Интеграция OpenTelemetry для сбора данных
Любому решению в области наблюдаемости необходим механизм сбора и экспорта логов и трассировок. Для этой цели ClickHouse рекомендует проект OpenTelemetry (OTel).
«OpenTelemetry — это фреймворк и набор инструментов для наблюдаемости, предназначенный для создания и управления телеметрическими данными, такими как трассировки, метрики и логи».
В отличие от ClickHouse или Prometheus, OpenTelemetry не является серверным хранилищем (backend) для наблюдаемости, а сосредоточен на генерации, сборе, управлении и экспорте телеметрических данных. Хотя изначальной целью OpenTelemetry было упростить пользователям инструментирование своих приложений или систем с помощью специализированных для конкретных языков SDKS, его функциональность была расширена и теперь включает сбор логов через OpenTelemetry Collector — агент или прокси, который принимает, обрабатывает и экспортирует телеметрические данные.
Компоненты, относящиеся к ClickHouse
OpenTelemetry состоит из ряда компонентов. Помимо предоставления спецификации данных и API, стандартизированного протокола и соглашений об именовании полей/столбцов, OTel предоставляет две возможности, которые являются фундаментальными для построения решения по наблюдаемости на базе ClickHouse:
- OpenTelemetry Collector — это прокси-сервер, который принимает, обрабатывает и экспортирует телеметрию. Решение на базе ClickHouse использует этот компонент как для сбора логов, так и для обработки событий перед формированием пакетов и вставкой данных.
- Language SDKs, которые реализуют спецификацию, API и экспорт телеметрических данных. Эти SDKS фактически обеспечивают корректную запись трассировок в коде приложения, генерируя составляющие спаны и гарантируя распространение контекста между сервисами через метаданные — тем самым формируя распределённые трассировки и обеспечивая возможность коррелировать спаны. Эти SDKS дополняются экосистемой, которая автоматически интегрирует распространённые библиотеки и фреймворки, благодаря чему пользователю не требуется изменять свой код и он получает инструментализацию «из коробки».
Решение по наблюдаемости на базе ClickHouse использует оба этих инструмента.
Дистрибутивы
Коллектор OpenTelemetry имеет ряд дистрибутивов. Ресивер filelog вместе с ClickHouse-экспортером, необходимыми для решения на базе ClickHouse, присутствуют только в дистрибутиве OpenTelemetry Collector Contrib.
Этот дистрибутив содержит множество компонентов и позволяет пользователям экспериментировать с различными конфигурациями. Однако при работе в продакшене рекомендуется ограничить коллектор только компонентами, необходимыми для конкретного окружения. Некоторые причины для этого:
- Уменьшить размер коллектора, сократив время его развертывания
- Повысить безопасность коллектора за счет сокращения доступной поверхности атаки
Собрать кастомный коллектор можно с помощью OpenTelemetry Collector Builder.
Приём данных с использованием OTel
Роли развертывания коллектора
Для сбора логов и их записи в ClickHouse мы рекомендуем использовать OpenTelemetry Collector. OpenTelemetry Collector может быть развернут в двух основных ролях:
- Agent – экземпляры агента собирают данные на периферии (edge), например, на серверах или на узлах Kubernetes, либо получают события напрямую от приложений, инструментированных с помощью OpenTelemetry SDK. В последнем случае экземпляр агента запускается вместе с приложением или на том же хосте, что и приложение (например, в виде сайдкара или ДемонСета). Агенты могут либо отправлять свои данные напрямую в ClickHouse, либо на экземпляр шлюза. В первом случае это называется паттерном развертывания Agent.
- Gateway – экземпляры шлюза предоставляют автономный сервис (например, «Deployment» в Kubernetes), как правило, на кластер, дата-центр или регион. Они получают события от приложений (или других коллекторов, работающих как агенты) через единый OTLP-эндпоинт. Как правило, разворачивается набор экземпляров шлюза, при этом для распределения нагрузки между ними используется готовый балансировщик нагрузки. Если все агенты и приложения отправляют свои сигналы на этот единый эндпоинт, это часто называют паттерном развертывания Gateway.
Далее мы предполагаем использование простого коллектора в роли агента, который отправляет свои события напрямую в ClickHouse. См. раздел Масштабирование с помощью шлюзов для получения дополнительных сведений об использовании шлюзов и случаях, когда они применимы.
Сбор логов
Основное преимущество использования коллектора заключается в том, что он позволяет вашим сервисам быстро передавать данные, перекладывая на него дополнительную обработку, такую как повторные попытки, пакетирование, шифрование или даже фильтрацию конфиденциальных данных.
Коллектор использует термины receiver, processor и exporter для трех основных этапов обработки. Ресиверы используются для сбора данных и могут работать как по pull-, так и по push-модели. Процессоры позволяют выполнять преобразование и обогащение сообщений. Экспортеры отвечают за отправку данных в нижележащий сервис. Хотя теоретически этим сервисом может быть другой коллектор, в последующем базовом рассмотрении мы предполагаем, что все данные отправляются напрямую в ClickHouse.
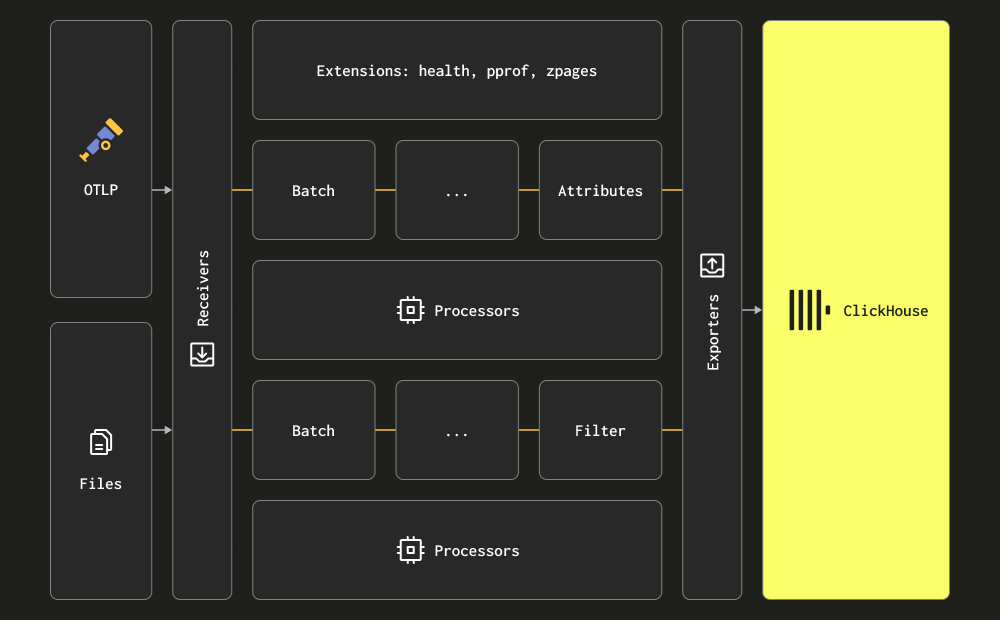
Мы рекомендуем пользователям ознакомиться с полным набором ресиверов, процессоров и экспортеров.
