Миграция с BigQuery на ClickHouse Cloud
Почему стоит использовать ClickHouse Cloud вместо BigQuery?
Коротко: потому что ClickHouse быстрее, дешевле и мощнее, чем BigQuery, для современной аналитики данных:

Загрузка данных из BigQuery в ClickHouse Cloud
Набор данных
В качестве примерного набора данных для демонстрации типичной миграции из BigQuery в ClickHouse Cloud мы используем набор данных Stack Overflow, описанный здесь. Он содержит каждый post, vote, user, comment и badge, которые появились на Stack Overflow с 2008 по апрель 2024 года. Схема BigQuery для этих данных показана ниже:

Для пользователей, которые хотят загрузить этот набор данных в экземпляр BigQuery для тестирования шагов миграции, мы предоставили данные для этих таблиц в формате Parquet в бакете GCS, а команды DDL для создания и загрузки таблиц в BigQuery доступны здесь.
Миграция данных
Миграция данных между BigQuery и ClickHouse Cloud делится на два основных типа нагрузок:
- Начальная массовая загрузка с периодическими обновлениями — необходимо перенести исходный набор данных, а затем выполнять периодические обновления через заданные интервалы, например ежедневно. Обновления здесь обрабатываются повторной отправкой строк, которые изменились, — определяемых по столбцу, который можно использовать для сравнения (например, дате). Удаления обрабатываются полной периодической перезагрузкой набора данных.
- Репликация в реальном времени или CDC — необходимо перенести исходный набор данных. Изменения этого набора данных должны отражаться в ClickHouse практически в режиме реального времени, при этом допустима только задержка в несколько секунд. По сути, это процесс CDC (фиксации изменений данных), при котором таблицы в BigQuery должны быть синхронизированы с ClickHouse, то есть вставки, обновления и удаления в таблице BigQuery должны применяться к эквивалентной таблице в ClickHouse.
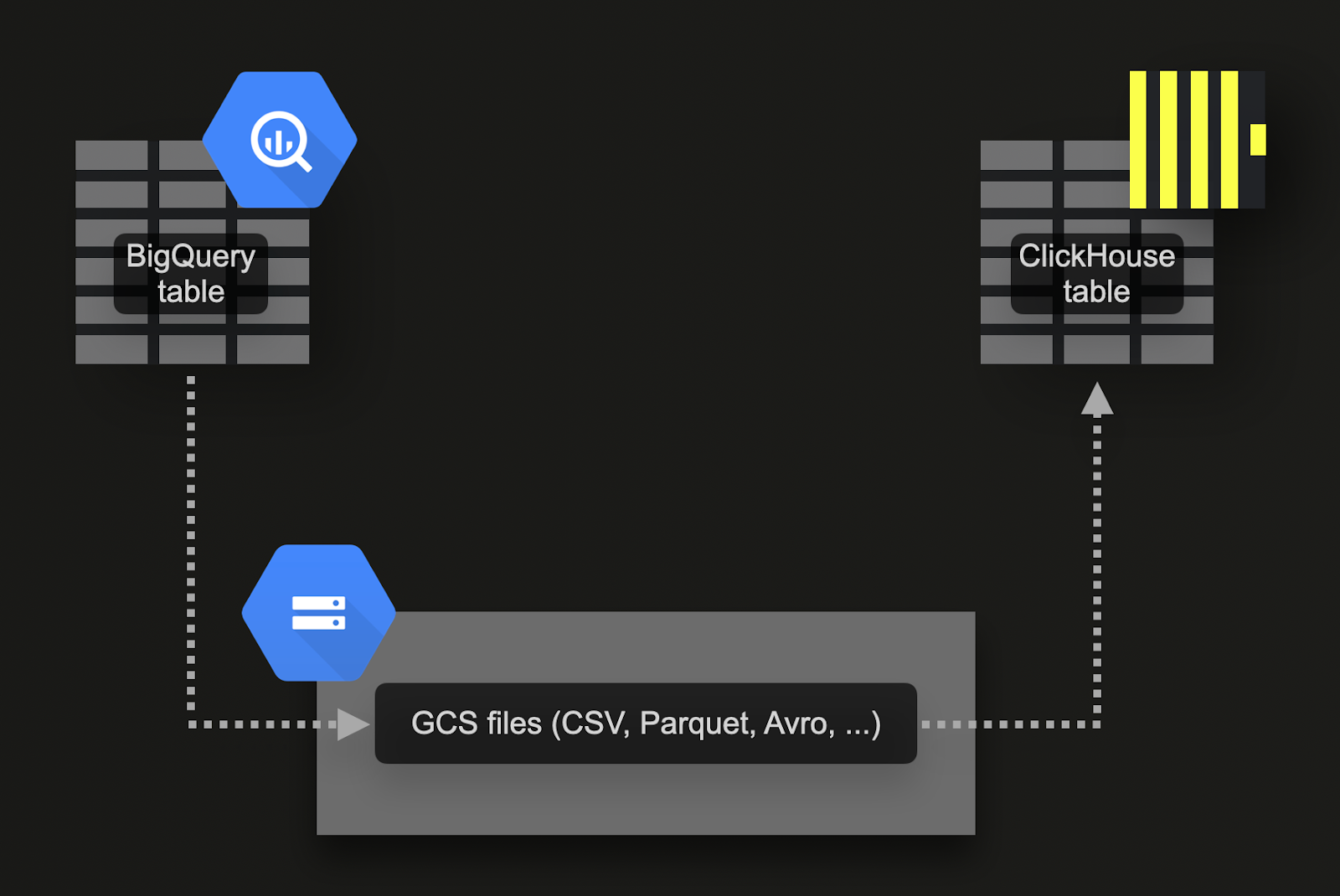
Массовая загрузка через Google Cloud Storage (GCS)
BigQuery поддерживает экспорт данных в объектное хранилище Google (GCS). Для нашего примерного набора данных:
-
Экспортируйте 7 таблиц в GCS. Команды для этого доступны здесь.
