задокументированы здесь. Как правило, значения по умолчанию являются оптимальными.
В случаях, когда используется небольшое количество агентов с низкой пропускной способностью, но жесткими требованиями к сквозной задержке, могут быть полезны адаптивные асинхронные вставки. Как правило, они неприменимы к высоконагруженным сценариям Observability, характерным для ClickHouse.
Наконец, прежнее поведение дедупликации, связанное с синхронными вставками в ClickHouse, по умолчанию не включено при использовании асинхронных вставок. При необходимости см. параметр async_insert_deduplicate.
Полные сведения по настройке этой функции можно найти на этой странице документации или в подробной публикации в блоге.
Масштабирование
OTel collector в составе ClickStack действует как экземпляр шлюза (Gateway) — см. раздел Collector roles. Это автономный сервис, как правило, по одному на каждый дата-центр или регион. Такие экземпляры получают события от приложений (или других коллекторов в роли агента) через единый OTLP endpoint. Обычно разворачивается несколько экземпляров коллектора, а стандартный балансировщик нагрузки используется для распределения трафика между ними.

Цель этой архитектуры — разгрузить агентов от вычислительно затратной обработки, тем самым минимизируя их потребление ресурсов. Эти шлюзы ClickStack могут выполнять задачи трансформации, которые в противном случае пришлось бы выполнять агентам. Кроме того, агрегируя события от множества агентов, шлюзы могут отправлять в ClickHouse крупные партии событий, обеспечивая эффективную вставку данных. Эти коллекторы-шлюзы можно легко масштабировать по мере добавления новых агентов и источников SDK и роста пропускной способности событий.
Добавление Kafka
Читатели могут заметить, что приведённые выше архитектуры не используют Kafka в качестве очереди сообщений.
Использование очереди Kafka как буфера сообщений — популярный шаблон проектирования, часто встречающийся в архитектурах логирования и получивший широкое распространение благодаря стеку ELK. Он даёт несколько преимуществ: прежде всего, помогает обеспечить более строгие гарантии доставки сообщений и упростить обработку обратного давления. Сообщения отправляются от агентов сбора в Kafka и записываются на диск. Теоретически кластер Kafka должен обеспечивать высокопроизводительный буфер сообщений, поскольку при последовательной записи данных на диск вычислительные затраты ниже, чем при разборе и обработке сообщений. В Elastic, например, токенизация и индексация создают значительные накладные расходы. Перемещая данные от агентов, вы также снижаете риск потери сообщений из‑за ротации логов на источнике. Наконец, Kafka предоставляет возможности повторного считывания сообщений и межрегиональной репликации, что может быть привлекательно для некоторых сценариев использования.
Однако ClickHouse способен очень быстро вставлять данные — миллионы строк в секунду на умеренном оборудовании. Обратное давление со стороны ClickHouse возникает редко. Часто использование очереди Kafka приводит к росту сложности архитектуры и затрат. Если вы можете исходить из принципа, что логи не нуждаются в тех же гарантиях доставки, что банковские транзакции и другие критически важные данные, мы рекомендуем избегать усложнения архитектуры за счёт Kafka.
Тем не менее, если вам нужны высокие гарантии доставки или возможность повторного воспроизведения данных (потенциально в несколько приёмников), Kafka может быть полезным архитектурным дополнением.
