Дозагрузка данных
Независимо от того, являетесь ли вы новым пользователем ClickHouse или отвечаете за существующее развертывание, рано или поздно вам потребуется дозагрузить в таблицы исторические данные. В некоторых случаях это относительно просто, но может становиться сложнее, когда нужно заполнить материализованные представления. В этом руководстве описаны некоторые подходы к решению этой задачи, которые пользователи могут адаптировать под свои сценарии.
В этом руководстве предполагается, что пользователи уже знакомы с концепцией инкрементных материализованных представлений и загрузки данных с использованием табличных функций, таких как S3 и GCS. Мы также рекомендуем ознакомиться с нашим руководством по оптимизации производительности вставки из объектного хранилища, рекомендации из которого можно применять к операциям вставки во всех примерах этого руководства.
Пример набора данных
Во всём этом руководстве мы используем набор данных PyPI. Каждая строка в этом наборе данных представляет загрузку Python‑пакета с использованием такого инструмента, как pip.
Например, этот поднабор охватывает один день — 2024-12-17 — и доступен в открытом доступе по адресу https://datasets-documentation.s3.eu-west-3.amazonaws.com/pypi/2024-12-17/. Пользователи могут выполнять запросы с помощью:
Полный набор данных для этого бакета содержит более 320 ГБ файлов Parquet. В примерах ниже мы намеренно выбираем подмножества с помощью glob-шаблонов.
Мы предполагаем, что пользователь получает поток этих данных, например из Kafka или объектного хранилища, начиная с этой даты. Схема этих данных показана ниже.
Полный набор данных PyPI, состоящий более чем из 1 триллиона строк, доступен в нашем публичном демонстрационном окружении clickpy.clickhouse.com. Дополнительные сведения об этом наборе данных, включая то, как демо использует материализованные представления для повышения производительности и как данные ежедневно загружаются, см. здесь.
Сценарии дозаполнения данных задним числом
Дозаполнение исторических данных обычно требуется, когда потребление потока данных начинается с определённого момента времени. Эти данные вставляются в таблицы ClickHouse с помощью инкрементальных материализованных представлений, которые срабатывают на блоки данных по мере их вставки. Эти представления могут трансформировать данные перед вставкой или вычислять агрегаты и отправлять результаты в целевые таблицы для последующего использования в нижестоящих приложениях.
Мы рассмотрим следующие сценарии:
- Дозаполнение исторических данных при существующей ингестии данных — загружаются новые данные, и необходимо дозаполнить исторические данные. Эти исторические данные уже определены.
- Добавление материализованных представлений к существующим таблицам — необходимо добавить новые материализованные представления к конфигурации, для которой исторические данные уже загружены и поток данных уже идёт.
Мы предполагаем, что исторические данные будут дозаполняться из объектного хранилища. Во всех случаях мы стремимся избежать пауз во вставке данных.
Мы рекомендуем дозаполнять исторические данные из объектного хранилища. Данные по возможности следует экспортировать в формат Parquet для оптимальной производительности чтения и сжатия (уменьшения сетевого трафика). Размер файла порядка 150 МБ обычно является предпочтительным, однако ClickHouse поддерживает более 70 форматов файлов и может обрабатывать файлы любого размера.
Использование дублирующих таблиц и представлений
Во всех сценариях мы опираемся на концепцию «дублирующих таблиц и представлений». Эти таблицы и представления являются копиями тех, что используются для потоковых данных в реальном времени, и позволяют выполнять backfill (дозагрузку данных задним числом) изолированно, с простым механизмом восстановления в случае сбоя. Например, у нас есть следующая основная таблица pypi и материализованное представление, которое вычисляет количество загрузок для каждого Python‑проекта:
Мы заполняем основную таблицу и связанное представление подмножеством данных:
Предположим, мы хотим загрузить другое подмножество {101..200}. Хотя мы могли бы вставлять данные напрямую в pypi, мы можем выполнить этот бэкфилл изолированно, создав дублирующие таблицы.
Если этот бэкфилл завершится неудачно, мы не затронем наши основные таблицы и сможем просто очистить дублирующие таблицы и повторить попытку.
Чтобы создать новые копии этих представлений, мы можем использовать конструкцию CREATE TABLE AS с суффиксом _v2:
Мы заполняем его вторым подмножеством примерно такого же размера и убеждаемся, что загрузка прошла успешно.