-
Импортируйте данные в ClickHouse Cloud. Для этого мы можем использовать табличную функцию gcs. Команды DDL и запросы импорта доступны здесь. Обратите внимание, что поскольку экземпляр ClickHouse Cloud состоит из нескольких вычислительных узлов, вместо табличной функции
gcsмы используем табличную функцию s3Cluster. Эта функция также работает с бакетами GCS и задействует все узлы сервиса ClickHouse Cloud для параллельной загрузки данных.
У этого подхода есть ряд преимуществ:
- Функциональность экспорта BigQuery поддерживает фильтр для экспорта подмножества данных.
- BigQuery поддерживает экспорт в форматы Parquet, Avro, JSON и CSV и несколько типов сжатия, все из которых поддерживаются ClickHouse.
- GCS поддерживает управление жизненным циклом объектов, что позволяет удалять данные, которые были экспортированы и импортированы в ClickHouse, по истечении заданного периода.
- Google позволяет бесплатно экспортировать до 50 ТБ в день в GCS. Пользователи платят только за хранилище GCS.
- Экспорт автоматически создает несколько файлов, ограничивая каждый максимум 1 ГБ данных таблицы. Это выгодно для ClickHouse, поскольку позволяет распараллеливать импорт.
Перед тем как пробовать следующие примеры, мы рекомендуем пользователям ознакомиться с требуемыми правами для экспорта и рекомендациями по локальности, чтобы максимизировать производительность экспорта и импорта.
Репликация в реальном времени или CDC с помощью запланированных запросов
CDC (фиксация изменений данных) — это процесс, который обеспечивает синхронизацию таблиц между двумя базами данных. Задача существенно усложняется, если требуется обрабатывать операции UPDATE и DELETE в режиме, близком к реальному времени. Один из подходов — просто настроить периодический экспорт, используя функциональность запланированных запросов BigQuery. При условии, что вы можете допустить некоторую задержку при вставке данных в ClickHouse, этот подход легко реализовать и сопровождать. Пример приведён в этой записи в блоге.
Проектирование схем
Набор данных Stack Overflow содержит ряд связанных таблиц. Рекомендуем сначала сосредоточиться на миграции основной таблицы. Это не обязательно самая большая таблица, а та, по которой вы ожидаете получать больше всего аналитических запросов. Это позволит вам познакомиться с основными концепциями ClickHouse. По мере добавления дополнительных таблиц структура этой таблицы может потребовать пересмотра, чтобы в полной мере использовать возможности ClickHouse и обеспечить оптимальную производительность. Мы рассматриваем этот процесс моделирования в нашей документации по моделированию данных.
Следуя этому принципу, мы сосредотачиваемся на основной таблице posts. Схема BigQuery для неё показана ниже:
Оптимизация типов
Применение процесса, описанного здесь, приводит к следующей схеме:
Мы можем заполнить эту таблицу с помощью простого оператора INSERT INTO SELECT, считывая экспортированные данные из gcs с помощью табличной функции gcs. Обратите внимание, что в ClickHouse Cloud вы также можете использовать совместимую с gcs табличную функцию s3Cluster для распараллеливания загрузки между несколькими узлами:
Мы не храним значения NULL в нашей новой схеме. Приведённая выше вставка неявно преобразует их в значения по умолчанию для соответствующих типов — 0 для целых чисел и пустую строку для строковых полей. ClickHouse также автоматически приводит любые числовые значения к нужной точности.
Чем отличаются первичные ключи в ClickHouse?
Как описано здесь, так же, как и в BigQuery, ClickHouse не обеспечивает уникальность значений столбцов первичного ключа таблицы.
Аналогично кластеризации в BigQuery, данные таблицы ClickHouse хранятся на диске в порядке сортировки по столбцу(ам) первичного ключа. Этот порядок сортировки используется оптимизатором запросов, чтобы избежать повторной сортировки, минимизировать потребление памяти при выполнении JOIN и включать раннее завершение при использовании операторов LIMIT. В отличие от BigQuery, ClickHouse автоматически создает разреженный (sparse) первичный индекс на основе значений столбцов первичного ключа. Этот индекс используется для ускорения всех запросов, содержащих фильтры по столбцам первичного ключа. В частности:
- Эффективное использование памяти и диска имеет первостепенное значение при масштабах, на которых часто используется ClickHouse. Данные записываются в таблицы ClickHouse блоками, называемыми частями (parts), к которым применяются правила фонового слияния. В ClickHouse у каждой части есть свой собственный первичный индекс. Когда части сливаются, их первичные индексы также объединяются. Обратите внимание, что эти индексы не строятся для каждой строки. Вместо этого первичный индекс для части содержит одну индексную запись на группу строк — такая техника называется разреженным индексированием.