Коллектор предоставляет два основных ресивера для сбора логов:
Через OTLP — в этом случае логи отправляются (push) напрямую в коллектор из OpenTelemetry SDKS по протоколу OTLP. OpenTelemetry demo использует этот подход, при котором OTLP-экспортеры для каждого языка ожидают локальную конечную точку коллектора. В этом случае коллектор должен быть настроен с OTLP-ресивером — см. пример конфигурации в демо. Преимущество этого подхода в том, что данные логов автоматически будут содержать идентификаторы трассировок (Trace Ids), что позволит пользователям впоследствии находить трейсы для конкретного лога и наоборот.
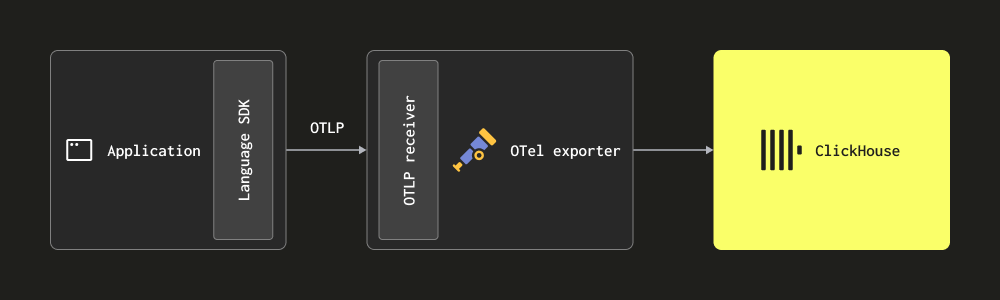
Этот подход требует от пользователей инструментировать свой код с помощью SDK для соответствующего языка.
- Сбор логов через ресивер Filelog — этот ресивер непрерывно читает файлы на диске (tail) и формирует сообщения логов, отправляя их в ClickHouse. Он обрабатывает сложные задачи, такие как обнаружение многострочных сообщений, обработка ротации логов, ведение контрольных точек для устойчивости к перезапускам и извлечение структуры. Дополнительно этот ресивер может считывать логи контейнеров Docker и Kubernetes, будучи развернутым как Helm-чарт, извлекая структуру из этих логов и обогащая их сведениями о поде.
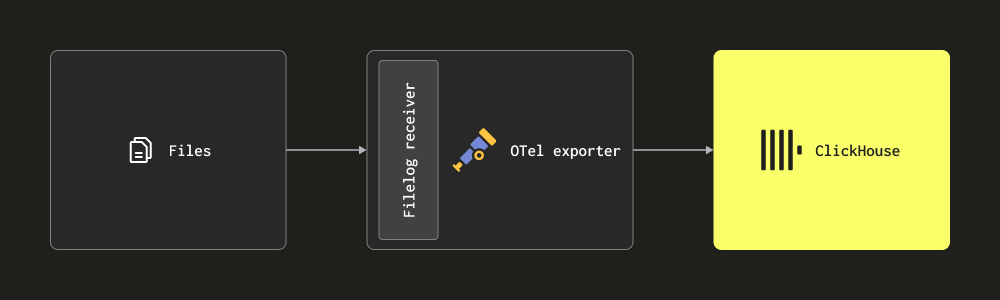
В большинстве развертываний используется комбинация приведенных выше ресиверов. Мы рекомендуем пользователям ознакомиться с документацией по коллектору и базовыми концепциями, а также со структурой конфигурации и методами установки.
Структурированные и неструктурированные
Логи могут быть как структурированными, так и неструктурированными.
Структурированный лог использует формат данных, например JSON, и определяет поля метаданных, такие как HTTP-код и исходный IP-адрес.
Неструктурированные логи, хотя обычно и обладают некоторой внутренней структурой, которую можно извлечь с помощью шаблона регулярного выражения, представляют сам лог исключительно в виде строки.
Мы рекомендуем использовать структурированное логирование и по возможности записывать логи в формате JSON (например, ndjson). Это упростит необходимую последующую обработку логов — либо до отправки в ClickHouse с помощью Collector processors, либо на этапе вставки с использованием материализованных представлений. Структурированные логи в конечном итоге сократят объем последующей обработки и снизят требуемое потребление CPU в вашем решении на базе ClickHouse.
Пример
В качестве примера мы предоставляем наборы данных с логами в структурированном (JSON) и неструктурированном виде, каждый примерно по 10 млн строк, доступные по следующим ссылкам:
В примере ниже используется набор данных со структурированными логами. Убедитесь, что этот файл скачан и распакован, чтобы воспроизвести следующие примеры.
Ниже приведена простая конфигурация для OTel collector, который читает эти файлы с диска, используя ресивер filelog, и выводит полученные сообщения в stdout. Мы используем оператор json_parser, так как наши логи структурированы. Измените путь к файлу access-structured.log.
Приведённый ниже пример извлекает временную метку из лога. Для этого требуется использовать оператор json_parser, который конвертирует всю строку лога в JSON, помещая результат в LogAttributes. Это может быть вычислительно затратным и может быть выполнено более эффективно в ClickHouse — см. Извлечение структуры с помощью SQL. Эквивалентный пример для неструктурированных логов, который использует regex_parser для достижения того же эффекта, можно найти здесь.
Пользователи могут воспользоваться официальными инструкциями для локальной установки коллектора. Важно при этом скорректировать инструкции так, чтобы использовать contrib-дистрибутив (в который входит filelog receiver), например, вместо otelcol_0.102.1_darwin_arm64.tar.gz пользователям следует скачать otelcol-contrib_0.102.1_darwin_arm64.tar.gz. Релизы можно найти здесь.
После установки OTel Collector можно запустить следующими командами:
При использовании структурированных логов сообщения на выходе будут иметь следующий вид:
Вышеприведённый пример представляет собой одно сообщение лога, сформированное OTel collector. В последующих разделах мы будем осуществлять приём этих же сообщений в ClickHouse.