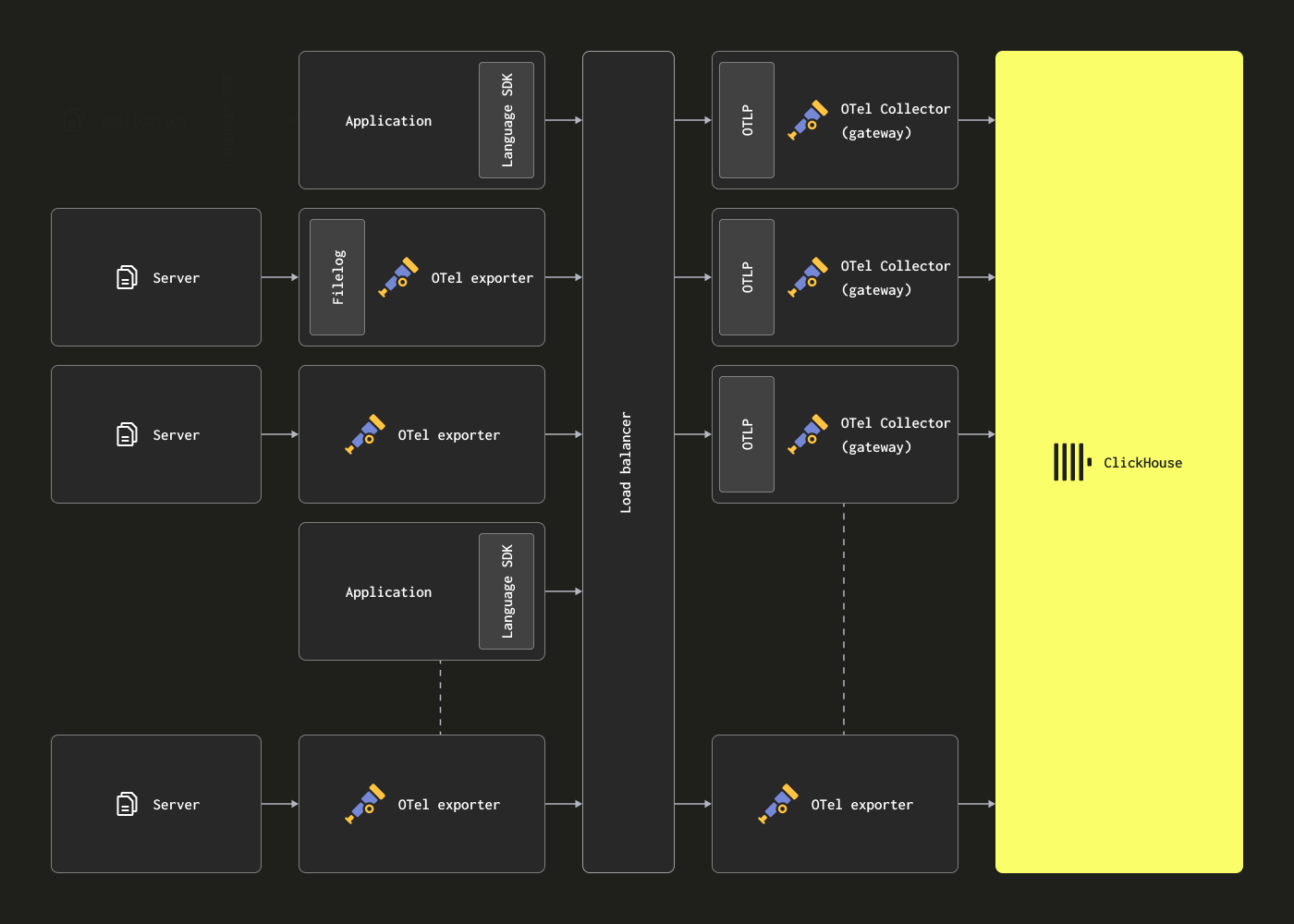
В этом случае агенты OTel можно настроить на отправку данных в Kafka через Kafka exporter. В свою очередь, инстансы gateway потребляют сообщения с помощью Kafka receiver. За дополнительными подробностями рекомендуем документацию Confluent и OTel.
Дистрибутив ClickStack OpenTelemetry collector можно настроить для работы с Kafka с помощью кастомной конфигурации коллектора.
Оценка ресурсов
Требования к ресурсам для OTel collector будут зависеть от пропускной способности событий, размера сообщений и объёма выполняемой обработки. Проект OpenTelemetry ведёт бенчмарки, которыми пользователи могут воспользоваться для оценки требований к ресурсам.
Согласно нашему опыту, экземпляр шлюза ClickStack с 3 ядрами и 12 ГБ ОЗУ может обрабатывать около 60 тыс. событий в секунду. Это предполагает минимальный конвейер обработки, отвечающий только за переименование полей, без регулярных выражений.