- Разреженное индексирование возможно, потому что ClickHouse хранит строки для части на диске в порядке, определяемом указанным ключом. Вместо прямого поиска отдельных строк (как в индексах на основе B-деревьев) разреженный первичный индекс позволяет быстро (через двоичный поиск по индексным записям) находить группы строк, которые потенциально могут соответствовать запросу. Найденные группы потенциально подходящих строк затем параллельно передаются в движок ClickHouse для поиска совпадений. Такая архитектура индекса позволяет сделать первичный индекс небольшим (он полностью помещается в оперативной памяти), при этом существенно ускоряя выполнение запросов, особенно диапазонных, которые типичны для аналитических сценариев. Для получения более подробной информации рекомендуем это подробное руководство.
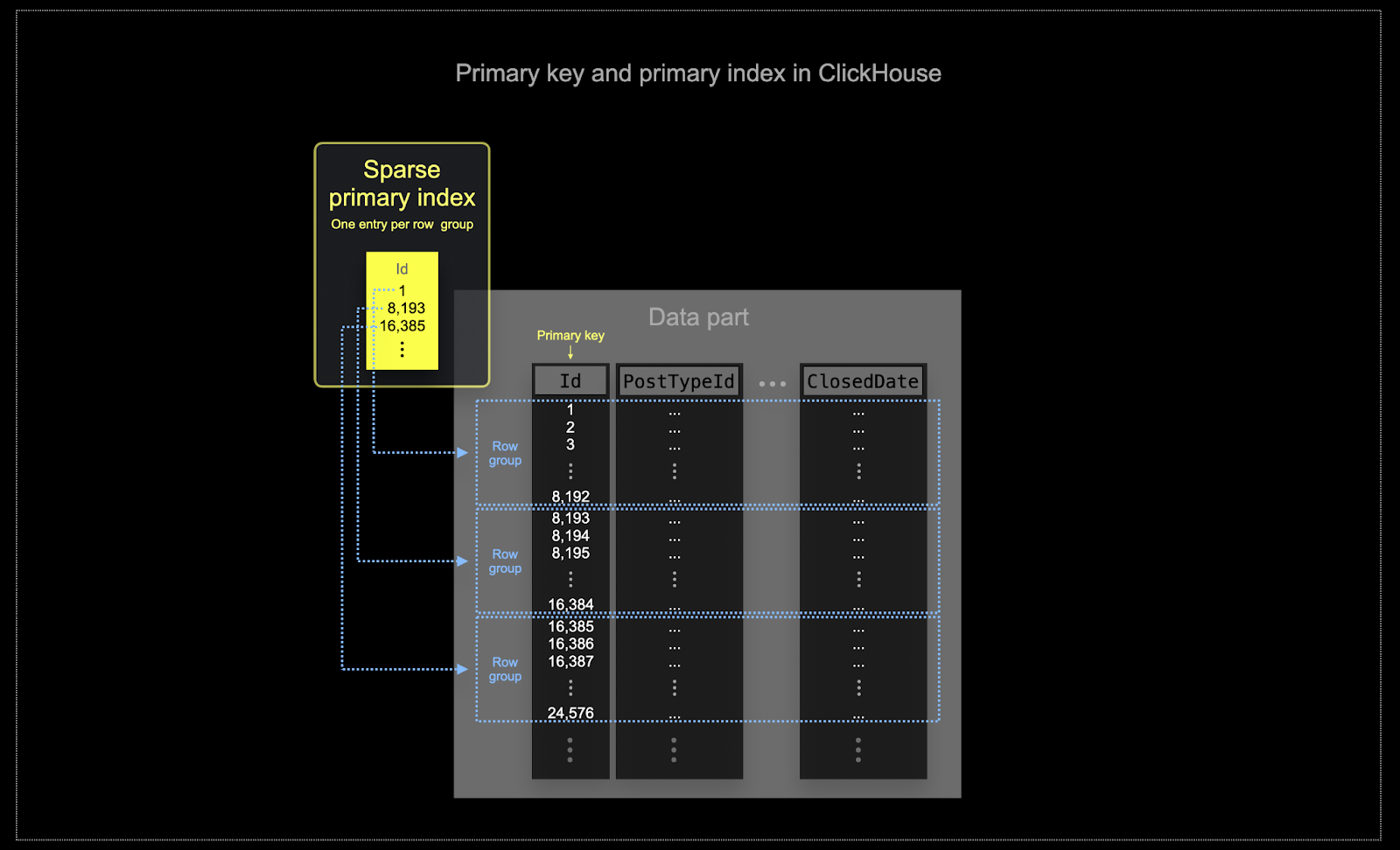
Выбранный первичный ключ в ClickHouse определяет не только индекс, но и порядок, в котором данные записываются на диск. Из‑за этого он может существенно влиять на степень сжатия, что, в свою очередь, сказывается на производительности запросов. Ключ упорядочивания, который приводит к тому, что значения большинства столбцов записываются в непрерывном порядке, позволит выбранному алгоритму сжатия (и кодекам) более эффективно сжимать данные.
