Выбор первичного ключа
На этой странице мы используем термин "ordering key" взаимозаменяемо с термином "primary key". Строго говоря, в ClickHouse они различаются, но в рамках этого документа читатели могут считать их синонимами, при этом под ordering key подразумеваются столбцы, указанные в
ORDER BYтаблицы.
Обратите внимание, что primary key в ClickHouse работает совершенно иначе, чем это обычно понимают пользователи OLTP-баз данных, таких как Postgres.
Выбор эффективного primary key в ClickHouse имеет критически важное значение для производительности запросов и эффективности хранения. ClickHouse организует данные в части, каждая из которых содержит собственный разреженный первичный индекс. Этот индекс существенно ускоряет запросы, уменьшая объём сканируемых данных. Кроме того, поскольку primary key определяет физический порядок данных на диске, он напрямую влияет на эффективность сжатия. Оптимально упорядоченные данные сжимаются эффективнее, что дополнительно повышает производительность за счёт сокращения операций ввода-вывода (I/O).
- При выборе ordering key отдавайте приоритет столбцам, которые часто используются в фильтрах запросов (то есть в
WHERE-условиях), особенно тем, которые исключают большое количество строк. - Столбцы, сильно коррелированные с другими данными в таблице, также полезны, поскольку непрерывное размещение данных улучшает коэффициенты сжатия и эффективность использования памяти при операциях
GROUP BYиORDER BY.
Можно применить несколько простых правил, чтобы помочь выбрать ordering key. Следующие рекомендации могут иногда противоречить друг другу, поэтому учитывайте их по порядку. Пользователи могут определить несколько вариантов ключей с помощью этого процесса, при этом обычно достаточно 4–5:
Ordering keys должны быть определены при создании таблицы и не могут быть добавлены позже. Дополнительное упорядочение может быть добавлено в таблицу после (или до) вставки данных с помощью механизма под названием projections (проекции). Имейте в виду, что это приводит к дублированию данных. Подробности см. здесь.
Пример
Рассмотрим следующую таблицу posts_unordered. Она содержит по одной строке для каждого поста Stack Overflow.
У этой таблицы нет первичного ключа — на что указывает выражение ORDER BY tuple().
Предположим, что пользователь хочет вычислить число вопросов, отправленных после 2024 года, и это представляет собой его наиболее распространённый паттерн доступа.
Обратите внимание на количество строк и байт, прочитанных этим запросом. Без первичного ключа запросам приходится сканировать весь набор данных.
Использование EXPLAIN indexes=1 подтверждает полное сканирование таблицы из-за отсутствия индексации.
Предположим, что таблица posts_ordered, содержащая те же данные, определена с предложением ORDER BY (PostTypeId, toDate(CreationDate)), то есть:
PostTypeId имеет кардинальность 8 и является логичным выбором для первого столбца в нашем ключе сортировки. Понимая, что фильтрации по дате с такой гранулярностью, скорее всего, будет достаточно (она по‑прежнему принесёт пользу и при фильтрации по datetime), мы используем toDate(CreationDate) как второй компонент нашего ключа. Это также приведёт к меньшему индексу, поскольку дата может быть представлена 16 битами, что ускоряет фильтрацию.
Следующая анимация показывает, как создаётся оптимизированный разреженный первичный индекс для таблицы постов Stack Overflow. Вместо индексирования отдельных строк индекс строится по блокам строк:

Если один и тот же запрос повторно выполняется для таблицы с таким ключом сортировки:
┌─count()─┐ │ 192611 │ └─────────┘ --highlight-next-line 1 строка в наборе. Прошло: 0.013 сек. Обработано 196.53 тыс. строк, 1.77 МБ (14.64 млн строк/с., 131.78 МБ/с.)
