Что такое индексы пропуска данных в ClickHouse
Введение
На производительность запросов в ClickHouse влияет множество факторов. Критическим элементом в большинстве сценариев является то, может ли ClickHouse использовать первичный ключ при вычислении условия WHERE запроса. Соответственно, выбор первичного ключа, который соответствует наиболее распространённым паттернам запросов, жизненно важен для эффективного проектирования таблиц.
Тем не менее, независимо от того, насколько тщательно настроен первичный ключ, неизбежно появятся сценарии запросов, которые не смогут эффективно его использовать. Пользователи часто используют ClickHouse для хранения данных временных рядов, но при этом нередко хотят анализировать те же данные по другим бизнес-измерениям, таким как идентификатор клиента, URL веб-сайта или номер продукта. В таком случае производительность запросов может существенно ухудшиться, поскольку для применения условия WHERE может потребоваться полное сканирование значений каждого столбца. Хотя в этих условиях ClickHouse остаётся относительно быстрым, обработка миллионов или миллиардов отдельных значений приведёт к тому, что «неиндексированные» запросы будут выполняться значительно медленнее, чем те, что опираются на первичный ключ.
В традиционной реляционной базе данных одним из подходов к решению этой проблемы является добавление к таблице одного или нескольких «вторичных» индексов. Это структура типа b-tree, которая позволяет базе данных находить все соответствующие строки на диске за время O(log(n)) вместо O(n) (полное сканирование таблицы), где n — это количество строк. Однако такой тип вторичного индекса не будет работать для ClickHouse (или других колоночных баз данных), потому что на диске нет отдельных строк, которые можно было бы добавить в индекс.
Вместо этого ClickHouse предоставляет другой тип индекса, который при определённых обстоятельствах может значительно повысить скорость выполнения запросов. Эти структуры называются индексами пропуска (skip indexes), поскольку они позволяют ClickHouse пропускать чтение значительных блоков данных, которые гарантированно не содержат подходящих значений.
Базовый принцип работы
Пользователи могут использовать индексы пропуска данных (Data Skipping Indexes) только для таблиц семейства MergeTree. Каждый индекс пропуска данных имеет четыре основных аргумента:
- Имя индекса. Имя индекса используется для создания файла индекса в каждом разделе. Также оно требуется как параметр при удалении или материализации индекса.
- Выражение индекса. Выражение индекса используется для вычисления набора значений, сохраняемых в индексе. Это может быть комбинация столбцов, простых операторов и/или подмножества функций, определяемых типом индекса.
- TYPE. Тип индекса определяет способ вычислений, который позволяет решить, можно ли пропустить чтение и вычисление каждого индексного блока.
- GRANULARITY. Каждый индексируемый блок состоит из GRANULARITY гранул. Например, если гранулярность первичного индекса таблицы — 8192 строки, а гранулярность индекса — 4, каждый индексируемый «блок» будет содержать 32768 строк.
Когда пользователь создает индекс пропуска данных, в каталоге каждой части данных таблицы появятся два дополнительных файла.
skp_idx_{index_name}.idx, который содержит упорядоченные значения выраженияskp_idx_{index_name}.mrk2, который содержит соответствующие смещения в связанные файлы столбцов данных.
Если некоторая часть условия фильтрации в предложении WHERE соответствует выражению индекса пропуска данных при выполнении запроса и чтении соответствующих файлов столбцов, ClickHouse использует данные файла индекса, чтобы определить, должен ли каждый соответствующий блок данных быть обработан или его можно пропустить (при условии, что блок еще не был исключен применением первичного ключа). Для очень упрощенного примера рассмотрим следующую таблицу, заполненную предсказуемыми данными.
При выполнении простого запроса без использования первичного ключа сканируются все 100 миллионов записей столбца my_value:
Теперь добавьте самый простой пропускающий индекс:
Обычно пропускающие индексы применяются только к вновь вставленным данным, поэтому само по себе добавление индекса не повлияет на приведённый выше запрос.