Если бы мы столкнулись с ошибкой на любом этапе второй загрузки, мы могли бы просто очистить таблицы pypi_v2 и pypi_downloads_v2 и повторить загрузку данных.
После завершения загрузки данных мы можем переместить данные из дублирующих таблиц в основные таблицы с помощью оператора ALTER TABLE MOVE PARTITION.
Приведённый выше вызов MOVE PARTITION использует имя партиции (). Оно соответствует единственной партиции для этой таблицы (которая не разбита на партиции). Для таблиц, которые разбиты на партиции, потребуется выполнить несколько вызовов MOVE PARTITION — по одному для каждой партиции. Имена текущих партиций можно получить из таблицы system.parts, например: SELECT DISTINCT partition FROM system.parts WHERE (table = 'pypi_v2').
Теперь мы можем убедиться, что pypi и pypi_downloads содержат все данные. Таблицы pypi_downloads_v2 и pypi_v2 можно безопасно удалить.
Важно, что операция MOVE PARTITION одновременно лёгковесна (использует жёсткие ссылки) и атомарна, т.е. либо завершается успешно, либо с ошибкой, без промежуточного состояния.
Мы активно используем этот подход в описанных ниже сценариях дозагрузки данных (backfilling).
Обратите внимание, что этот процесс требует от пользователей выбора размера каждой операции вставки.
Более крупные вставки, т.е. больше строк, означают, что потребуется меньше операций MOVE PARTITION. Однако это необходимо сбалансировать с затратами на восстановление в случае сбоя вставки, например из‑за обрыва сети. Пользователи могут дополнить этот процесс пакетной обработкой файлов для снижения риска. Это можно выполнять либо с помощью диапазонных запросов, например WHERE timestamp BETWEEN 2024-12-17 09:00:00 AND 2024-12-17 10:00:00, либо с помощью glob-шаблонов. Например,
ClickPipes использует этот подход при загрузке данных из объектного хранилища, автоматически создавая дубликаты целевой таблицы и её материализованных представлений и избавляя пользователя от необходимости выполнять описанные выше шаги. Дополнительно, за счёт использования нескольких рабочих потоков, каждый из которых обрабатывает свои подмножества данных (через glob-шаблоны) и использует собственные дубликаты таблиц, данные могут загружаться быстро с соблюдением семантики «ровно один раз». Заинтересованные читатели могут найти дополнительные подробности в этой статье блога.
Сценарий 1: Дозагрузка данных при существующей ингестии данных
В этом сценарии мы предполагаем, что данные для дозагрузки не находятся в отдельном бакете, поэтому требуется фильтрация. Данные уже вставляются, и можно определить метку времени или монотонно возрастающий столбец, начиная с которого необходимо выполнить дозагрузку исторических данных.
Этот процесс включает следующие шаги:
- Определить контрольную точку — либо метку времени, либо значение столбца, начиная с которого необходимо восстановить исторические данные.
- Создать дубликаты основной таблицы и целевых таблиц для материализованных представлений.
- Создать копии всех материализованных представлений, которые ссылаются на целевые таблицы, созданные на шаге (2).
- Вставить данные в дублирующую основную таблицу, созданную на шаге (2).
- Переместить все партиции из дублирующих таблиц в их исходные таблицы. Удалить дублирующие таблицы.
Например, в наших данных PyPI предположим, что данные уже загружены. Мы можем определить минимальную метку времени и, таким образом, нашу «контрольную точку».
Из сказанного выше мы знаем, что нам нужно загрузить данные с временными метками до 2024-12-17 09:00:00. Используя описанный ранее процесс, мы создаём дубликаты таблиц и представлений и загружаем подмножество данных с помощью фильтра по временной метке.
Фильтрация по столбцам с временными метками в Parquet может быть очень эффективной. ClickHouse будет читать только столбец с временными метками, чтобы определить полные диапазоны данных для загрузки, минимизируя сетевой трафик. Индексы Parquet, такие как min-max, также могут использоваться движком выполнения запросов ClickHouse.
После завершения операции вставки мы можем переместить соответствующие партиции.
Если исторические данные находятся в отдельном bucket-е, описанный выше фильтр по времени не требуется. Если временного или монотонного столбца нет, изолируйте исторические данные.