Кроме того, мы наглядно показываем, как разреженный индекс отфильтровывает все блоки строк, которые не могут содержать совпадения для нашего примерного запроса:
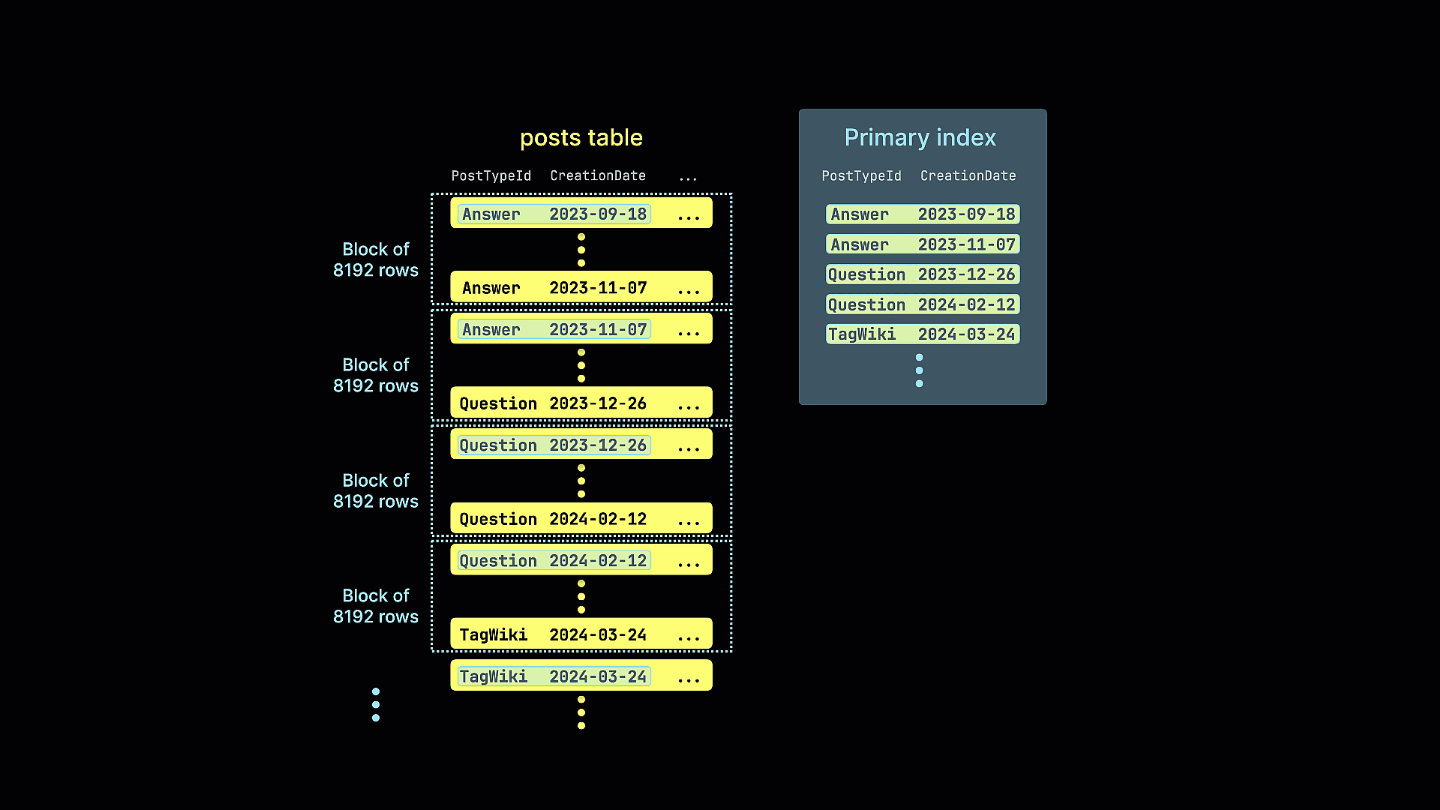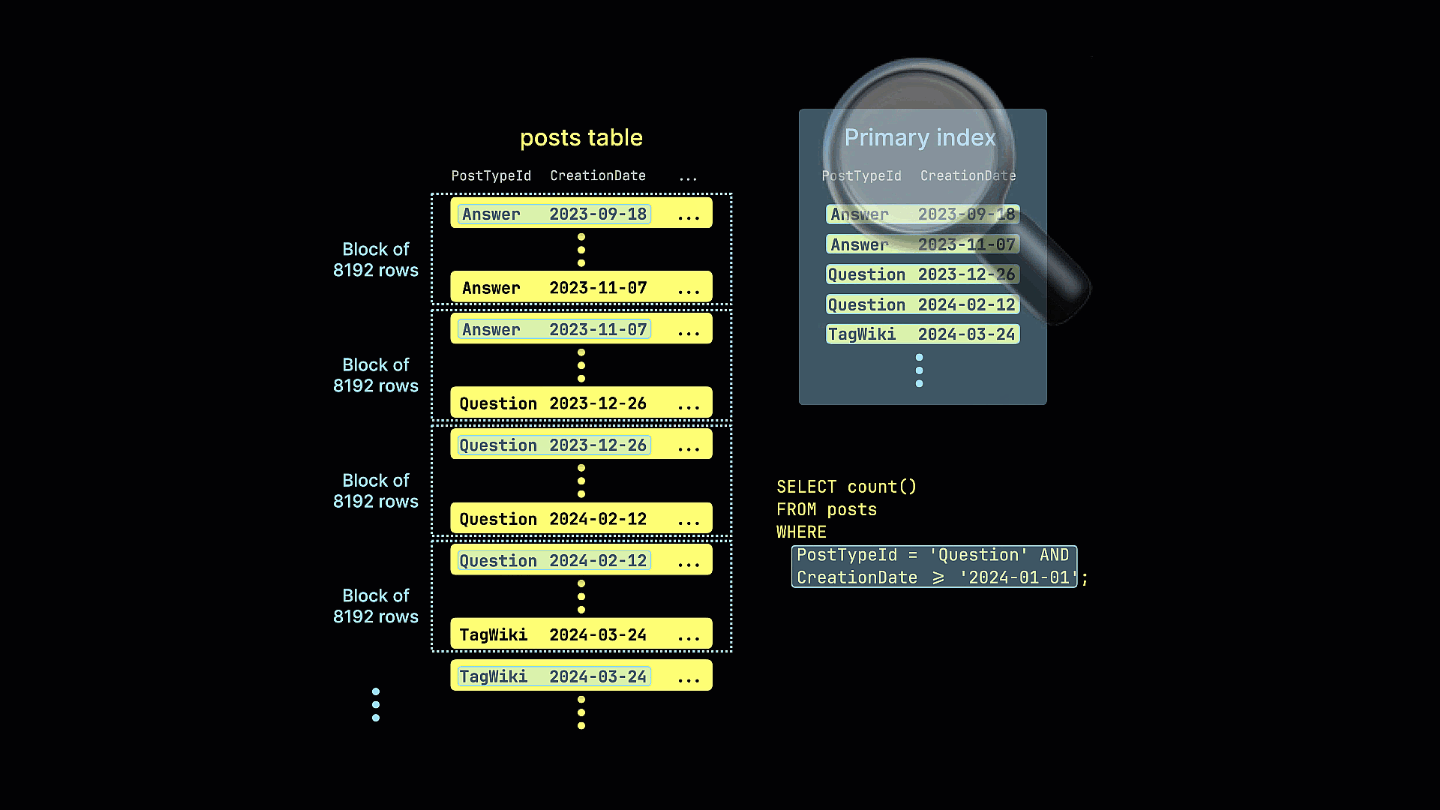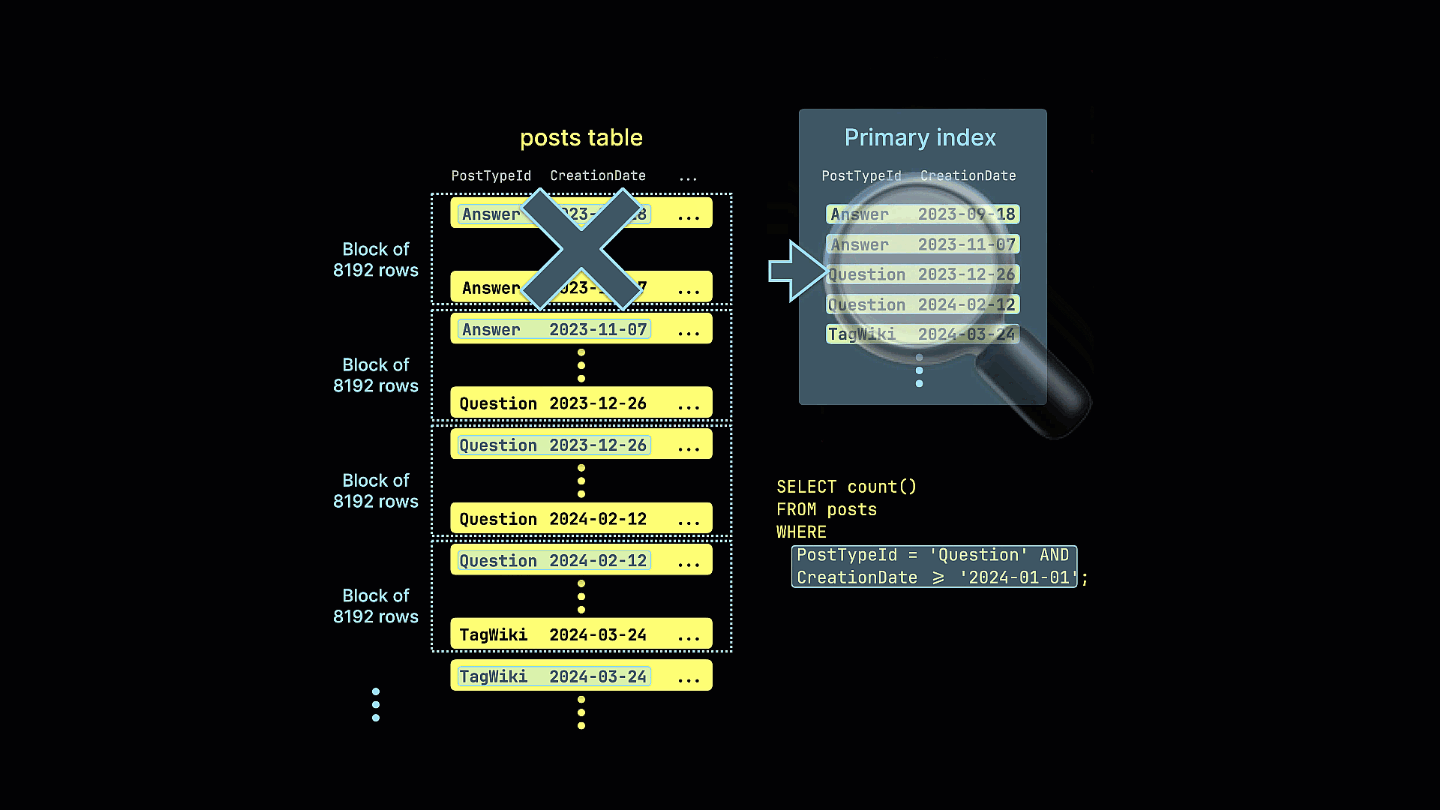