Все столбцы в таблице будут отсортированы на основе значения указанного ключа упорядочивания, независимо от того, включены ли они в сам ключ. Например, если в качестве ключа используется
CreationDate, порядок значений во всех остальных столбцах будет соответствовать порядку значений в столбцеCreationDate. Можно указать несколько ключей упорядочивания — упорядочивание будет выполняться по тем же правилам, что и предложениеORDER BYв запросеSELECT.
Выбор ключа упорядочивания
Соображения и шаги по выбору ключа упорядочивания на примере таблицы posts приведены здесь.
Подходы к моделированию данных
Мы рекомендуем пользователям, мигрирующим с BigQuery, ознакомиться с руководством по моделированию данных в ClickHouse. В этом руководстве используется тот же набор данных Stack Overflow и рассматриваются несколько подходов с использованием возможностей ClickHouse.
Партиционирование
Пользователи BigQuery знакомы с концепцией партиционирования таблиц, которая повышает производительность и управляемость крупных баз данных за счёт деления таблиц на более мелкие, удобные для управления части, называемые партициями. Такое партиционирование может осуществляться с использованием диапазона по заданному столбцу (например, по датам), определённых списков или хеша по ключу. Это позволяет администраторам организовывать данные на основе конкретных критериев, таких как диапазоны дат или географическое расположение.
Партиционирование помогает повышать производительность запросов за счёт более быстрого доступа к данным посредством отсечения партиций (partition pruning) и более эффективного индексирования. Оно также упрощает задачи обслуживания, такие как резервное копирование и очистка данных, позволяя выполнять операции над отдельными партициями, а не над всей таблицей. Кроме того, партиционирование может существенно повысить масштабируемость баз данных BigQuery за счёт распределения нагрузки между несколькими партициями.
В ClickHouse партиционирование задаётся для таблицы при её создании с помощью выражения PARTITION BY. В этом выражении может использоваться SQL-выражение по любым столбцам, результат которого определяет, в какую партицию будет помещена строка.
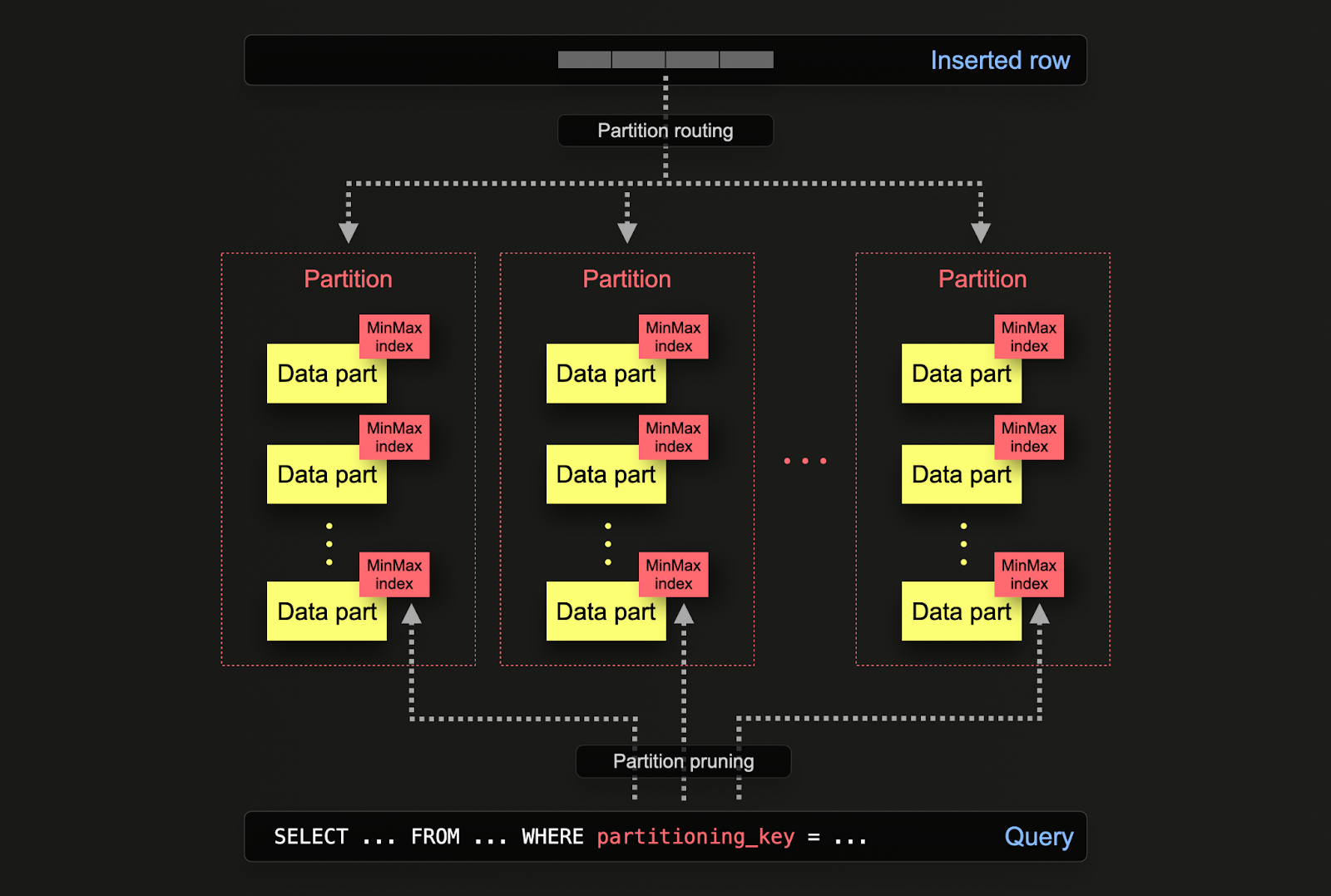
Части данных логически связаны с каждой партицией на диске и могут запрашиваться изолированно. В примере ниже мы партиционируем таблицу posts по году, используя выражение toYear(CreationDate). По мере вставки строк в ClickHouse это выражение будет вычисляться для каждой строки — затем строки направляются в соответствующую партицию в виде новых частей данных, принадлежащих этой партиции.