Полная схема сообщений логов, вместе с дополнительными столбцами, которые могут присутствовать при использовании других receivers, представлена здесь. Мы настоятельно рекомендуем пользователям ознакомиться с этой схемой.
Ключевой момент здесь в том, что сама строка лога хранится как строка в поле Body, а JSON был автоматически разобран и вынесен в поле Attributes благодаря json_parser. Тот же operator использовался для извлечения временной метки в соответствующий столбец Timestamp. Рекомендации по обработке логов с помощью OTel см. в разделе Processing.
Операторы — это базовая единица обработки логов. Каждый оператор выполняет одну задачу, например, чтение строк из файла или разбор JSON из поля. Далее операторы объединяются в цепочку (pipeline), чтобы получить требуемый результат.
В приведённых выше сообщениях нет полей TraceID или SpanID. Если они присутствуют, например, в случаях, когда пользователи реализуют распределённое трассирование, их можно извлечь из JSON, используя те же приёмы, которые показаны выше.
Пользователям, которым необходимо собирать локальные файлы логов или логи Kubernetes, мы рекомендуем ознакомиться с параметрами конфигурации, доступными для filelog receiver, а также с тем, как реализованы отслеживание смещений (offsets) и обработка многострочных логов.
Сбор логов Kubernetes
Для сбора логов Kubernetes мы рекомендуем руководство по Kubernetes в документации OpenTelemetry. Для обогащения логов и метрик метаданными подов рекомендуется использовать Kubernetes Attributes Processor. Это может приводить к появлению динамических метаданных, например меток, которые хранятся в столбце ResourceAttributes. В настоящее время ClickHouse использует тип Map(String, String) для этого столбца. Дополнительные сведения по обработке и оптимизации этого типа см. в разделах Использование Map и Извлечение из Map.
Сбор трассировок
Пользователям, которые хотят инструментировать свой код и собирать трассировки, мы рекомендуем следовать официальной документации OTel.
Чтобы доставлять события в ClickHouse, необходимо развернуть OTel collector для получения событий трассировки по протоколу OTLP через соответствующий receiver. В демо OpenTelemetry приведен пример инструментирования каждого поддерживаемого языка и отправки событий в collector. Ниже приведен пример конфигурации collector, который выводит события в stdout:
Пример
Поскольку трассировки должны поступать через OTLP, мы используем инструмент telemetrygen для генерации данных трассировок. Следуйте инструкциям по установке, приведённым здесь.
Следующая конфигурация принимает события трассировок с помощью OTLP‑приёмника и затем отправляет их в stdout.
Запустите эту конфигурацию командой:
Отправьте события трассировки в коллектор с помощью telemetrygen:
В результате в stdout будут выводиться сообщения трассировки, похожие на приведённый ниже пример:
Приведённый выше пример представляет собой одно сообщение трассировки, сгенерированное OTel collector. Приём этих же сообщений в ClickHouse мы рассматриваем в следующих разделах.
Полная схема сообщений трассировки представлена здесь. Настоятельно рекомендуем ознакомиться с этой схемой.
Обработка — фильтрация, преобразование и обогащение
Как было показано в предыдущем примере с установкой временной метки для события лога, пользователям, как правило, требуется фильтровать, преобразовывать и обогащать сообщения о событиях. Это можно сделать с помощью ряда возможностей в OpenTelemetry:
-
Процессоры (Processors) — процессоры принимают данные, собранные получателями, и изменяют или преобразуют их перед отправкой экспортёрам. Процессоры применяются в том порядке, который указан в секции
processorsконфигурации коллектора. Они являются необязательными, но обычно рекомендуется минимальный набор. При использовании OTel collector с ClickHouse мы рекомендуем ограничиться следующими процессорами:- memory_limiter используется для предотвращения ситуаций с исчерпанием памяти на коллекторе. Рекомендации см. в разделе Estimating Resources.
- Любой процессор, выполняющий обогащение на основе контекста. Например, Kubernetes Attributes Processor позволяет автоматически задавать ресурсные атрибуты спанов, метрик и логов k8s-метаданными, т.е. обогащать события идентификатором исходного пода.
- Выборка по хвосту или голове (tail/head sampling), если это требуется для трейсов.
- Базовая фильтрация — отбрасывание ненужных событий, если это нельзя сделать через операторы (см. ниже).
- Пакетирование (batching) — критично при работе с ClickHouse, чтобы данные отправлялись пакетами. См. "Exporting to ClickHouse".
-
Операторы (Operators) — operators предоставляют наиболее базовую единицу обработки на уровне получателя. Поддерживается базовый парсинг, позволяющий устанавливать такие поля, как Severity и Timestamp. Здесь поддерживаются JSON- и regex-парсинг, а также фильтрация событий и базовые преобразования. Мы рекомендуем выполнять фильтрацию событий на этом уровне.
Мы рекомендуем пользователям избегать чрезмерной обработки событий с использованием операторов или процессоров transform. Они могут приводить к значительным накладным расходам по памяти и CPU, особенно при JSON-парсинге. Весь процессинг можно выполнять в ClickHouse на этапе вставки с помощью материализованных представлений и столбцов, с некоторыми исключениями — а именно, для обогащения, зависящего от контекста, например добавления k8s-метаданных. Более подробную информацию см. в разделе Extracting structure with SQL.
Если обработка выполняется с использованием OTel collector, мы рекомендуем выполнять преобразования на экземплярах шлюза (gateway) и минимизировать любую работу на экземплярах-агентах. Это обеспечит минимальные требования к ресурсам агентов на периферии, работающих на серверах. Обычно мы наблюдаем, что пользователи выполняют только фильтрацию (для минимизации лишнего сетевого трафика), установку временных меток (через operators) и обогащение, которое требует контекста, на агентах. Например, если экземпляры шлюза размещены в другом кластере Kubernetes, обогащение k8s потребуется выполнять на агенте.
Пример
Следующая конфигурация показывает сбор неструктурированного журнала из файла. Обратите внимание на использование операторов для извлечения структуры из строк журнала (regex_parser) и фильтрации событий, а также процессора для объединения событий в пакеты и ограничения использования памяти.
config-unstructured-logs-with-processor.yaml
Экспорт в ClickHouse
Экспортеры отправляют данные в один или несколько бэкендов или целевых назначений. Экспортеры могут работать по pull- или push-модели. Чтобы отправлять события в ClickHouse, пользователям необходимо использовать push-экспортер ClickHouse exporter.
Экспортер ClickHouse является частью OpenTelemetry Collector Contrib, а не основного дистрибутива. Пользователи могут либо использовать contrib-дистрибутив, либо собрать собственный коллектор.