Пользователям ClickHouse Cloud следует использовать ClickPipes для восстановления исторических резервных копий, если данные можно изолировать в отдельном bucket-е (и фильтр не требуется). Помимо параллельной загрузки несколькими воркерами, что уменьшает время загрузки, ClickPipes автоматизирует описанный выше процесс — создаёт дубликаты таблиц как для основной таблицы, так и для материализованных представлений.
Сценарий 2: Добавление материализованных представлений к существующим таблицам
Нередко возникает необходимость добавить новые материализованные представления в конфигурацию, для которой уже накоплен значительный объём данных и продолжается вставка. В этом случае полезен столбец с меткой времени или монотонно возрастающим значением, который можно использовать для идентификации точки в потоке, что позволяет избежать пауз в ингестии данных. В примерах ниже мы рассматриваем оба случая, отдавая предпочтение подходам, которые позволяют избежать пауз в ингестии.
Мы не рекомендуем использовать команду POPULATE для заполнения задним числом материализованных представлений, за исключением небольших наборов данных, для которых приём приостановлен. Этот оператор может пропускать строки, вставленные в исходную таблицу, если материализованное представление создаётся после завершения выполнения POPULATE. Кроме того, эта операция выполняется по всем данным и уязвима к прерываниям или ограничениям по памяти на больших наборах данных.
Наличие столбца с меткой времени или монотонно возрастающим значением
В этом случае мы рекомендуем включить в новое материализованное представление фильтр, который ограничивает строки теми, что больше некоторого произвольного значения в будущем. Затем материализованное представление можно заполнить задним числом, начиная с этой даты, используя исторические данные из основной таблицы. Подход к такому заполнению зависит от объёма данных и сложности соответствующего запроса.
Наш самый простой подход включает следующие шаги:
- Создать материализованное представление с фильтром, который учитывает только строки, большие некоторого произвольного момента времени в ближайшем будущем.
- Выполнить запрос
INSERT INTO SELECT, который вставляет данные в целевую таблицу нашего материализованного представления, читая из исходной таблицы с использованием агрегирующего запроса представления.
Данный подход можно дополнительно улучшить, нацеливаясь на подмножества данных на шаге (2) и/или используя дубликат целевой таблицы для материализованного представления (прикрепляя партиции к исходной после завершения вставки) для упрощения восстановления после сбоев.
Рассмотрим следующее материализованное представление, которое рассчитывает самые популярные проекты за каждый час.
Хотя мы уже можем добавить целевую таблицу, перед добавлением материализованного представления мы изменяем выражение SELECT, чтобы включить фильтр, который учитывает только строки с временем больше некоторого произвольного момента в ближайшем будущем — в данном случае мы предполагаем, что 2024-12-17 09:00:00 наступит через несколько минут.
После добавления этого представления мы можем задним числом дозагрузить все данные для материализованного представления до этого момента.
Самый простой способ сделать это — выполнить запрос материализованного представления по основной таблице с фильтром, который игнорирует недавно добавленные данные, вставив результаты в целевую таблицу нашего представления с помощью INSERT INTO SELECT. Например, для приведённого выше представления:
В приведённом выше примере целевой таблицей служит SummingMergeTree. В этом случае мы можем просто использовать исходный запрос агрегации. Для более сложных сценариев, в которых используется AggregatingMergeTree, следует применять функции -State для агрегирования. Пример такого подхода можно найти здесь.
В нашем случае это относительно лёгкая агрегация, которая завершается менее чем за 3 секунды и использует менее 600MiB памяти. Для более сложных или длительных агрегаций пользователи могут сделать этот процесс более устойчивым, используя ранее описанный подход с дублирующей таблицей, то есть создать теневую целевую таблицу, например pypi_downloads_per_day_v2, выполнять вставку в неё и затем присоединять получившиеся партиции к pypi_downloads_per_day.
Часто запрос материализованного представления может быть более сложным (что нередко, иначе пользователи не стали бы использовать представление!) и потреблять значительные ресурсы. В более редких случаях ресурсов, необходимых для выполнения запроса, может не хватать мощности сервера. Это подчёркивает одно из преимуществ материализованных представлений в ClickHouse — они обновляются инкрементально и не обрабатывают весь набор данных за один проход!