Применение
Разбиение на разделы (partitioning) в ClickHouse имеет сходные области применения с BigQuery, но и некоторые тонкие отличия. В частности:
- Управление данными — в ClickHouse пользователям в первую очередь следует рассматривать разбиение на разделы как механизм управления данными, а не как технику оптимизации запросов. При логическом разделении данных по ключу каждый раздел может обрабатываться независимо, например, удаляться. Это позволяет пользователям перемещать разделы, а значит и подмножества данных, между уровнями хранилища в зависимости от времени хранения или настраивать автоматическое удаление данных/эффективно удалять их из кластера. В приведённом ниже примере мы удаляем записи за 2008 год:
- Оптимизация запросов - Хотя партиционирование может способствовать повышению производительности запросов, это сильно зависит от паттернов доступа. Если запросы обращаются только к нескольким партициям (идеально — к одной), производительность может потенциально улучшиться. Это обычно полезно только в том случае, если ключ партиционирования не входит в первичный ключ и вы фильтруете по нему. Однако запросы, которым необходимо охватить множество партиций, могут работать хуже, чем без партиционирования (так как в результате партиционирования может образоваться больше частей данных). Преимущество обращения только к одной партиции будет менее выраженным вплоть до полного отсутствия, если ключ партиционирования уже является одним из первых столбцов первичного ключа. Партиционирование также может использоваться для оптимизации запросов с
GROUP BY, если значения в каждой партиции уникальны. Однако, в целом, пользователям следует в первую очередь убедиться, что первичный ключ оптимизирован, и рассматривать партиционирование как технику оптимизации запросов только в исключительных случаях, когда паттерны доступа охватывают конкретное предсказуемое подмножество суток, например, партиционирование по дню при большинстве запросов за последний день.
Рекомендации
Пользователям следует рассматривать партиционирование как технику управления данными. Оно идеально подходит, когда данные необходимо удалять из кластера при работе с временными рядами, например, самую старую партицию можно просто удалить.
Важно: Убедитесь, что выражение ключа партиционирования не приводит к множеству высокой кардинальности, то есть следует избегать создания более 100 партиций. Например, не выполняйте партиционирование данных по столбцам с высокой кардинальностью, таким как идентификаторы клиентов или имена. Вместо этого сделайте идентификатор клиента или имя первым столбцом в выражении ORDER BY.
Внутри ClickHouse создаются части для вставляемых данных. По мере вставки всё большего объёма данных количество частей увеличивается. Чтобы предотвратить чрезмерно большое количество частей, что ухудшит производительность запросов (так как нужно читать больше файлов), части сливаются в фоновом асинхронном процессе. Если количество частей превышает предварительно настроенный предел, то ClickHouse выбросит исключение при вставке как ошибку "too many parts". Этого не должно происходить при нормальной эксплуатации и возникает только если ClickHouse неправильно сконфигурирован или используется некорректно, например, при большом количестве мелких вставок. Поскольку части создаются по партиции изолированно, увеличение числа партиций приводит к росту количества частей, то есть оно является кратным количеству партиций. Ключи партиционирования с высокой кардинальностью, таким образом, могут вызывать эту ошибку и их следует избегать.
Материализованные представления и проекции
Концепция проекций в ClickHouse позволяет задавать для одной таблицы несколько вариантов ORDER BY.
В разделе моделирование данных в ClickHouse мы рассматриваем, как материализованные представления можно использовать в ClickHouse для предварительного вычисления агрегаций, преобразования строк и оптимизации запросов для различных сценариев доступа к данным. В последнем случае мы привели пример, где материализованное представление отправляет строки в целевую таблицу с иным ключом сортировки по сравнению с исходной таблицей, в которую выполняются вставки.
Например, рассмотрим следующий запрос:
Этот запрос требует сканирования всех 90 млн строк (пусть и быстро), так как UserId
не является ключом сортировки. Ранее мы решали это с помощью материализованного представления,
используемого как справочник для PostId. Ту же задачу можно решить с помощью проекции.
Команда ниже добавляет проекцию с ORDER BY user_id.