Полный файл конфигурации приведён ниже.
Обратите внимание на следующие важные настройки:
- pipelines - Конфигурация выше демонстрирует использование pipelines, состоящих из набора receivers, processors и exporters, с отдельным конвейером для логов (logs) и трассировок (traces).
- endpoint - Взаимодействие с ClickHouse настраивается с помощью параметра
endpoint. Строка подключенияtcp://localhost:9000?dial_timeout=10s&compress=lz4&async_insert=1обеспечивает обмен по протоколу TCP. Если пользователи предпочитают HTTP по причинам, связанным с маршрутизацией трафика, измените эту строку подключения, как описано здесь. Полные детали подключения, включая возможность указать имя пользователя и пароль в этой строке подключения, описаны здесь.
Важно: Обратите внимание, что приведённая выше строка подключения включает как сжатие (lz4), так и асинхронные вставки. Мы рекомендуем всегда включать оба параметра. Подробности по асинхронным вставкам см. в разделе Batching. Сжатие всегда должно быть явно указано, так как по умолчанию оно не будет включено в старых версиях экспортера.
- ttl - значение определяет, как долго данные хранятся. Дополнительные сведения см. в разделе «Managing data». Значение должно задаваться как единица времени в часах, например 72h. В примере ниже мы отключаем TTL, так как наши данные относятся к 2019 году и будут немедленно удалены ClickHouse при вставке.
- traces_table_name и logs_table_name - определяют имена таблиц для логов и трассировок.
- create_schema - определяет, будут ли таблицы созданы с использованием схем по умолчанию при старте. По умолчанию установлено значение true для начального запуска. Пользователям следует установить false и определить собственную схему.
- database - целевая база данных.
- retry_on_failure - параметры, определяющие, нужно ли повторно отправлять неуспешные batch.
- batch - batch-процессор гарантирует, что события отправляются пакетами. Мы рекомендуем значение около 5000 с таймаутом 5s. То, что наступит раньше, инициирует формирование batch для отправки в exporter. Уменьшение этих значений приведёт к конвейеру с более низкой задержкой и более ранней доступностью данных для запросов, но за счёт увеличения числа соединений и batch, отправляемых в ClickHouse. Это не рекомендуется, если пользователи не используют asynchronous inserts, так как это может вызвать проблемы со слишком большим числом частей (too many parts) в ClickHouse. Напротив, если пользователи используют asynchronous inserts, доступность данных для запросов также будет зависеть от настроек асинхронных вставок, хотя данные всё равно будут отправляться экспортером раньше. Дополнительные сведения см. в разделе Batching.
- sending_queue - контролирует размер очереди отправки. Каждый элемент в очереди содержит один batch. Если очередь переполнится, например из-за недоступности ClickHouse при продолжающемся поступлении событий, batch будут отбрасываться.
Предполагая, что пользователи извлекли структурированный файл логов и запустили локальный экземпляр ClickHouse (с аутентификацией по умолчанию), они могут выполнить эту конфигурацию командой:
Чтобы отправить данные трассировки этому коллектору, выполните следующую команду, используя утилиту telemetrygen:
После запуска убедитесь, что в журнале появились записи логов, выполнив простой запрос:
Базовая схема
По умолчанию экспортер ClickHouse создаёт целевую таблицу для журналов, которая используется как для логов, так и для трейсов. Это можно отключить с помощью параметра create_schema. Кроме того, имена таблиц для логов и трейсов, по умолчанию otel_logs и otel_traces, можно изменить через указанные выше настройки.
В приведённых ниже схемах мы предполагаем, что TTL включён и равен 72 часам.
Схема по умолчанию для логов показана ниже (otelcol-contrib v0.102.1):
Столбцы здесь соответствуют официальной спецификации OTel по логам, описанной здесь.
Несколько важных замечаний по этой схеме:
- По умолчанию таблица разбивается на партиции по дате с помощью
PARTITION BY toDate(Timestamp). Это делает удаление устаревших данных эффективным. TTLзадаётся черезTTL toDateTime(Timestamp) + toIntervalDay(3)и соответствует значению, заданному в конфигурации коллектора.ttl_only_drop_parts=1означает, что удаляются только целые части, когда все строки в них устарели. Это эффективнее, чем удаление строк внутри частей, которое приводит к дорогостоящей операции удаления. Мы рекомендуем всегда устанавливать этот параметр. См. раздел Управление данными с помощью TTL для получения дополнительной информации.- Таблица использует классический движок
MergeTree. Он рекомендован для логов и трейсов и, как правило, не требует изменения. - Таблица упорядочена с помощью
ORDER BY (ServiceName, SeverityText, toUnixTimestamp(Timestamp), TraceId). Это означает, что запросы будут оптимизированы для фильтров поServiceName,SeverityText,TimestampиTraceId— более ранние столбцы в списке будут отфильтровываться быстрее, чем более поздние, например фильтрация поServiceNameбудет значительно быстрее, чем фильтрация поTraceId. Пользователям следует изменять этот порядок в соответствии со своими ожидаемыми паттернами доступа — см. Выбор первичного ключа. - В приведённой выше схеме к столбцам применяется
ZSTD(1). Это обеспечивает наилучшее сжатие для логов. Пользователи могут повысить уровень сжатия ZSTD (выше значения по умолчанию 1) для лучшей компрессии, хотя это редко даёт существенную выгоду. Увеличение этого значения приведёт к большему использованию ресурсов CPU во время вставки (во время сжатия), хотя распаковка (и, следовательно, выполнение запросов) должна оставаться сопоставимой. См. здесь дополнительные детали. Дополнительное дельта-кодирование применяется к полюTimestampс целью уменьшить его размер на диске. - Обратите внимание, что
ResourceAttributes,LogAttributesиScopeAttributesявляются ассоциативными массивами (map). Пользователям следует ознакомиться с различиями между ними. Информацию о том, как обращаться к этим структурам и оптимизировать доступ к ключам внутри них, см. в разделе Использование карт. - Большинство других типов здесь, например
ServiceNameкак LowCardinality, уже оптимизированы. Обратите внимание, чтоBody, который является JSON в наших примерных логах, хранится как String. - Ключам и значениям карт, а также столбцу
Bodyприменяются фильтры Блума. Они нацелены на улучшение времени выполнения запросов, обращающихся к этим столбцам, но обычно не являются обязательными. См. Вторичные индексы/индексы пропуска данных.