В этом случае у пользователей есть несколько вариантов:
- Модифицировать запрос для дозаполнения по диапазонам, например
WHERE timestamp BETWEEN 2024-12-17 08:00:00 AND 2024-12-17 09:00:00,WHERE timestamp BETWEEN 2024-12-17 07:00:00 AND 2024-12-17 08:00:00и т. д. - Использовать движок таблиц Null для заполнения материализованного представления. Это имитирует типичное инкрементальное наполнение материализованного представления, выполняя его запрос над блоками данных (настраиваемого размера).
Вариант (1) является самым простым подходом и часто достаточен. Мы не приводим примеры ради краткости.
Вариант (2) рассматривается подробнее ниже.
Использование движка таблиц Null для заполнения материализованных представлений
Движок таблиц Null предоставляет движок хранения, который не сохраняет данные (думайте о нём как о /dev/null в мире движков таблиц). Хотя это может казаться противоречивым, материализованные представления всё равно будут выполняться над данными, вставляемыми в этот движок таблиц. Это позволяет создавать материализованные представления без сохранения исходных данных — избегая I/O и связанного с этим хранения.
Важно, что любые материализованные представления, прикреплённые к этому движку таблиц, продолжают выполняться над блоками данных по мере их вставки, отправляя результаты в целевую таблицу. Размер этих блоков настраивается. Более крупные блоки потенциально могут быть более эффективными (и быстрее обрабатываться), но они потребляют больше ресурсов (в первую очередь памяти). Использование этого движка таблиц означает, что мы можем строить наше материализованное представление инкрементально, то есть по одному блоку за раз, избегая необходимости удерживать всю агрегацию в памяти.
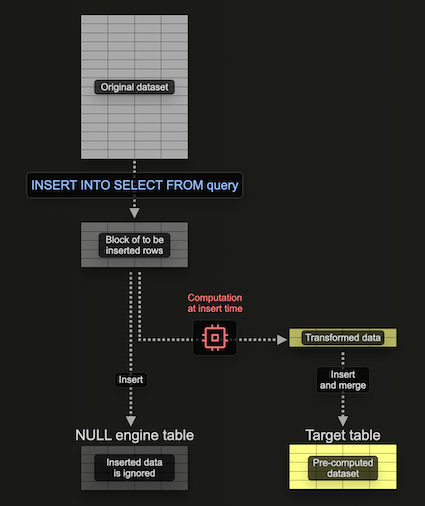
Рассмотрим следующий пример:
Здесь мы создаем таблицу с движком Null pypi_v2, чтобы принимать строки, которые будут использованы для построения нашего материализованного представления. Обратите внимание, что мы ограничиваем схему только теми столбцами, которые нам нужны. Наше материализованное представление выполняет агрегацию по строкам, вставленным в эту таблицу (по одному блоку за раз), отправляя результаты в нашу целевую таблицу pypi_downloads_per_day.
В качестве целевой таблицы мы используем здесь pypi_downloads_per_day. Для повышения отказоустойчивости пользователи могут создать дубликат таблицы pypi_downloads_per_day_v2 и использовать ее в качестве целевой таблицы представления, как показано в предыдущих примерах. По завершении вставки разделы в pypi_downloads_per_day_v2 могут, в свою очередь, быть перенесены в pypi_downloads_per_day. Это позволит выполнить восстановление в случае, если вставка завершится сбоем из‑за проблем с памятью или прерывания работы сервера, т.е. мы просто очищаем pypi_downloads_per_day_v2, настраиваем параметры и повторяем попытку.
Чтобы заполнить это материализованное представление, мы просто вставляем соответствующие данные для догрузки (backfill) в pypi_v2 из pypi.
Обратите внимание, что здесь использование памяти составляет 639.47 MiB.