Чтобы проиндексировать уже существующие данные, используйте следующий запрос:
Повторно выполните запрос, используя только что созданный индекс:
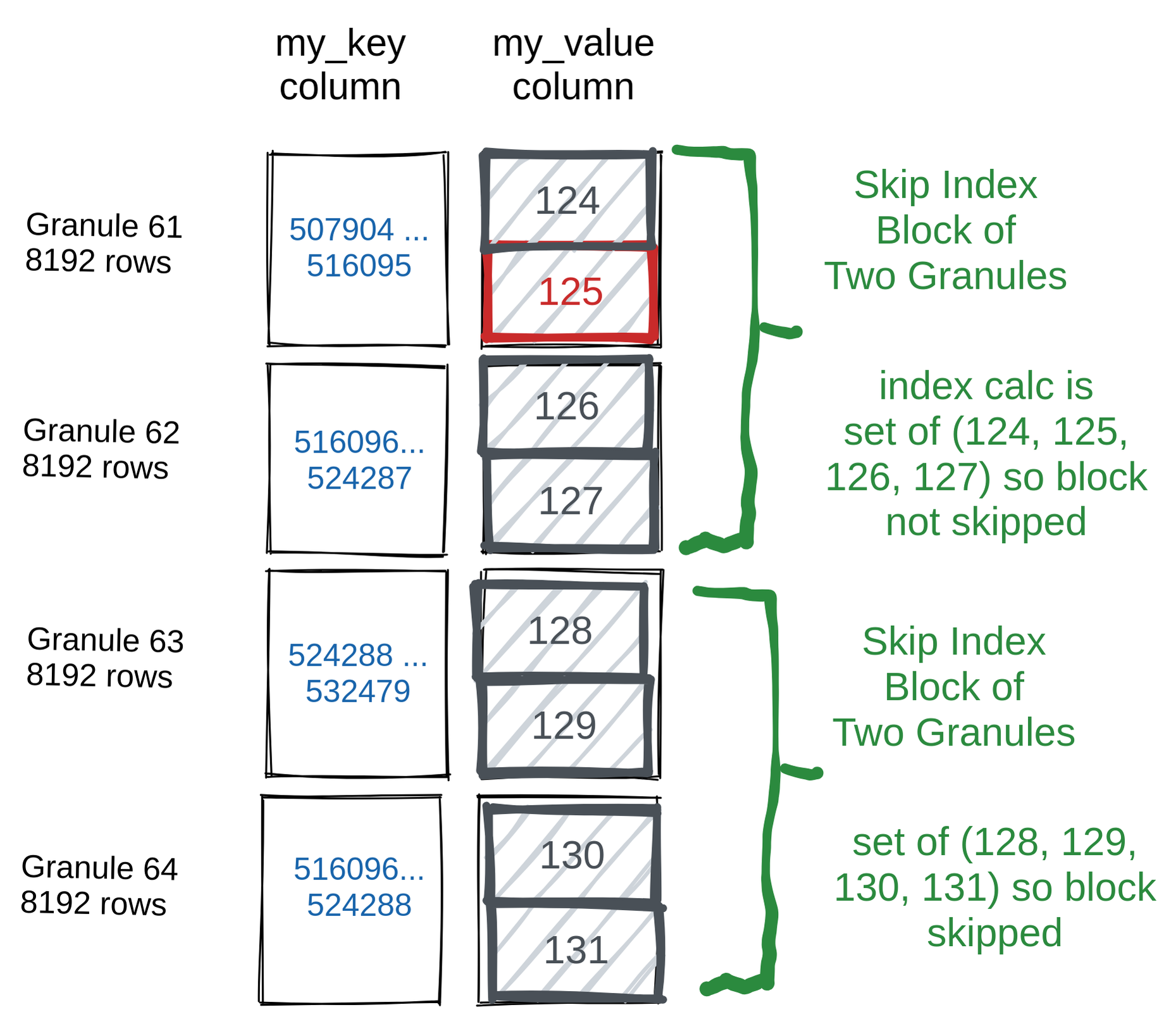
Вместо обработки 100 миллионов строк общим объемом 800 мегабайт ClickHouse прочитал и проанализировал только 32768 строк объемом 360 килобайт — четыре гранулы по 8192 строки каждая.
В более наглядной форме на схеме ниже показано, как были прочитаны и выбраны 4096 строк с my_value, равным 125, и как последующие строки
были пропущены без чтения с диска:
Пользователи могут получить подробную информацию об использовании индексов пропуска, включив трассировку при выполнении запросов. Из
clickhouse-client установите send_logs_level:
Это позволит получить полезную отладочную информацию при настройке SQL‑запроса и индексов таблицы. Из приведённого выше примера видно, что в отладочном логе указано, что индекс пропуска (skip index) отбросил все гранулы, кроме двух:
Типы индексов пропуска данных
minmax
Этот легковесный тип индекса не требует параметров. Он сохраняет минимальное и максимальное значения индексного выражения для каждого блока (если выражение является кортежем, то отдельно сохраняет значения для каждого элемента кортежа). Этот тип идеально подходит для столбцов, значения в которых обычно лишь примерно отсортированы. Применение этого типа индекса, как правило, наименее затратно во время обработки запроса.