Как и ранее, это будет коррелировать со столбцами, соответствующими официальной спецификации OTel для трейсов, описанной здесь. Здесь схема использует многие из тех же настроек, что и приведённая выше схема логов, с дополнительными столбцами Link, специфичными для спанов.
Мы рекомендуем пользователям отключить автоматическое создание схемы и создавать таблицы вручную. Это позволяет изменять первичные и вторичные ключи, а также даёт возможность добавлять дополнительные столбцы для оптимизации производительности запросов. Для получения дополнительной информации см. раздел Schema design.
Оптимизация вставок
Чтобы обеспечить высокую производительность вставки при сохранении строгих гарантий согласованности, пользователям следует придерживаться простых правил при вставке данных Observability в ClickHouse через коллектор. При корректной конфигурации OTel collector соблюдение следующих правил не должно вызывать затруднений. Это также позволяет избежать типичных проблем, с которыми пользователи сталкиваются при первом использовании ClickHouse.
Пакетирование
По умолчанию каждый запрос INSERT, отправленный в ClickHouse, приводит к тому, что ClickHouse немедленно создает часть хранилища, содержащую данные из этого INSERT вместе с другими метаданными, которые необходимо сохранить. Поэтому выгоднее отправлять меньшее количество INSERT-запросов, каждый из которых содержит больше данных, чем большее количество INSERT-запросов с меньшим объемом данных: так сокращается число необходимых операций записи. Мы рекомендуем вставлять данные достаточно крупными пакетами — как минимум по 1 000 строк за один раз. Дополнительные подробности — здесь.
По умолчанию INSERT-запросы в ClickHouse выполняются синхронно и являются идемпотентными, если они идентичны. Для таблиц семейства движков MergeTree ClickHouse по умолчанию автоматически удаляет дубликаты при вставке. Это означает, что INSERT-запросы устойчивы к ошибкам в следующих случаях:
- (1) Если у узла, принимающего данные, возникают проблемы, запрос
INSERTзавершится по тайм-ауту (или с более специфической ошибкой) и не получит подтверждения. - (2) Если данные были записаны узлом, но подтверждение не может быть возвращено отправителю запроса из-за сетевых перебоев, отправитель получит тайм-аут или сетевую ошибку.
С точки зрения коллектора различить (1) и (2) может быть сложно. Однако в обоих случаях неподтвержденный INSERT можно сразу же повторить. Пока повторный запрос INSERT содержит те же данные в том же порядке, ClickHouse автоматически проигнорирует повторный INSERT, если исходный (неподтвержденный) INSERT был успешно выполнен.
Мы рекомендуем использовать batch processor, показанный в предыдущих конфигурациях, чтобы удовлетворить указанным выше требованиям. Это гарантирует, что INSERT-запросы отправляются как устойчивые по составу батчи строк, удовлетворяющие этим условиям. Если от коллектора ожидается высокая пропускная способность (событий в секунду) и в каждом INSERT можно отправлять по крайней мере 5000 событий, этого обычно достаточно как единственного пакетирования в конвейере. В этом случае коллектор будет сбрасывать батчи до того, как будет достигнут timeout у batch processor, обеспечивая низкую сквозную задержку конвейера и стабильный размер батчей.
Используйте асинхронные вставки
Обычно пользователи вынуждены отправлять более мелкие пакеты, когда пропускная способность коллектора низкая, при этом они по-прежнему ожидают, что данные попадут в ClickHouse с минимальной сквозной задержкой. В таком случае небольшие пакеты отправляются, когда истекает timeout процессора пакетирования. Это может вызвать проблемы и является ситуацией, когда требуются асинхронные вставки. Такая ситуация обычно возникает, когда коллекторы в роли агента настроены на отправку данных напрямую в ClickHouse. Использование шлюзов как агрегаторов может уменьшить эту проблему — см. раздел Масштабирование с помощью шлюзов.
Если невозможно гарантировать крупные пакеты, пользователи могут делегировать пакетирование ClickHouse, используя асинхронные вставки. При асинхронных вставках данные сначала вставляются во временный буфер, а затем записываются в хранилище базы данных позже, то есть асинхронно.
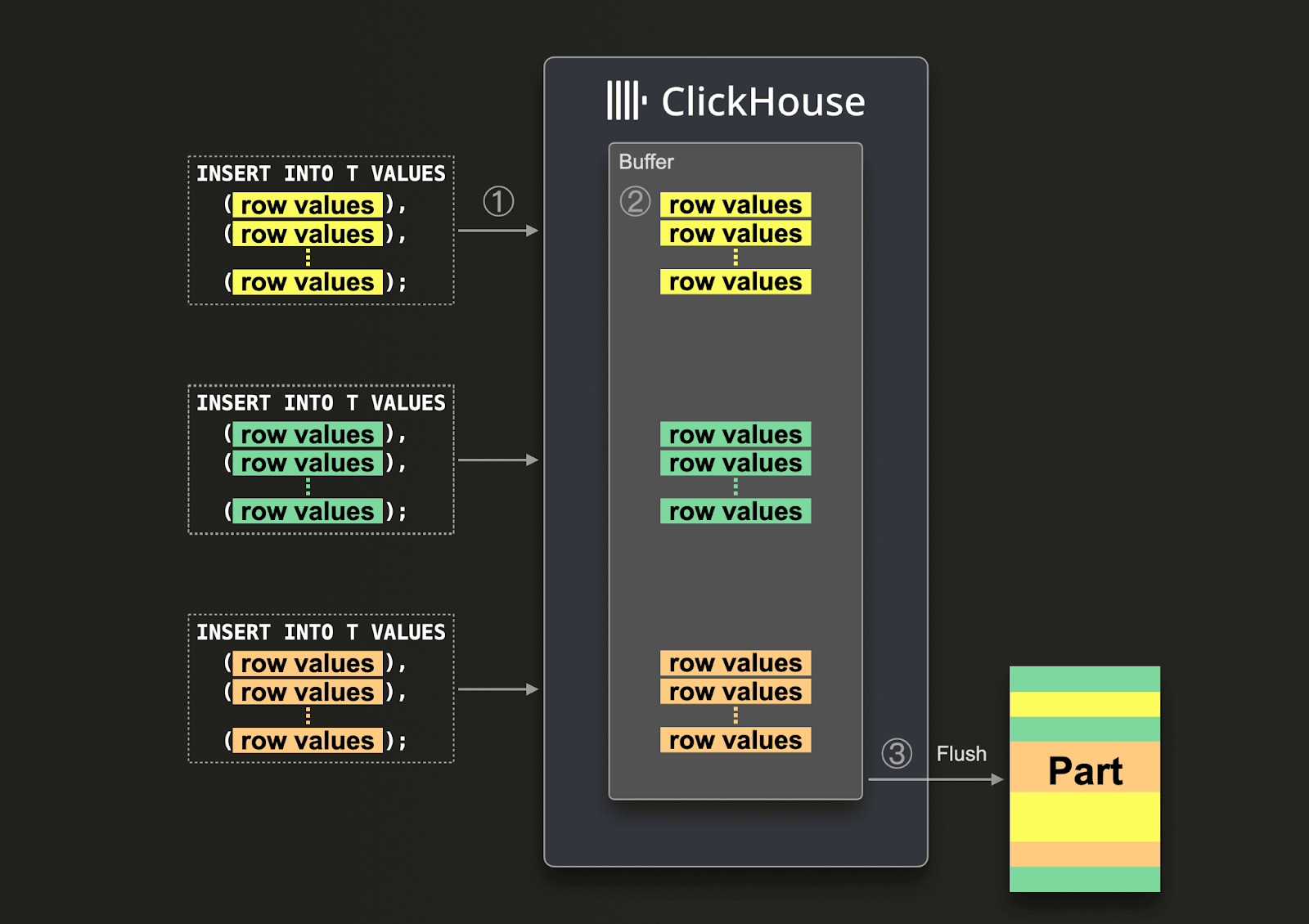
При включенных асинхронных вставках, когда ClickHouse ① получает запрос на вставку, данные запроса ② сразу записываются сначала в буфер в оперативной памяти. Когда ③ выполняется следующий сброс буфера, данные буфера сортируются и записываются как часть в хранилище базы данных. Обратите внимание, что данные недоступны для запросов до их сброса в хранилище базы данных; параметры сброса буфера настраиваются.