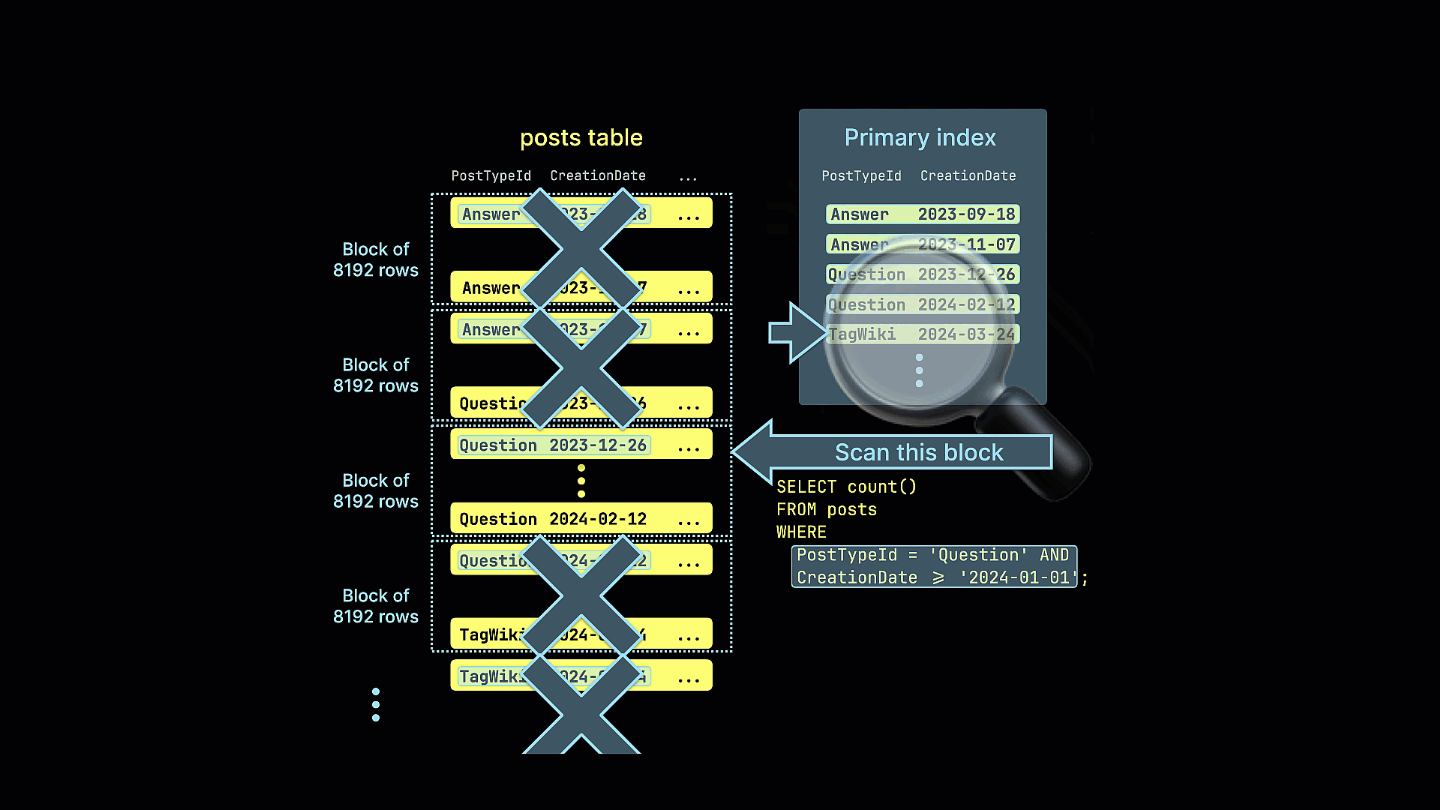
Все столбцы в таблице будут отсортированы на основе значения указанного ключа сортировки, независимо от того, включены ли они в сам ключ. Например, если в качестве ключа используется CreationDate, порядок значений во всех остальных столбцах будет соответствовать порядку значений в столбце CreationDate. Можно указать несколько ключей сортировки — в этом случае сортировка будет выполняться с той же семантикой, что и предложение ORDER BY в запросе SELECT.
Полное подробное руководство по выбору первичных ключей можно найти здесь.
Для более глубокого понимания того, как ключи сортировки улучшают сжатие и дополнительно оптимизируют хранение, ознакомьтесь с официальными руководствами Compression in ClickHouse и Column Compression Codecs.