Обратите внимание, что сначала необходимо создать проекцию, а затем материализовать её. Эта последняя команда приводит к тому, что данные хранятся на диске дважды, в двух разных порядках. Проекцию также можно задать при создании данных, как показано ниже, и она будет автоматически поддерживаться в актуальном состоянии по мере вставки данных.
Если проекция создаётся с помощью команды ALTER, её создание выполняется асинхронно
при выполнении команды MATERIALIZE PROJECTION. Пользователи могут проверить ход выполнения
этой операции с помощью следующего запроса, ожидая, пока is_done=1.
Если мы повторно выполним приведённый выше запрос, мы увидим, что производительность значительно улучшилась ценой дополнительного расхода места в хранилище.
С помощью команды EXPLAIN мы также можем убедиться, что проекция была использована для обработки этого запроса:
┌─explain─────────────────────────────────────────────┐
- │ Выражение ((Projection + перед ORDER BY)) │
- │ Агрегирование │
- │ Фильтр │
- │ ReadFromMergeTree (comments_user_id) │
- │ Индексы: │
- │ PrimaryKey │
- │ Ключи: │
- │ UserId │
- │ Условие: (UserId in [8592047, 8592047]) │
- │ Части: 2/2 │
- │ Гранулы: 2/11360 │ └─────────────────────────────────────────────────────┘
11 строк в наборе. Затрачено: 0.004 сек.