Чтобы включить асинхронные вставки для коллектора, добавьте async_insert=1 в строку подключения. Мы рекомендуем использовать wait_for_async_insert=1 (значение по умолчанию), чтобы получить гарантии доставки — дополнительные сведения см. здесь.
Данные из асинхронной вставки записываются после сброса буфера ClickHouse. Это происходит либо после превышения значения async_insert_max_data_size, либо по истечении async_insert_busy_timeout_ms миллисекунд с момента первого запроса INSERT. Если параметр async_insert_stale_timeout_ms установлен в ненулевое значение, данные вставляются по истечении async_insert_stale_timeout_ms миллисекунд с момента последнего запроса. Пользователи могут настраивать эти параметры для управления сквозной задержкой своего конвейера обработки данных. Дополнительные настройки, которые можно использовать для тонкой настройки сброса буфера, задокументированы здесь. Как правило, значения по умолчанию являются подходящими.
В случаях, когда используется небольшое количество агентов с низкой пропускной способностью, но жесткими требованиями к сквозной задержке, могут быть полезны адаптивные асинхронные вставки. Как правило, они неприменимы к сценариям наблюдаемости с высокой пропускной способностью, характерным для ClickHouse.
Наконец, предыдущее поведение дедупликации, связанное с синхронными вставками в ClickHouse, по умолчанию не включено при использовании асинхронных вставок. При необходимости см. настройку async_insert_deduplicate.
Полная информация по настройке этой функции приведена здесь, детальный разбор — здесь.
Архитектуры развертывания
При использовании OTel collector с ClickHouse возможны несколько архитектур развертывания. Ниже мы описываем каждую из них и указываем, когда она наиболее уместна.
Только агенты
В архитектуре только с агентами пользователи разворачивают OTel collector в качестве агентов на границе инфраструктуры. Они получают трейсы от локальных приложений (например, как sidecar-контейнер) и собирают логи с серверов и узлов Kubernetes. В этом режиме агенты отправляют свои данные напрямую в ClickHouse.
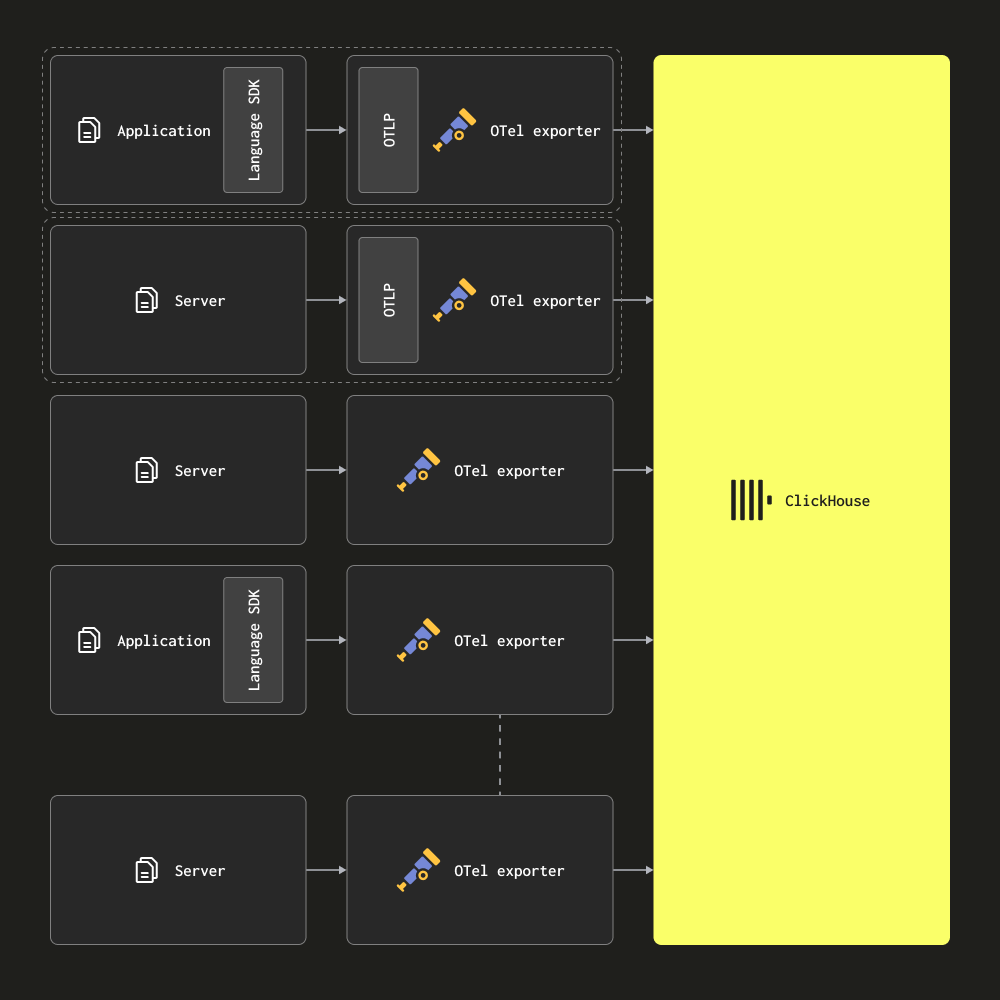
Такая архитектура подходит для развертываний малого и среднего размера. Ее основное преимущество в том, что она не требует дополнительного оборудования и позволяет сохранить совокупное ресурсное потребление решения наблюдаемости на ClickHouse минимальным, обеспечивая простое соответствие между приложениями и коллекторами.
