Первичные индексы
На этой странице рассматривается разреженный первичный индекс ClickHouse: как он создаётся, как работает и как помогает ускорять выполнение запросов.
Для расширенных стратегий индексации и более детальных технических сведений см. раздел детальный разбор первичных индексов.
Как работает разреженный первичный индекс в ClickHouse?
Разреженный первичный индекс в ClickHouse позволяет эффективно определять гранулы — блоки строк, которые могут содержать данные, удовлетворяющие условию запроса по столбцам ^^первичного ключа^^ таблицы. В следующем разделе мы объясним, как этот индекс строится на основе значений этих столбцов.
Создание разреженного первичного индекса
Чтобы проиллюстрировать, как строится разреженный первичный индекс, мы используем таблицу uk_price_paid_simple вместе с несколькими анимациями.
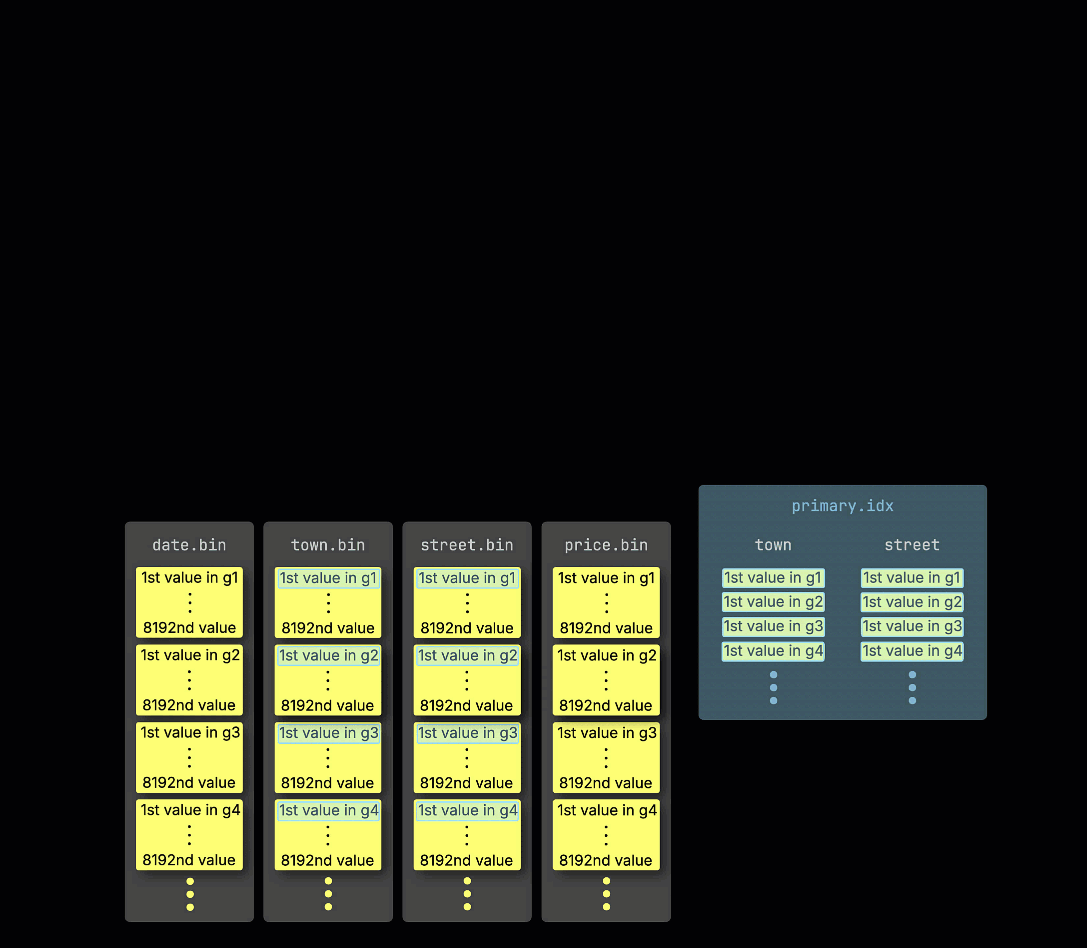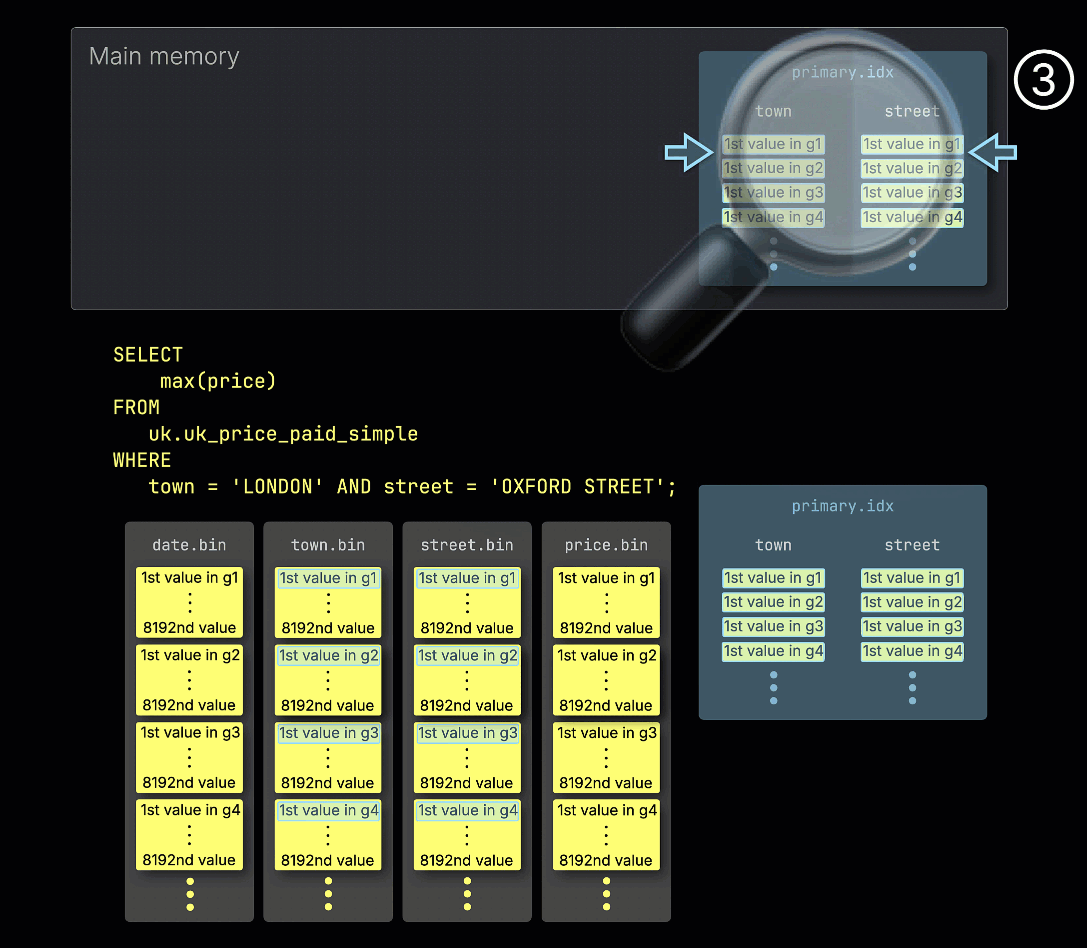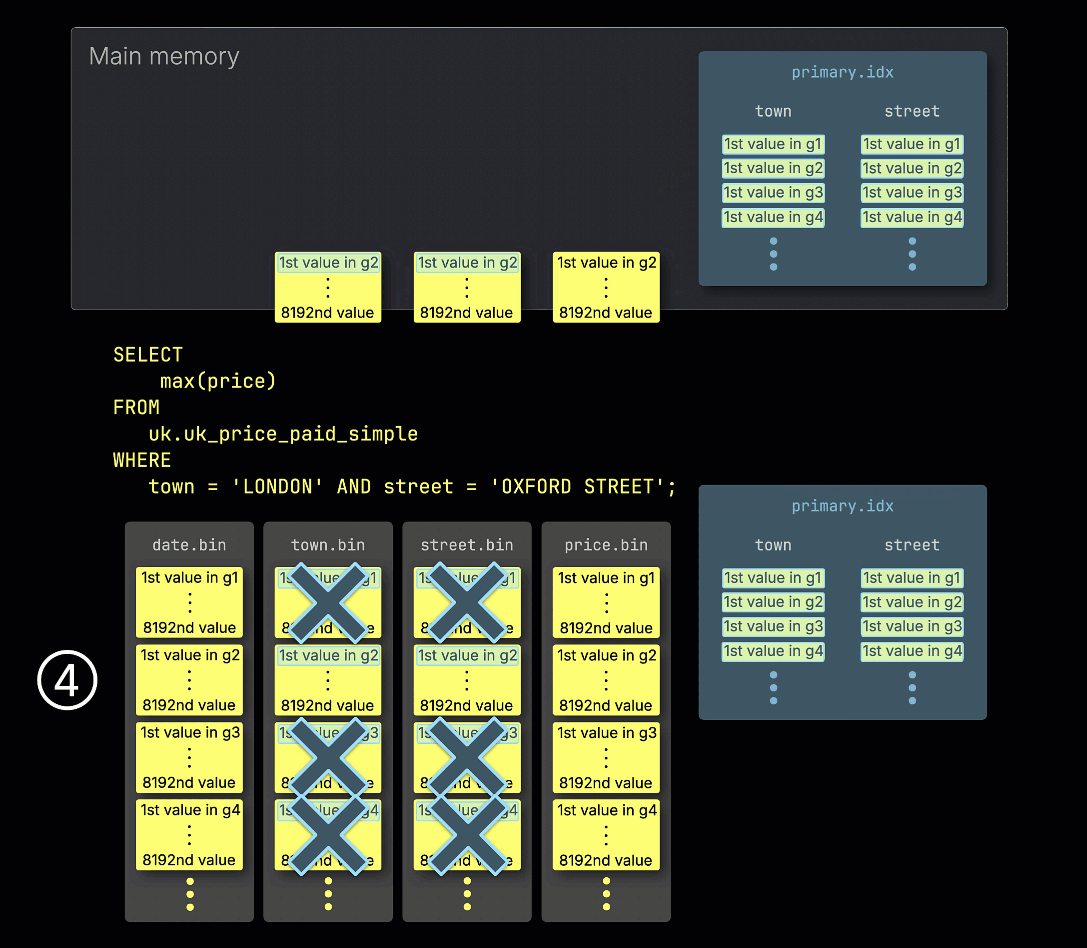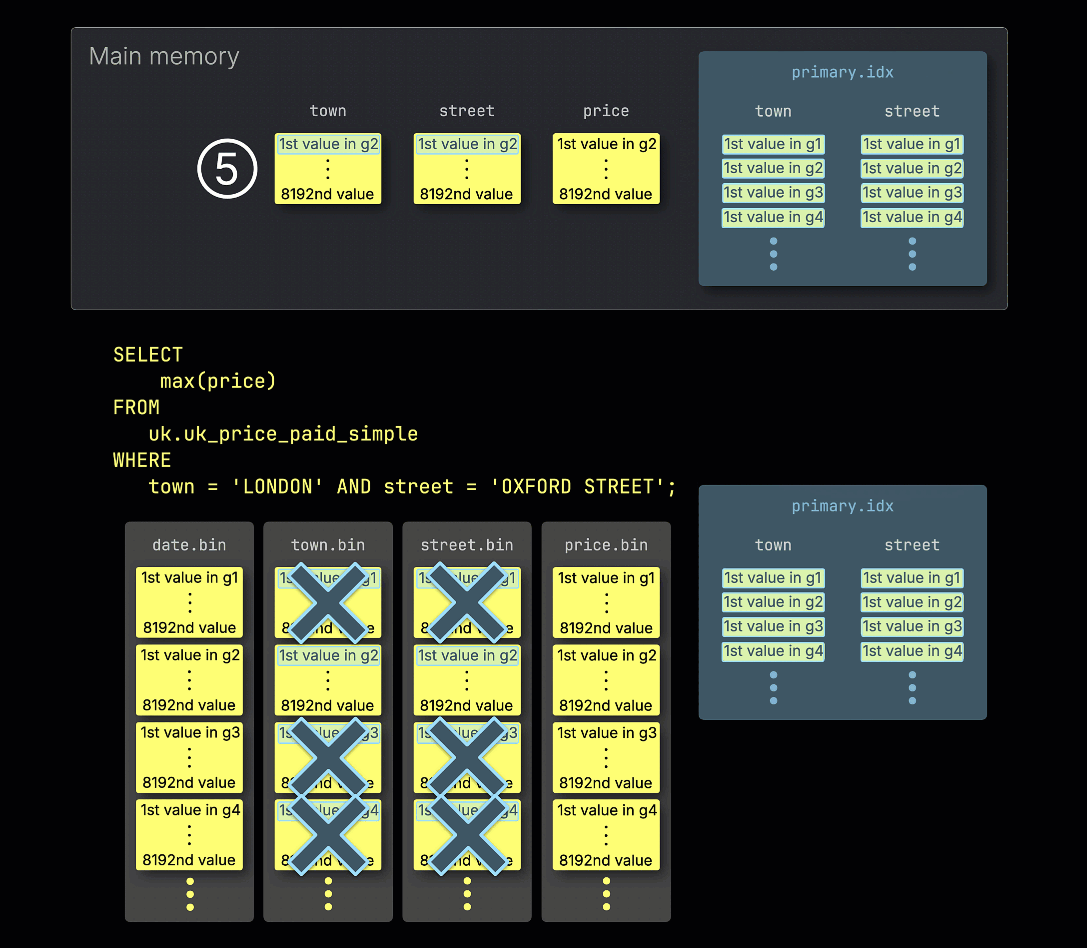
Как напоминание: в нашей ① примерной таблице с ^^первичным ключом^^ (town, street) ② вставленные данные ③ сохраняются на диске, отсортированными по значениям столбцов ^^первичного ключа^^ и сжатыми, в отдельных файлах для каждого столбца:
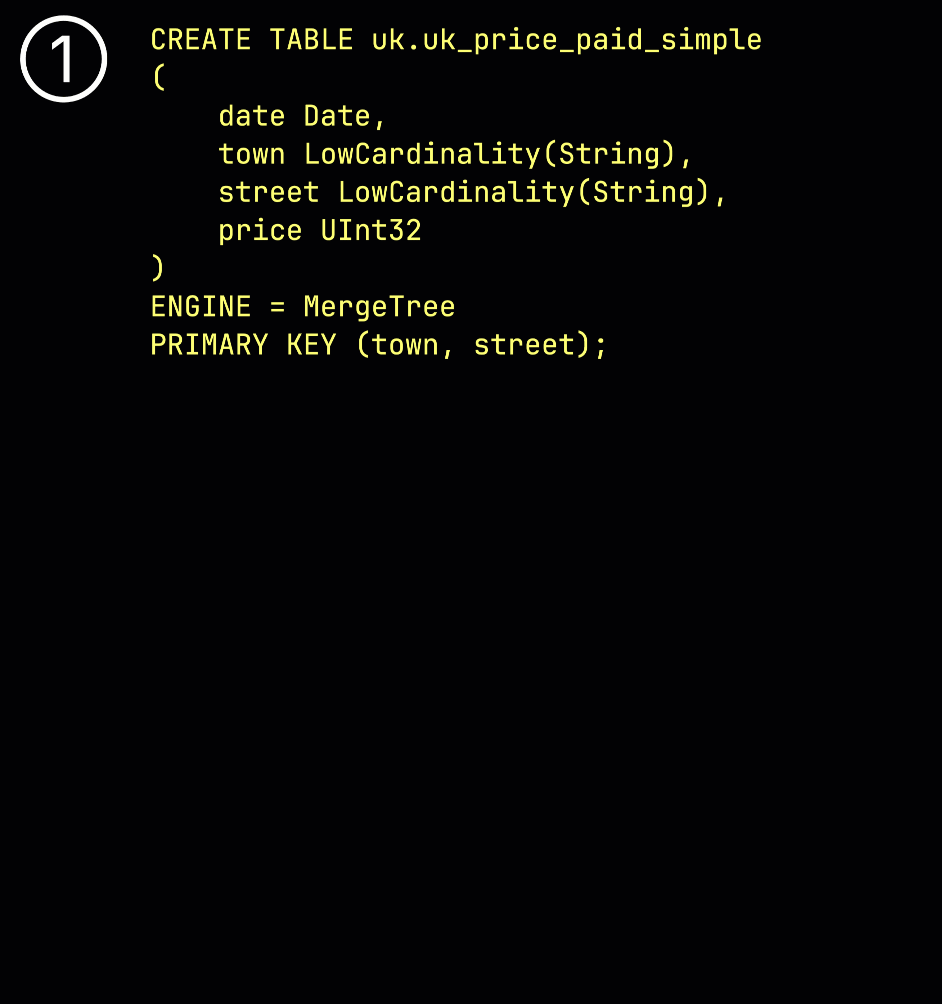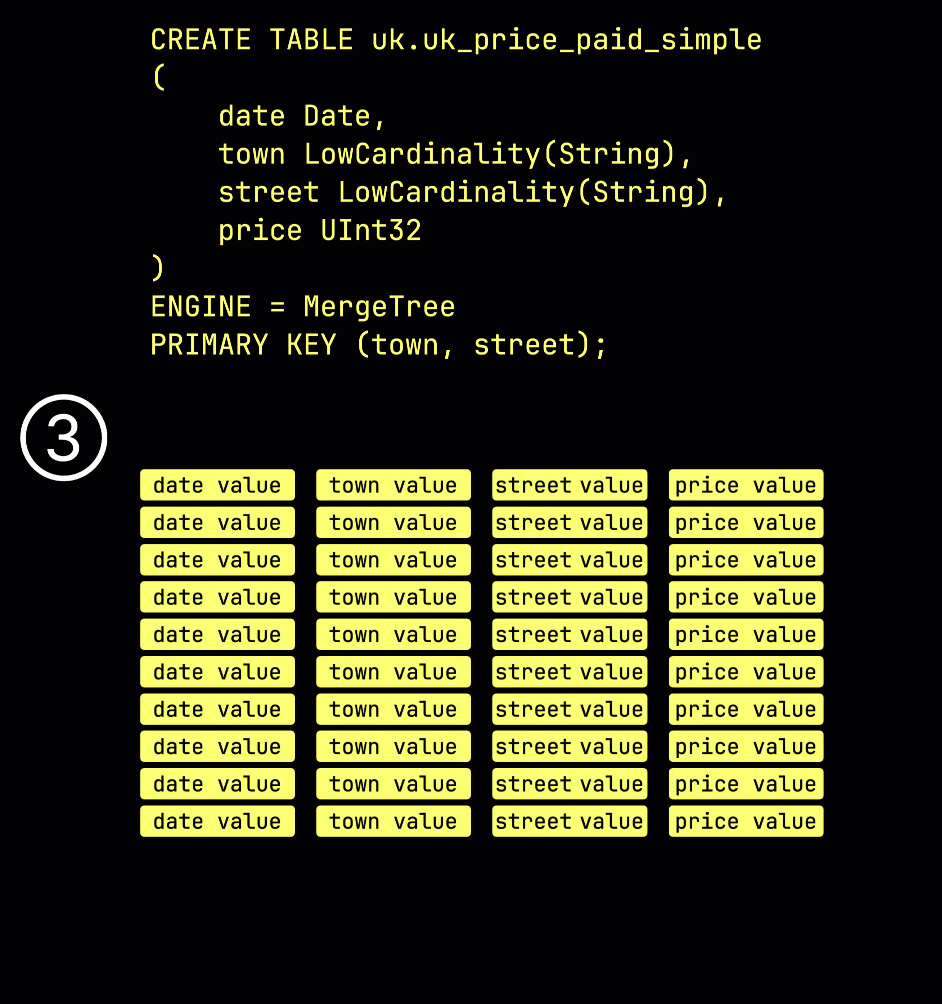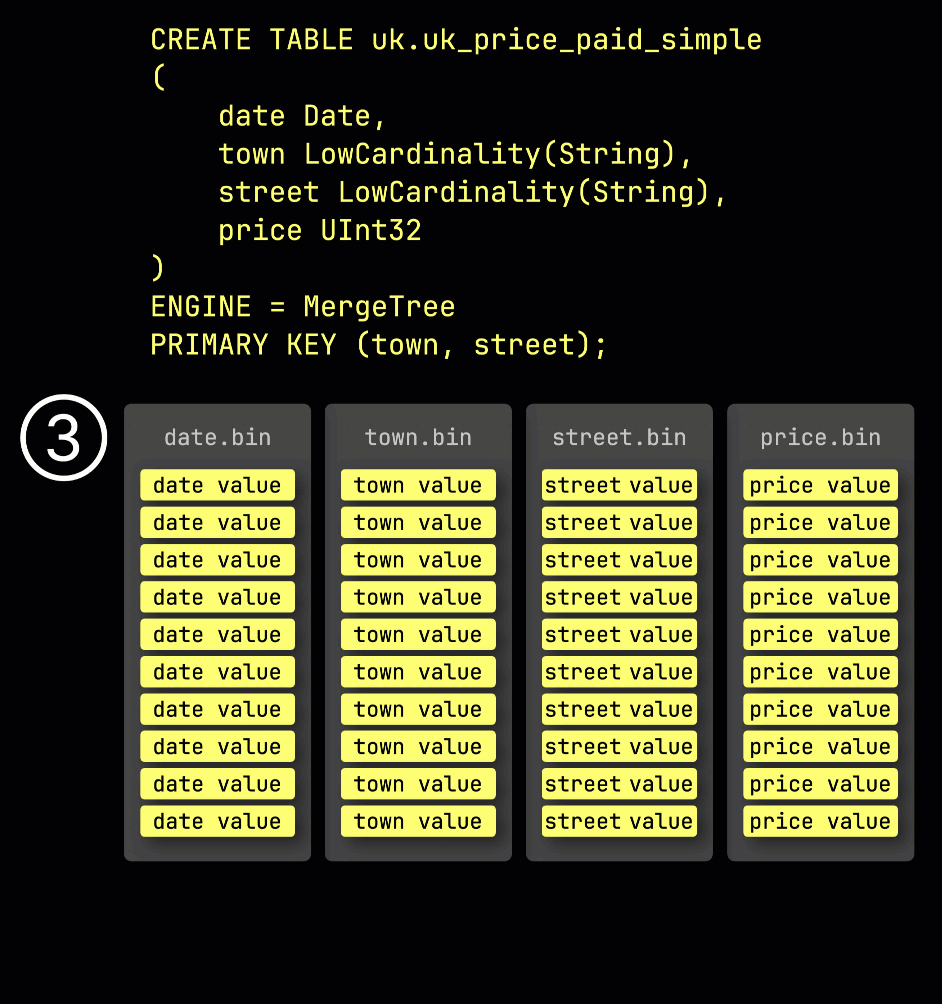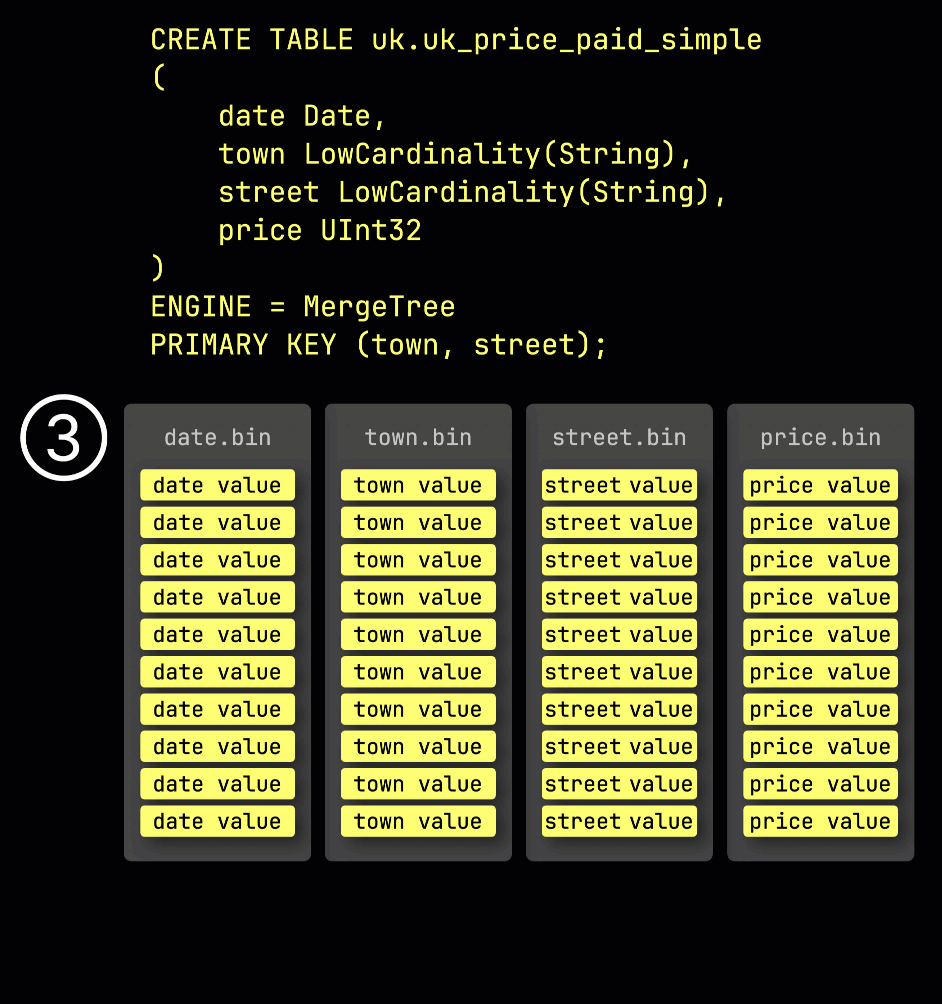