Настройка производительности и ресурсов
На производительность и потребление ресурсов в описанном выше сценарии влияет несколько факторов. Перед тем как приступать к настройке, мы рекомендуем ознакомиться с механикой вставки, подробно описанной в разделе Using Threads for Reads руководства Optimizing for S3 Insert and Read Performance. Вкратце:
- Параллелизм чтения (Read Parallelism) — количество потоков, используемых для чтения. Управляется через
max_threads. В ClickHouse Cloud определяется размером экземпляра, по умолчанию равным количеству vCPU. Увеличение этого значения может улучшить производительность чтения за счет большего потребления памяти. - Параллелизм вставки (Insert Parallelism) — количество потоков, используемых для вставки данных. Управляется через
max_insert_threads. В ClickHouse Cloud определяется размером экземпляра (между 2 и 4), а в OSS по умолчанию равно 1. Увеличение этого значения может улучшить производительность за счет большего потребления памяти. - Размер блока вставки (Insert Block Size) — данные обрабатываются в цикле: они извлекаются, парсятся и формируются в блоки вставки в памяти на основе ключа партиционирования. Эти блоки сортируются, оптимизируются, сжимаются и записываются в хранилище как новые части данных. Размер блока вставки, управляемый настройками
min_insert_block_size_rowsиmin_insert_block_size_bytes(в несжатом виде), влияет на использование памяти и дисковый ввод-вывод. Более крупные блоки потребляют больше памяти, но создают меньше частей, снижая I/O и объем фоновых слияний. Эти настройки задают минимальные пороговые значения (как только достигается любое из них, инициируется сброс). - Размер блока для материализованного представления (Materialized view block size) — помимо описанной выше механики основной вставки, перед вставкой в материализованные представления блоки также укрупняются для более эффективной обработки. Размер этих блоков определяется настройками
min_insert_block_size_bytes_for_materialized_viewsиmin_insert_block_size_rows_for_materialized_views. Более крупные блоки позволяют более эффективно обрабатывать данные за счет большего потребления памяти. По умолчанию эти настройки наследуют значения настроек исходной таблицыmin_insert_block_size_rowsиmin_insert_block_size_bytesсоответственно.
Для улучшения производительности пользователи могут следовать рекомендациям, изложенным в разделе Tuning Threads and Block Size for Inserts руководства Optimizing for S3 Insert and Read Performance. В большинстве случаев нет необходимости дополнительно изменять min_insert_block_size_bytes_for_materialized_views и min_insert_block_size_rows_for_materialized_views для повышения производительности. Если вы все же изменяете эти параметры, применяйте те же рекомендуемые практики, которые описаны для min_insert_block_size_rows и min_insert_block_size_bytes.
Чтобы минимизировать потребление памяти, пользователи могут поэкспериментировать с этими настройками. Это неизбежно снизит производительность. Используя предыдущий запрос, ниже мы приводим примеры.
Уменьшение значения max_insert_threads до 1 снижает накладные расходы по памяти.
Мы можем дополнительно снизить потребление памяти, уменьшив значение параметра max_threads до 1.
Наконец, мы можем ещё больше сократить потребление памяти, установив min_insert_block_size_rows равным 0 (что отключает использование этого параметра при определении размера блока) и min_insert_block_size_bytes равным 10485760 (10 МиБ).
Наконец, имейте в виду, что уменьшение размеров блоков приводит к большему числу кусков и вызывает более сильную нагрузку на процесс слияний. Как обсуждается здесь, эти настройки следует изменять с осторожностью.
Отсутствует столбец с меткой времени или монотонно возрастающий столбец
Описанные выше процессы предполагают, что в таблице есть столбец с меткой времени или монотонно возрастающий столбец. В некоторых случаях он просто отсутствует. В этом случае мы рекомендуем следующий процесс, который использует многие из шагов, описанных ранее, но требует от пользователей приостановить приём данных.
- Приостановите вставки в основную таблицу.
- Создайте дубликат основной целевой таблицы, используя синтаксис
CREATE AS. - Присоедините партиции из исходной целевой таблицы к дубликату, используя
ALTER TABLE ATTACH. Примечание: Эта операция присоединения отличается от ранее использованной операции перемещения. Хотя она и использует жёсткие ссылки, данные в исходной таблице сохраняются. - Создайте новые материализованные представления.
- Возобновите вставки. Примечание: Вставки будут обновлять только целевую таблицу, а не дубликат, который будет ссылаться только на исходные данные.
- Выполните дозагрузку данных в материализованное представление, применив тот же процесс, что и выше для данных с метками времени, используя дубликат таблицы в качестве источника.
Рассмотрим следующий пример с использованием PyPI и нашего ранее созданного нового материализованного представления pypi_downloads_per_day (будем считать, что мы не можем использовать метку времени):
DROP TABLE pypi_v2;