Пользователям следует рассмотреть переход на архитектуру с Gateway, когда число агентов превышает несколько сотен. У этой архитектуры есть несколько недостатков, которые затрудняют масштабирование:
- Масштабирование подключений — Каждый агент устанавливает подключение к ClickHouse. Хотя ClickHouse способен поддерживать сотни (если не тысячи) одновременных подключений для вставки, в конечном итоге это становится ограничивающим фактором и делает вставки менее эффективными — то есть больше ресурсов ClickHouse будет тратить на поддержание подключений. Использование шлюзов (Gateway) минимизирует число подключений и делает вставки более эффективными.
- Обработка на периферии — Любые преобразования или обработка событий в этой архитектуре должны выполняться либо на периферии, либо в ClickHouse. Помимо ограничений, это может означать либо сложные материализованные представления в ClickHouse, либо перенос значительных вычислений на периферию — где могут пострадать критически важные сервисы и ресурсы ограничены.
- Малые партии и задержки — Коллекторы-агенты могут по отдельности собирать очень мало событий. Обычно это означает, что их нужно настраивать на сброс данных через заданный интервал для соблюдения SLA по доставке. В результате коллектор может отправлять в ClickHouse небольшие партии. Несмотря на то что это недостаток, его можно смягчить с помощью асинхронных вставок — см. Оптимизация вставок.
Масштабирование с использованием шлюзов
Коллекторы OTel могут быть развернуты в виде экземпляров шлюзов (Gateway), чтобы устранить вышеуказанные ограничения. Они представляют собой автономный сервис, как правило, по одному на каждый дата-центр или регион. Они принимают события от приложений (или других коллекторов в роли агентов) через единый endpoint OTLP. Обычно разворачивается набор экземпляров шлюзов, при этом для распределения нагрузки между ними используется готовый балансировщик нагрузки.
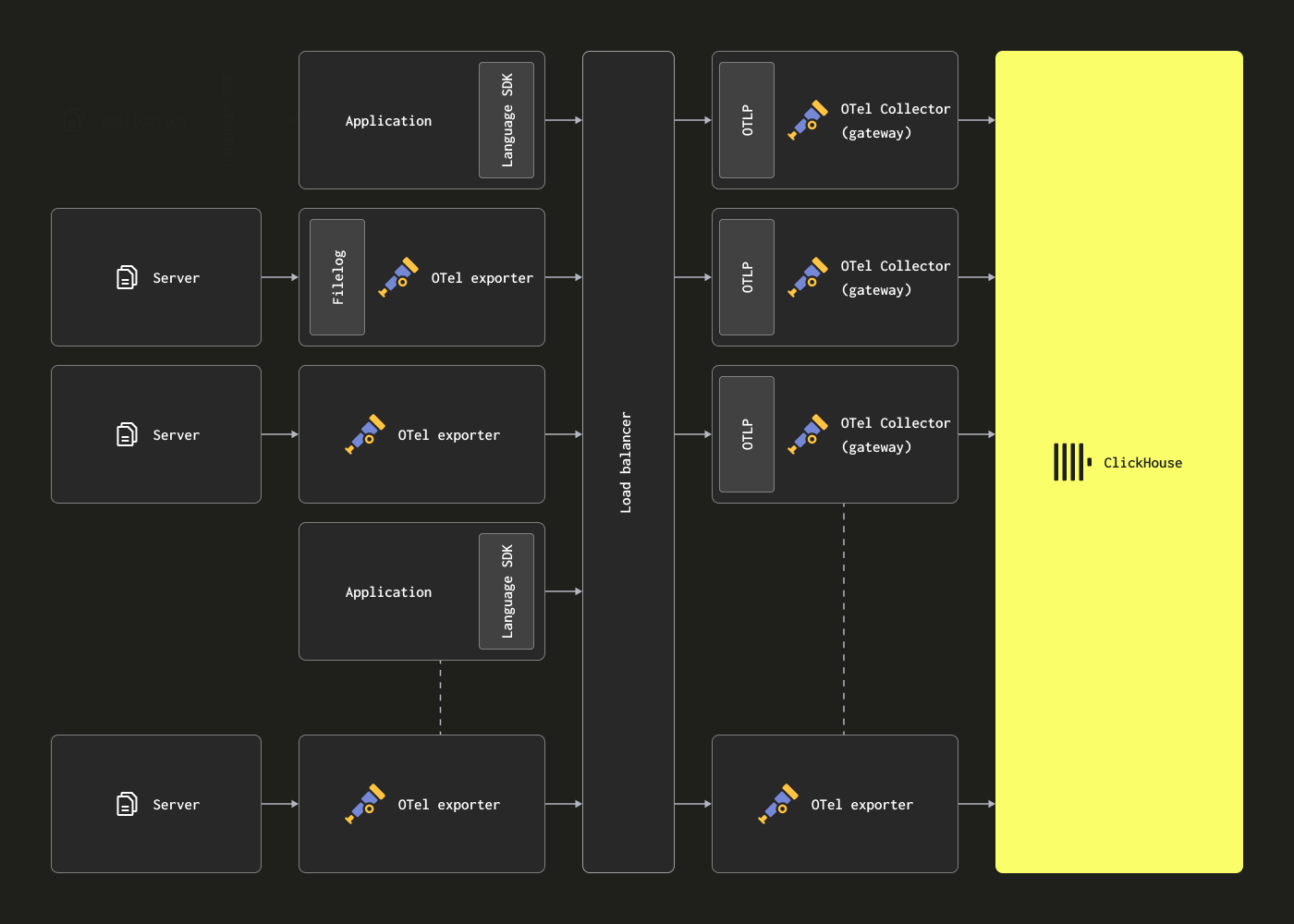
Цель этой архитектуры — разгрузить агентов от вычислительно затратной обработки, тем самым минимизируя потребление ресурсов агентами. Эти шлюзы могут выполнять задачи трансформации, которые иначе пришлось бы выполнять агентам. Кроме того, агрегируя события от множества агентов, шлюзы могут обеспечивать отправку в ClickHouse крупных пакетов данных, что позволяет эффективно вставлять данные. Эти шлюзовые коллекторы можно легко масштабировать по мере добавления новых агентов и роста пропускной способности событий. Пример конфигурации шлюза с соответствующей конфигурацией агента, считывающего пример структурированного файла журнала, приведен ниже. Обратите внимание на использование OTLP для связи между агентом и шлюзом.
clickhouse-gateway-config.yaml
Эти конфигурации можно использовать, выполнив следующие команды.