Для обработки данные каждого столбца ④ логически делятся на гранулы — каждая по 8 192 строки — которые являются наименьшими единицами, с которыми работают механизмы обработки данных ClickHouse.
Эта структура ^^гранулы^^ также делает первичный индекс разреженным: вместо индексирования каждой строки ClickHouse хранит ⑤ значения ^^первичного ключа^^ только из одной строки на ^^гранулу^^ — а именно, из первой строки. В результате получается одна запись индекса на ^^гранулу^^:
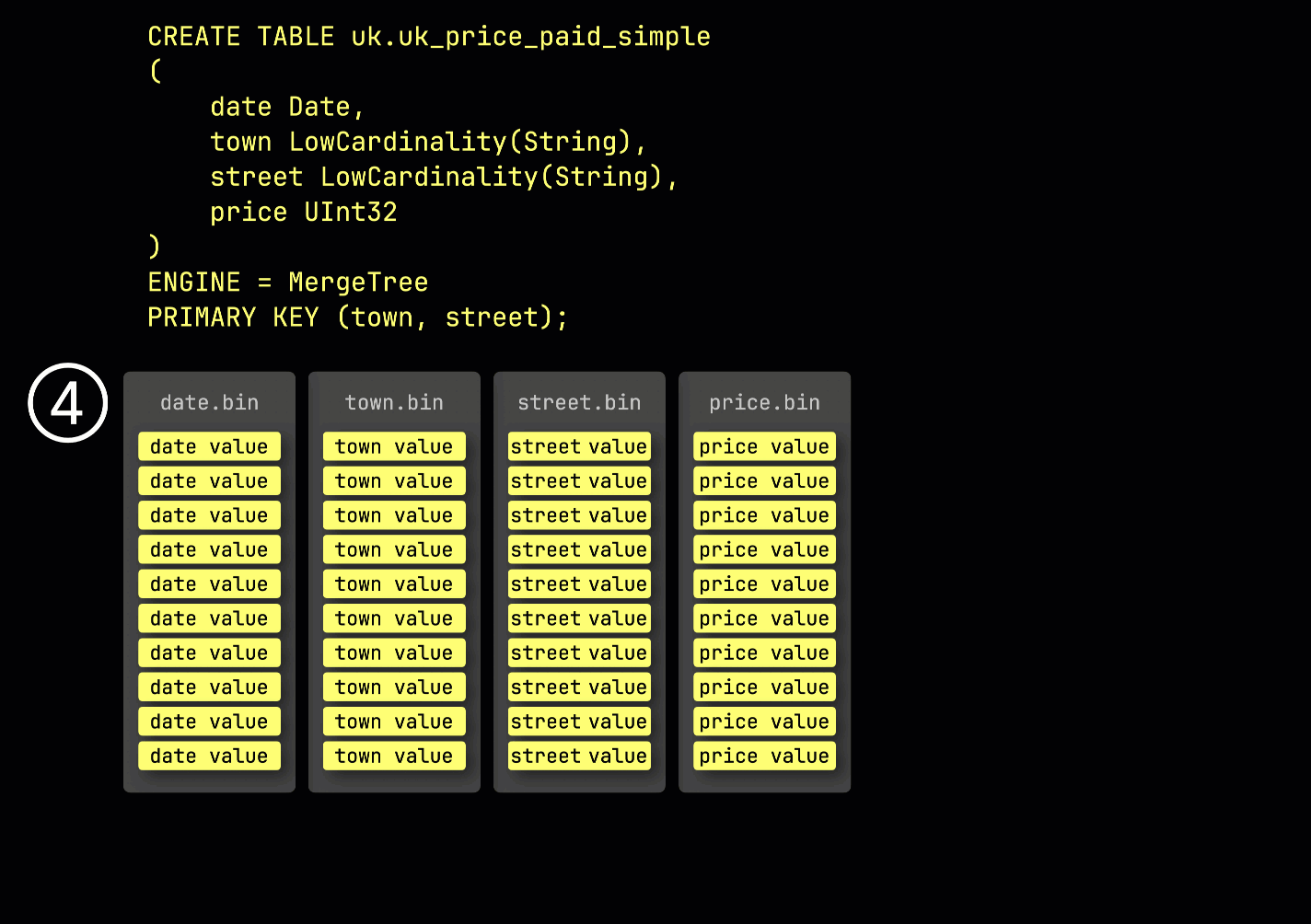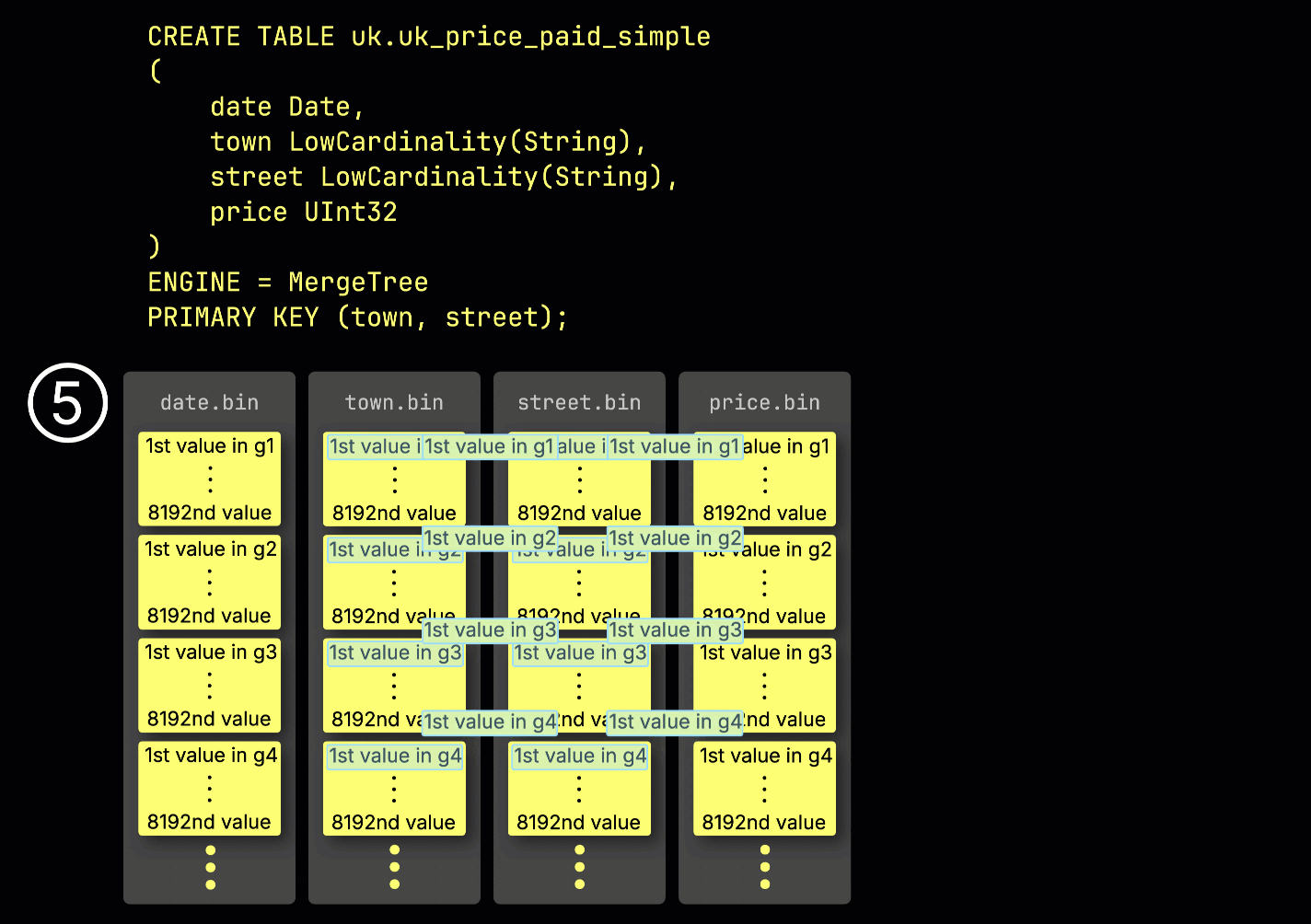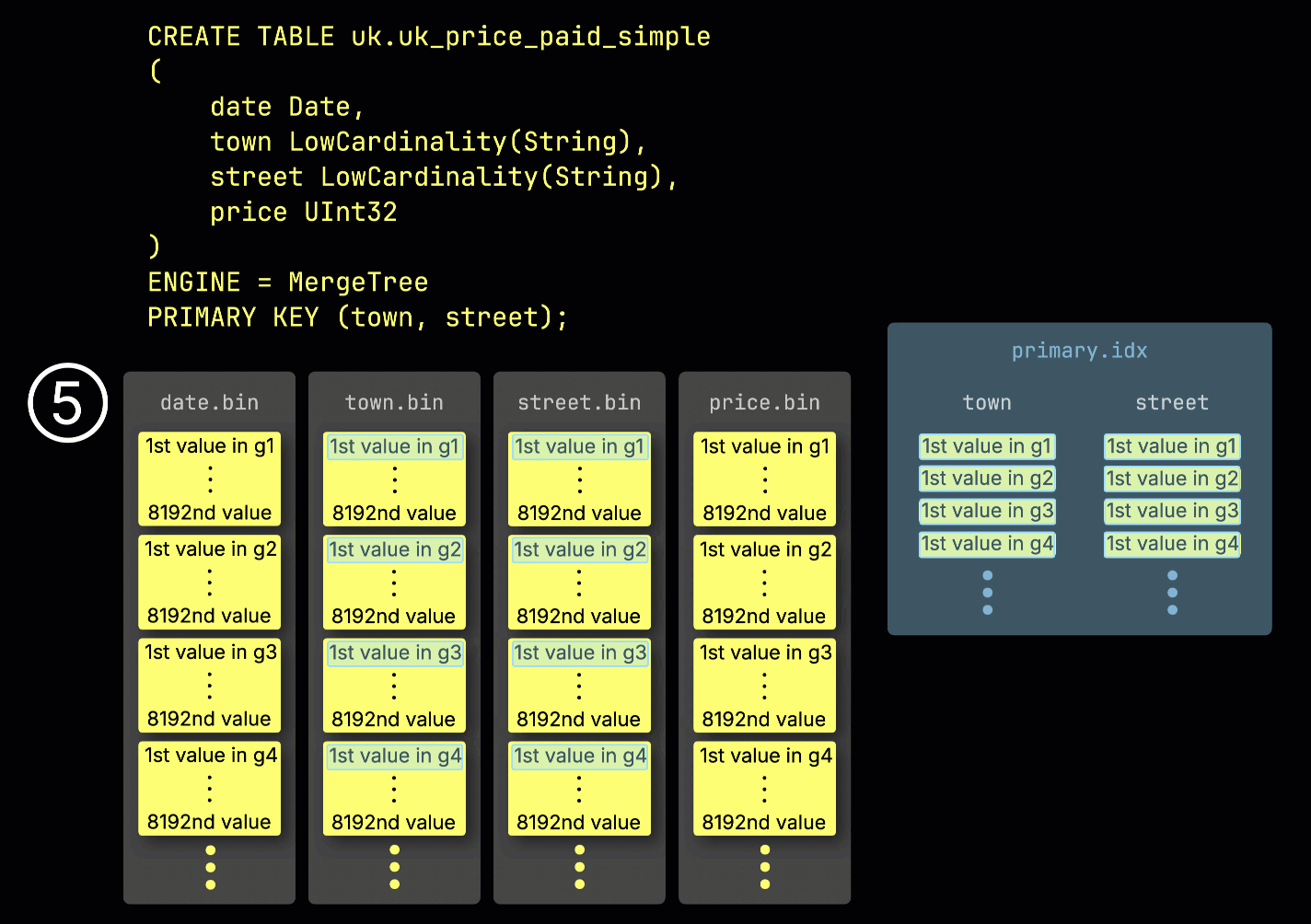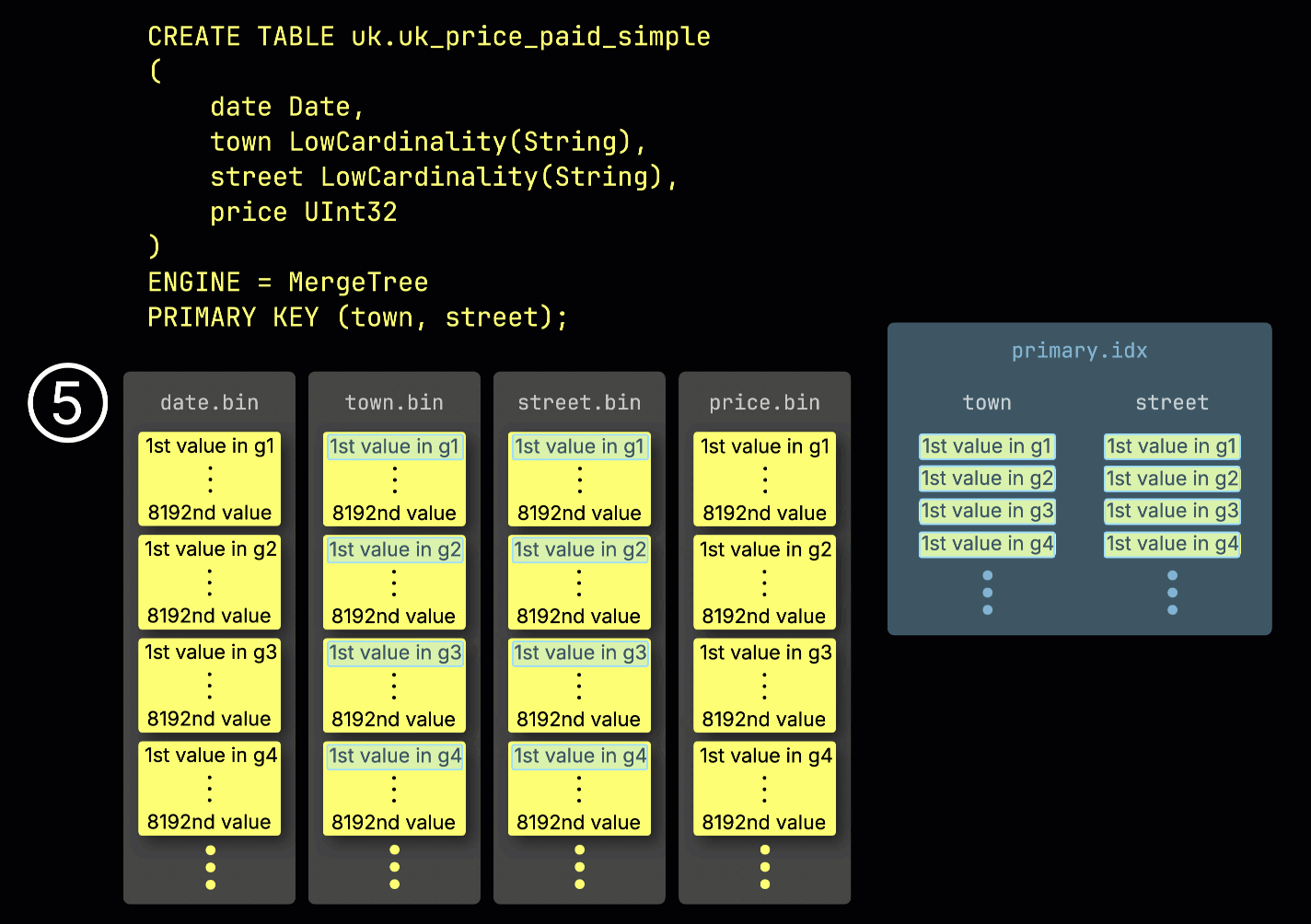