Переписывание запросов BigQuery на ClickHouse
Ниже приведены примеры запросов для сравнения BigQuery и ClickHouse. Этот список призван показать, как использовать возможности ClickHouse для значительного упрощения запросов. В примерах используется полный набор данных Stack Overflow (до апреля 2024 года включительно).
Пользователи (с более чем 10 вопросами), которые набирают больше всего просмотров:
BigQuery
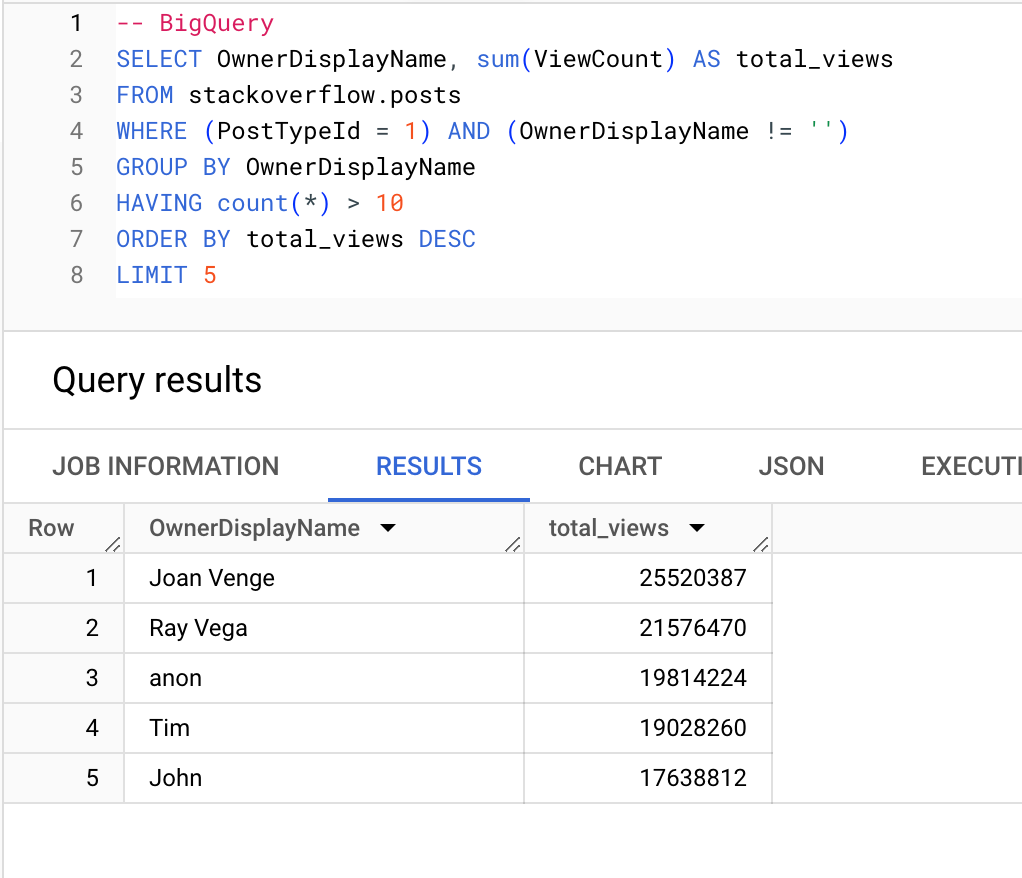
ClickHouse
Какие теги набирают больше всего просмотров:
BigQuery
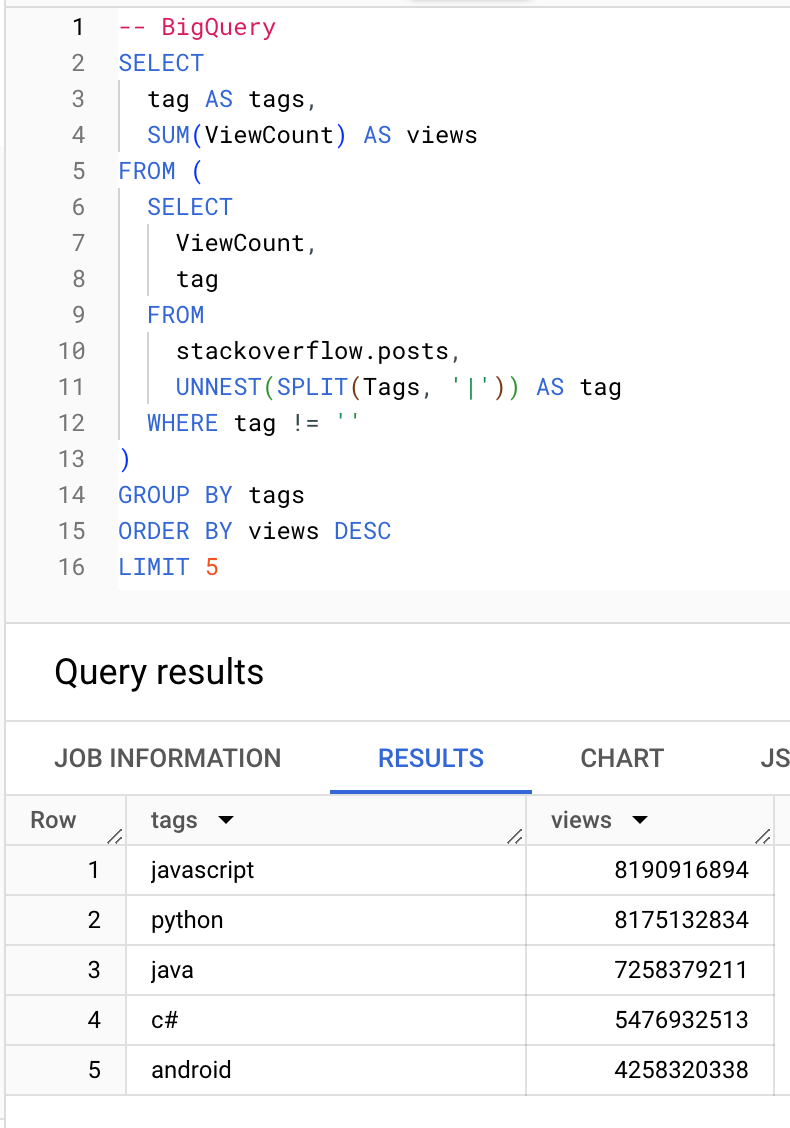
ClickHouse
Агрегатные функции
Где это возможно, пользователям следует использовать агрегатные функции ClickHouse. Ниже показано использование функции argMax для вычисления самого просматриваемого вопроса за каждый год.
BigQuery
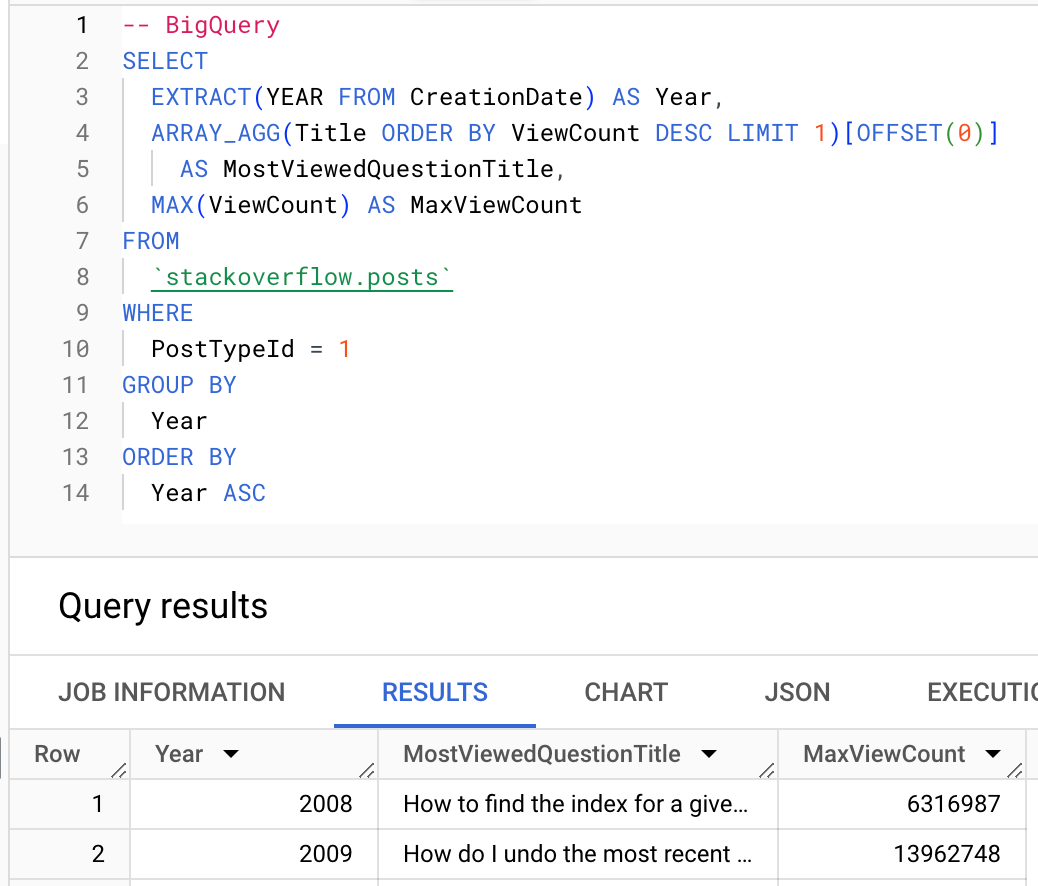

ClickHouse
Условные выражения и массивы
Условные выражения и функции для работы с массивами значительно упрощают запросы. Следующий запрос вычисляет теги (встречающиеся более 10 000 раз) с наибольшим процентным ростом с 2022 по 2023 год. Обратите внимание, насколько лаконичен следующий запрос ClickHouse благодаря условным выражениям, функциям для работы с массивами и возможности повторно использовать псевдонимы в предложениях HAVING и SELECT.