Этот тип индекса корректно работает только со скалярным или кортежным выражением — индекс никогда не будет применён к выражениям, которые возвращают массив или тип данных map.
SET
Этот легковесный тип индекса принимает один параметр — max_size, максимальный размер множества значений на блок (0 допускает неограниченное количество дискретных значений). Это множество содержит все значения в блоке (или является пустым, если количество значений превышает max_size). Этот тип индекса хорошо работает со столбцами с низкой кардинальностью в пределах каждого набора гранул (по сути, «сгруппированных вместе»), но с более высокой кардинальностью в целом.
Затраты, производительность и эффективность этого индекса зависят от кардинальности внутри блоков. Если каждый блок содержит большое количество уникальных значений, то либо вычисление условия запроса по большому набору индекса будет очень ресурсоёмким, либо индекс не будет применён, потому что он пуст из‑за превышения max_size.
Типы фильтров Блума
Фильтр Блума — это структура данных, которая позволяет эффективно по памяти проверять принадлежность к набору ценой небольшой вероятности ложноположительных результатов. Ложноположительные срабатывания не являются существенной проблемой в случае пропускающих индексов, поскольку единственный недостаток — чтение нескольких лишних блоков. Однако возможность ложноположительных срабатываний означает, что индексированное выражение, как правило, должно быть истинным, иначе часть корректных данных может быть пропущена.
Поскольку фильтры Блума могут более эффективно обрабатывать проверку большого количества дискретных значений, они могут подходить для условных выражений, которые порождают больше значений для проверки. В частности, индекс на основе фильтра Блума может быть применён к массивам, где проверяется каждое значение массива, и к ассоциативным массивам (Map), путём преобразования ключей или значений в массив с помощью функций mapKeys или mapValues.
Существует три типа Data Skipping Index на основе фильтров Блума:
-
Базовый bloom_filter, который принимает один необязательный параметр — допустимый уровень «ложноположительных» срабатываний от 0 до 1 (если не указан, используется .025).
-
Специализированный tokenbf_v1. Он принимает три параметра, все связаны с настройкой используемого фильтра Блума: (1) размер фильтра в байтах (большие фильтры дают меньше ложноположительных срабатываний, но требуют больше места), (2) количество применяемых хеш‑функций (опять же, больше хеш‑функций уменьшает число ложноположительных срабатываний) и (3) seed для хеш‑функций фильтра Блума. См. калькулятор здесь для более подробной информации о том, как эти параметры влияют на работу фильтра Блума. Этот индекс работает только с типами данных String, FixedString и Map. Входное выражение разбивается на последовательности символов, разделённые неалфанумерическими символами. Например, значение столбца
This is a candidate for a "full text" searchбудет содержать токеныThisisacandidateforfulltextsearch. Он предназначен для использования в поиске по LIKE, EQUALS, IN, hasToken() и подобных поисках слов и других значений внутри более длинных строк. Например, одним из вариантов использования может быть поиск небольшого количества имён классов или номеров строк в столбце с произвольными строками журналов приложения. -
Специализированный ngrambf_v1. Этот индекс работает так же, как токен‑индекс. Он принимает один дополнительный параметр перед настройками фильтра Блума — размер n‑грамм для индексирования. N‑грамма — это строка символов длины
nиз любых символов, поэтому строкаA short stringс размером n‑граммы 4 будет индексироваться как:
Этот индекс также может быть полезен для текстового поиска, особенно для языков без разделителей слов, таких как китайский.
Функции индексов пропуска данных
Основная цель индексов пропуска данных — ограничить объём данных, анализируемых популярными запросами. Учитывая аналитический характер данных ClickHouse, такие запросы в большинстве случаев включают функциональные выражения. Соответственно, индексы пропуска данных должны корректно взаимодействовать с распространёнными функциями, чтобы быть эффективными. Это возможно в двух случаях:
- данные вставляются, и индекс определяется как функциональное выражение (с результатом выражения, сохраняемым в индексных файлах), или
- запрос обрабатывается, и выражение применяется к сохранённым значениям индекса для определения, следует ли исключить блок.
Каждый тип индекса пропуска данных работает с подмножеством доступных функций ClickHouse, соответствующим реализации индекса, перечисленной здесь. В общем случае set-индексы и индексы на основе Bloom-фильтра (ещё один тип set-индекса) неупорядочены и поэтому не работают с диапазонами. Напротив, minmax-индексы особенно хорошо работают с диапазонами, поскольку определение того, пересекаются ли диапазоны, выполняется очень быстро. Эффективность функций частичного совпадения LIKE, startsWith, endsWith и hasToken зависит от используемого типа индекса, индексного выражения и конкретной структуры данных.