Благодаря своей разреженности первичный индекс достаточно мал, чтобы полностью помещаться в памяти, что обеспечивает быструю фильтрацию запросов с условиями по столбцам ^^первичного ключа^^. В следующем разделе мы покажем, как это помогает ускорять такие запросы.
Использование первичного индекса
Ниже схематично показано, как разреженный первичный индекс используется для ускорения запросов с помощью ещё одной анимации:
① Пример запроса включает предикат на оба столбца ^^primary key^^: town = 'LONDON' AND street = 'OXFORD STREET'.
② Для ускорения запроса ClickHouse загружает в память первичный индекс таблицы.
③ Затем он сканирует записи индекса, чтобы определить, какие гранулы могут содержать строки, удовлетворяющие предикату — другими словами, какие гранулы нельзя пропустить.
④ Эти потенциально подходящие гранулы затем загружаются и обрабатываются в памяти вместе с соответствующими гранулами любых других столбцов, необходимых для запроса.
Мониторинг первичных индексов
Каждая часть данных в таблице имеет свой собственный первичный индекс. Мы можем изучить содержимое этих индексов с помощью табличной функции mergeTreeIndex.
Следующий запрос выводит количество записей в первичном индексе для каждой части данных в нашей таблице-примере:
Этот запрос выводит первые 10 записей первичного индекса одной из текущих ^^частей^^ данных. Обратите внимание, что эти ^^части^^ в фоновом режиме постоянно сливаются в более крупные ^^части^^:
Наконец, мы используем оператор EXPLAIN, чтобы посмотреть, как первичные индексы всех ^^частей^^ данных используются для пропуска гранул, которые заведомо не могут содержать строки, удовлетворяющие предикатам запроса-примера. Эти гранулы исключаются из загрузки и обработки:
Обратите внимание, что строка 13 вывода EXPLAIN, представленного выше, показывает: только 3 из 3 609 гранул во всех ^^parts^^ были выбраны для обработки при анализе первичного индекса. Остальные гранулы были полностью пропущены.
Мы также можем увидеть, что большая часть данных была пропущена, просто выполнив запрос:
Как показано выше, было обработано только около 25 000 строк из примерно 30 миллионов строк в таблице из примера:
Ключевые выводы
-
Разреженные первичные индексы помогают ClickHouse пропускать ненужные данные, определяя, какие гранулы могут содержать строки, удовлетворяющие условиям запроса по столбцам ^^primary key^^.
-
Каждый индекс хранит только значения ^^primary key^^ из первой строки каждой ^^granule^^ (по умолчанию в одной ^^granule^^ 8 192 строки), что делает его достаточно компактным, чтобы целиком размещаться в памяти.
-
Каждая часть данных в таблице ^^MergeTree^^ имеет собственный первичный индекс, который используется независимо при выполнении запросов.
-
При выполнении запросов индекс позволяет ClickHouse пропускать гранулы, уменьшая объем операций ввода-вывода и использование памяти и тем самым ускоряя выполнение запросов.
-
Вы можете изучить содержимое индекса с помощью табличной функции
mergeTreeIndexи отслеживать использование индекса с помощью оператораEXPLAIN.
Где найти дополнительную информацию
Чтобы глубже разобраться, как работают разрежённые первичные индексы в ClickHouse, включая их отличия от традиционных индексов баз данных и лучшие практики их использования, ознакомьтесь с нашим подробным разбором индексирования.
Если вас интересует, как ClickHouse обрабатывает данные, выбранные при первичном сканировании по индексу, в сильно распараллелённом режиме, см. руководство по параллелизму запросов здесь.