BigQuery
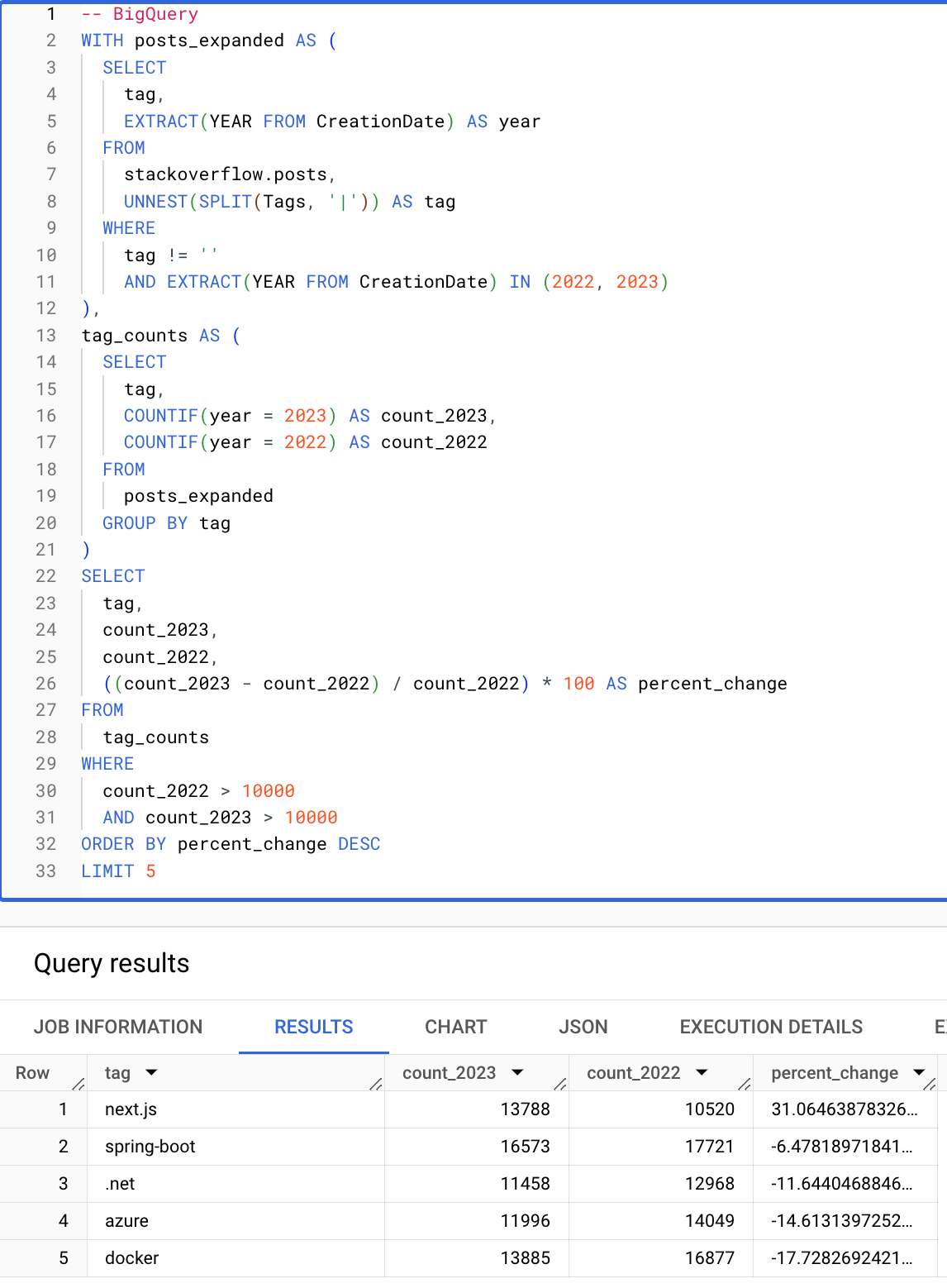
ClickHouse
На этом заканчивается наше базовое руководство для пользователей, переходящих с BigQuery на ClickHouse. Мы рекомендуем таким пользователям ознакомиться с руководством по моделированию данных в ClickHouse, чтобы узнать больше о расширенных возможностях ClickHouse.