Для экземпляров агентов, отвечающих за отправку событий на шлюз и только устанавливающих временную метку события, мы рекомендуем подбирать ресурсы на основе ожидаемого числа логов в секунду. Ниже приведены примерные значения, которые можно использовать в качестве отправной точки:
| Скорость логирования | Ресурсы для агентского коллектора |
|---|---|
| 1k/сек | 0.2 CPU, 0.2 GiB |
| 5k/сек | 0.5 CPU, 0.5 GiB |
| 10k/сек | 1 CPU, 1 GiB |
Поддержка JSON
Поддержка типа JSON в ClickStack является функцией в бета-версии. Хотя сам тип JSON готов к промышленной эксплуатации в ClickHouse 25.3+, его интеграция в ClickStack все еще активно развивается и может иметь ограничения, изменяться в будущем или содержать ошибки.
Начиная с версии 2.0.4, ClickStack в бета-режиме поддерживает тип JSON.
Преимущества типа JSON
Тип JSON предоставляет пользователям ClickStack следующие преимущества:
- Сохранение типов - Числа остаются числами, логические значения остаются логическими — больше не нужно превращать всё в строки. Это означает меньше приведений типов, более простые запросы и более точные агрегаты.
- Столбцы на уровне путей - Каждый JSON-путь становится отдельным подстолбцом, уменьшая объём операций ввода-вывода. Запросы считывают только нужные поля, обеспечивая существенный прирост производительности по сравнению со старым типом Map, который требовал чтения всего столбца для выборки одного конкретного поля.
- Глубокая вложенность «просто работает» - Естественная обработка сложных, глубоко вложенных структур без ручной развёртки (как это требовалось для типа Map) и последующего использования неудобных функций JSONExtract.
- Динамические, эволюционирующие схемы - Идеально для данных наблюдаемости, где команды со временем добавляют новые теги и атрибуты. JSON автоматически обрабатывает эти изменения без миграций схемы.
- Быстрые запросы, меньший объём памяти - Типичные агрегаты по атрибутам вроде
LogAttributesприводят к 5–10-кратному уменьшению объёма читаемых данных и существенному ускорению запросов, сокращая и время выполнения запросов, и пиковое потребление памяти. - Простое управление - Нет необходимости заранее материализовывать столбцы ради производительности. Каждое поле становится отдельным подстолбцом, обеспечивая ту же скорость, что и нативные столбцы ClickHouse.
Включение поддержки JSON
Чтобы включить эту поддержку для коллектора, задайте переменную окружения OTEL_AGENT_FEATURE_GATE_ARG='--feature-gates=clickhouse.json' в любом развертывании, содержащем коллектор. Это гарантирует, что схемы будут созданы в ClickHouse с использованием типа JSON.
Чтобы иметь возможность выполнять запросы к типу JSON, поддержку также необходимо включить на уровне приложения HyperDX с помощью переменной окружения BETA_CH_OTEL_JSON_SCHEMA_ENABLED=true.
Например:
Миграция со схем на основе Map к типу JSON
Тип JSON не совместим с существующими схемами на основе Map. Включение этой функции приведёт к созданию новых таблиц с использованием типа JSON и требует ручной миграции данных.
Чтобы выполнить миграцию со схем на основе Map, выполните следующие шаги:
Остановите OTel collector
Переименуйте существующие таблицы и обновите источники
Переименуйте существующие таблицы и обновите источники данных в HyperDX.
Например:
Разверните OTel collector
Разверните OTel collector с установленным параметром OTEL_AGENT_FEATURE_GATE_ARG.
Перезапустите контейнер HyperDX с поддержкой схемы JSON
Создайте новые источники данных
Создайте новые источники данных в HyperDX, указывающие на таблицы с типом JSON.
Перенос существующих данных (необязательно)
Чтобы перенести старые данные в новые таблицы формата JSON:
Рекомендуется только для наборов данных объемом менее ~10 миллиардов строк. Данные, ранее хранившиеся с типом Map, не сохраняли точность типов (все значения были строками). В результате эти старые данные будут отображаться как строки в новой схеме до тех пор, пока не будут вытеснены из хранения, что потребует дополнительного приведения типов на фронтенде. Тип для новых данных будет сохраняться при использовании типа JSON.