Настройки индексов пропуска данных
Существует две настройки, которые применяются к индексам пропуска данных.
- use_skip_indexes (0 или 1, по умолчанию 1). Не все запросы могут эффективно использовать индексы пропуска данных. Если конкретное условие фильтрации, скорее всего, включает большинство гранул, применение индекса пропуска данных приводит к ненужным и иногда значительным накладным расходам. Установите значение 0 для запросов, которые с высокой вероятностью не получат выгоды от использования индексов пропуска данных.
- force_data_skipping_indices (список имён индексов, разделённых запятыми). Эта настройка может использоваться для предотвращения некоторых видов неэффективных запросов. В ситуациях, когда выполнение запроса к таблице слишком дорого без использования индекса пропуска данных, указание одного или нескольких имён индексов в этой настройке приведёт к возникновению исключения для любого запроса, который не использует перечисленные индексы. Это позволяет предотвратить потребление ресурсов сервера неэффективно написанными запросами.
Рекомендации по использованию skip index
Skip-индексы неочевидны, особенно для пользователей, привыкших к вторичным строковым индексам из мира СУБД или инвертированным индексам из документных хранилищ. Чтобы получить от них пользу, применение индекса пропуска данных (data skipping index) в ClickHouse должно позволять избежать достаточного количества чтений гранул, чтобы компенсировать стоимость вычисления индекса. Критически важно, что если значение встречается хотя бы один раз в индексируемом блоке, это означает, что весь блок должен быть считан в память и обработан, а затраты на вычисление индекса окажутся напрасными.
Рассмотрим следующее распределение данных:
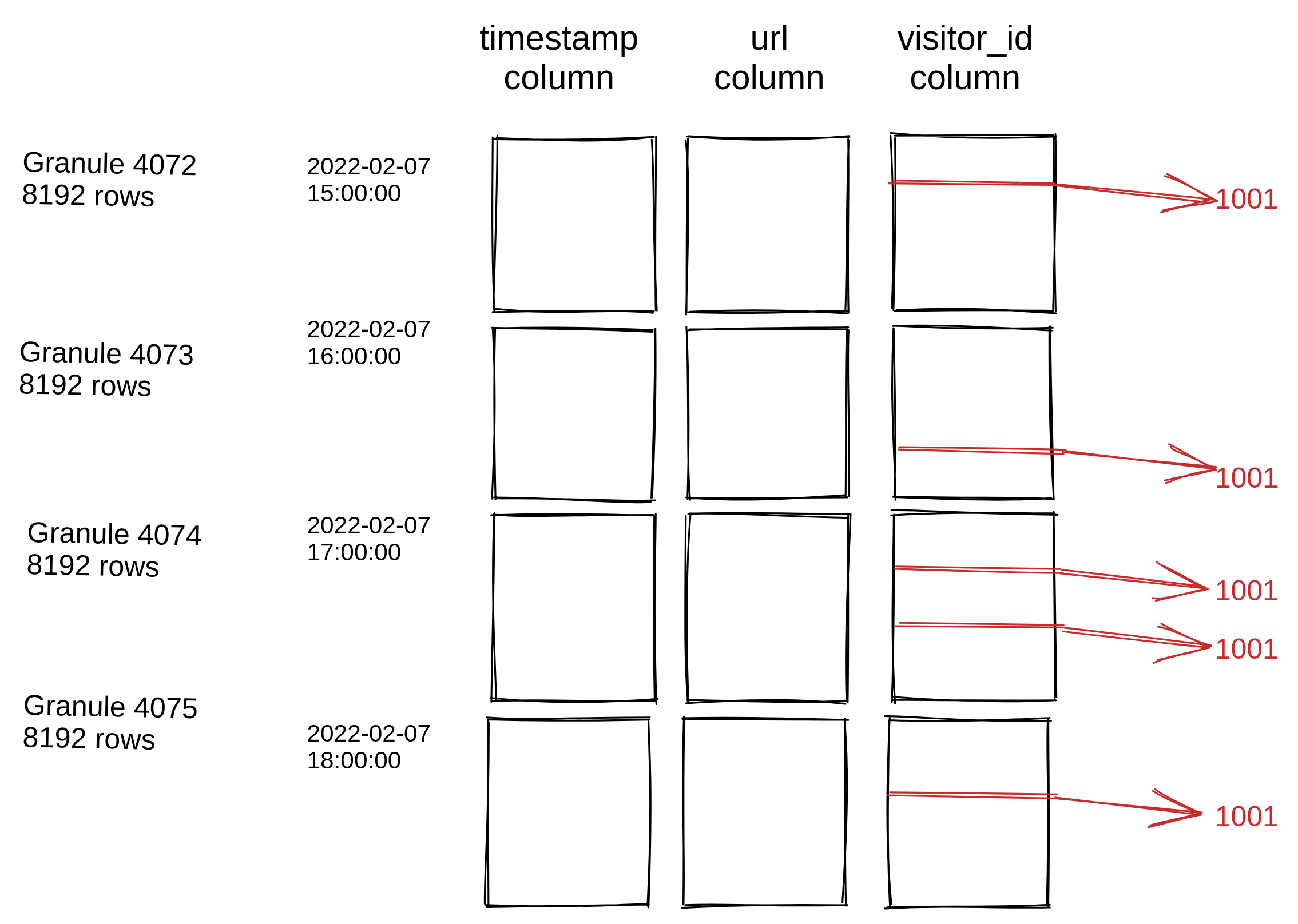
Предположим, что первичный ключ/ключ ORDER BY — это timestamp, и существует индекс по visitor_id. Рассмотрим следующий запрос:
Традиционный вторичный индекс был бы очень полезен при таком распределении данных. Вместо чтения всех 32768 строк для поиска
5 строк с запрошенным visitor_id, вторичный индекс содержал бы лишь пять указателей на строки, и с диска были бы прочитаны
только эти пять строк. Для индекса пропуска данных ClickHouse верно прямо противоположное. Все 32768 значений в столбце visitor_id будут проверены
независимо от типа индекса пропуска.
Соответственно, естественное желание ускорить запросы ClickHouse простым добавлением индекса к ключевым столбцам часто оказывается ошибочным. Эта расширенная функциональность должна использоваться только после изучения других вариантов, таких как изменение первичного ключа (см. How to Pick a Primary Key), использование проекций или материализованных представлений. Даже когда индекс пропуска данных уместен, часто требуется тщательная настройка и индекса, и таблицы.