Основной недостаток этой архитектуры — связанные с ней затраты и накладные расходы на управление набором коллекторов.
В качестве примера управления более крупными архитектурами на основе шлюзов и связанных с этим уроков мы рекомендуем этот блог‑пост.
Добавление Kafka
Читатели могут заметить, что приведённые выше архитектуры не используют Kafka в качестве очереди сообщений.
Использование очереди Kafka как буфера сообщений — популярный шаблон проектирования, применяемый в архитектурах логирования и ставший широко известным благодаря стеку ELK. Он даёт ряд преимуществ; в первую очередь, помогает обеспечивать более строгие гарантии доставки сообщений и упрощает работу с обратным давлением (backpressure). Сообщения отправляются от агентов сбора в Kafka и записываются на диск. В теории кластер Kafka должен обеспечивать высокопроизводительный буфер сообщений, поскольку последовательная запись данных на диск требует меньших вычислительных затрат, чем разбор и обработка сообщения — в Elastic, например, токенизация и индексация вносят значительные накладные расходы. Перенося данные с агентов, вы также снижаете риск потери сообщений из‑за ротации логов на источнике. Наконец, Kafka предоставляет возможности повторного воспроизведения сообщений и кросс-региональной репликации, что может быть привлекательно для некоторых сценариев использования.
Однако ClickHouse способен очень быстро вставлять данные — миллионы строк в секунду на оборудовании средней мощности. Обратное давление со стороны ClickHouse встречается редко. Часто использование очереди Kafka приводит к увеличению архитектурной сложности и затрат. Если вы можете принять принцип, что логи не нуждаются в тех же гарантиях доставки, что банковские транзакции и другие бизнес-критичные данные, мы рекомендуем избегать усложнения архитектуры за счёт Kafka.
Тем не менее, если вам требуются высокие гарантии доставки или возможность повторного воспроизведения данных (потенциально в несколько приёмников), Kafka может быть полезным архитектурным дополнением.
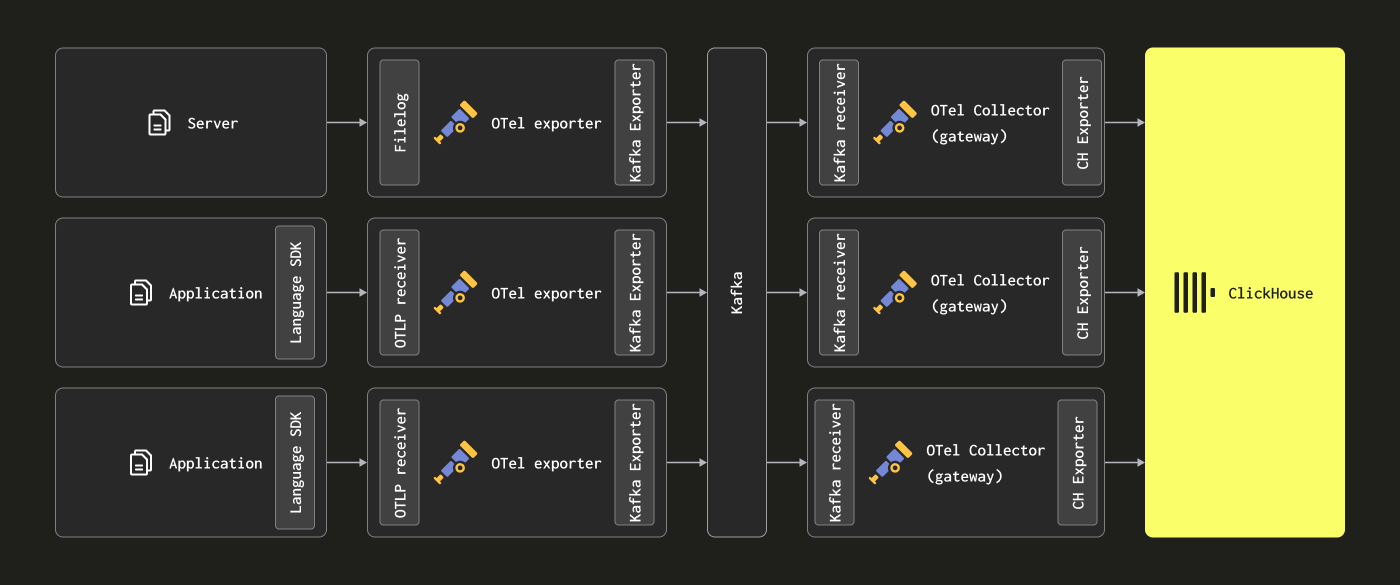
В этом случае агенты OTel можно настроить на отправку данных в Kafka с помощью Kafka exporter. В свою очередь, инстансы Gateway потребляют сообщения с использованием Kafka receiver. За дополнительными подробностями мы рекомендуем обратиться к документации Confluent и OTel.
Оценка требований к ресурсам
Требования к ресурсам для OTel collector зависят от пропускной способности по событиям, размера сообщений и объема выполняемой обработки. Проект OpenTelemetry предоставляет бенчмарки, которыми пользователи могут воспользоваться для оценки потребностей в ресурсах.
По нашему опыту экземпляр шлюза с 3 ядрами и 12 ГБ ОЗУ может обрабатывать около 60 тыс. событий в секунду. Это предполагает минимальный конвейер обработки, отвечающий за переименование полей, и отсутствие регулярных выражений.
Для экземпляров агента, отвечающих за отправку событий на шлюз и только установку временной метки на событии, мы рекомендуем подбирать ресурсы, исходя из ожидаемого количества логов в секунду. Ниже приведены приблизительные значения, которые можно использовать как отправную точку:
| Скорость поступления логов | Ресурсы для collector-агента |
|---|---|
| 1k/секунда | 0,2 CPU, 0,2 GiB |
| 5k/секунда | 0,5 CPU, 0,5 GiB |
| 10k/секунда | 1 CPU, 1 GiB |