В большинстве случаев полезный индекс пропуска требует сильной корреляции между первичным ключом и целевым неключевым столбцом/выражением. Если корреляции нет (как на приведённой выше схеме), вероятность того, что условие фильтрации будет выполнено хотя бы одной из строк в блоке из нескольких тысяч значений, высока, и будет пропущено мало блоков. Напротив, если диапазон значений первичного ключа (например, время суток) сильно связан со значениями в потенциальном индексируемом столбце (например, возраст зрителей телевидения), то индекс типа minmax скорее всего будет полезен. Обратите внимание, что эту корреляцию иногда можно усилить на этапе вставки данных — либо включая дополнительные столбцы в ключ сортировки/ORDER BY, либо пакетируя вставки таким образом, чтобы значения, связанные с первичным ключом, группировались при вставке. Например, все события для конкретного site_id могут быть сгруппированы и вставлены вместе процессом приёма, даже если первичный ключ — это метка времени, содержащая события для большого числа сайтов. Это приведёт к тому, что многие гранулы будут содержать лишь несколько значений site_id, поэтому много блоков может быть пропущено при поиске по конкретному значению site_id.
Ещё один хороший кандидат для индекса пропуска — это выражения с высокой кардинальностью, в которых любое отдельное значение относительно разрежено в данных. Например, это может быть платформа наблюдаемости, которая отслеживает коды ошибок в API‑запросах. Определённые коды ошибок, хотя и редки в данных, могут быть особенно важны для поиска. Индекс пропуска типа set по столбцу error_code позволит обходить подавляющее большинство блоков, которые не содержат ошибок, и, следовательно, существенно ускорит запросы, ориентированные на ошибки.
Наконец, главное практическое правило — тестировать, тестировать и ещё раз тестировать. Вновь отметим: в отличие от вторичных индексов b-tree или инвертированных индексов для поиска по документам, поведение индекса пропуска данных не всегда легко предсказать. Их добавление к таблице влечёт за собой заметные издержки как при приёме данных, так и при выполнении запросов, которые по ряду причин не получают выгоды от индекса. Их всегда следует тестировать на данных, близких к реальным, а тестирование должно включать вариации типа, размера гранулы и других параметров. Тестирование часто выявляет закономерности и подводные камни, которые неочевидны исключительно из мысленных экспериментов.
