Обзор архитектуры
Это веб-версия нашей научной статьи VLDB 2024. Мы также опубликовали пост в блоге о её предпосылках и истории создания, и рекомендуем посмотреть доклад на конференции VLDB 2024 от CTO и создателя ClickHouse, Алексея Миловидова:
АННОТАЦИЯ
За последние несколько десятилетий объём данных, которые хранятся и анализируются, возрос экспоненциально. Компании во всех отраслях и секторах начали полагаться на эти данные для улучшения продуктов, оценки эффективности и принятия критически важных для бизнеса решений. Однако по мере того как объёмы данных всё чаще достигают масштабов Интернета, компаниям необходимо управлять историческими и новыми данными экономичным и масштабируемым образом, одновременно анализируя их с помощью большого числа параллельных запросов и обеспечивая задержки, близкие к реальному времени (например, менее одной секунды, в зависимости от варианта использования).
В данной работе представлен обзор ClickHouse — популярной OLAP-базы данных с открытым исходным кодом, спроектированной для высокопроизводительной аналитики над наборами данных петабайтного масштаба с высокими скоростями ингестии. Её уровень хранения данных сочетает формат, основанный на классических деревьях log-structured merge (LSM), с новыми методами непрерывного преобразования (например, агрегации, архивирования) исторических данных в фоновом режиме. Запросы пишутся на удобном диалекте SQL и обрабатываются передовым векторизованным механизмом выполнения запросов с опциональной компиляцией кода. ClickHouse агрессивно использует методы отсечения данных, чтобы избегать вычислений над нерелевантными фрагментами в запросах. Другие системы управления данными могут интегрироваться на уровне табличной функции, ^^движка таблицы^^ или движка базы данных. Практические бенчмарки показывают, что ClickHouse является одной из самых быстрых аналитических баз данных на рынке.
1 ВВЕДЕНИЕ
В этом документе описывается ClickHouse — колоночная OLAP-база данных, предназначенная для высокопроизводительного выполнения аналитических запросов по таблицам с триллионами строк и сотнями столбцов. ClickHouse был создан в 2009 году как оператор фильтрации и агрегации для лог-файлов веб‑масштаба и стал проектом с открытым исходным кодом в 2016 году. На рисунке 1 показано, когда основные возможности, описанные в этом документе, были добавлены в ClickHouse.
ClickHouse спроектирован для решения пяти ключевых задач современного управления аналитическими данными:
-
Огромные наборы данных с высокой скоростью приёма. Многие приложения, основанные на данных, в таких отраслях, как веб-аналитика, финансы и электронная коммерция, характеризуются огромными и непрерывно растущими объёмами данных. Для обработки таких объёмов аналитические базы данных должны не только обеспечивать эффективные стратегии индексирования и сжатия, но и позволять распределять данные по нескольким узлам (масштабирование вширь), так как отдельные серверы ограничены несколькими десятками терабайт хранилища. Более того, свежие данные часто более важны для получения оперативных инсайтов, чем исторические. В результате аналитические базы данных должны уметь принимать новые данные с устойчиво высокой скоростью или во всплесках, а также постоянно "снижать приоритет" исторических данных (например, агрегировать, архивировать), не замедляя параллельные отчётные запросы.
-
Много одновременных запросов при ожидании низких задержек. Запросы в общем случае можно разделить на разовые (например, исследовательский анализ данных) и повторяющиеся (например, периодические запросы для дашбордов). Чем более интерактивен сценарий использования, тем более низкая задержка запросов ожидается, что создаёт дополнительные задачи для оптимизации и выполнения запросов. Повторяющиеся запросы дополнительно дают возможность адаптировать физическую структуру базы данных под рабочую нагрузку. В результате базы данных должны предоставлять методы отсечения (pruning), позволяющие оптимизировать частые запросы. В зависимости от приоритета запроса базы данных также должны обеспечивать равный или приоритезированный доступ к общим системным ресурсам — таким как CPU, память, диск и сетевой ввод-вывод, — даже если одновременно выполняется большое количество запросов.
-
Разнообразные ландшафты хранилищ данных, мест размещения и форматов. Для интеграции с существующей архитектурой данных современные аналитические базы данных должны быть максимально открытыми для чтения и записи внешних данных в любых системах, местах размещения и форматах.
-
Удобный язык запросов с поддержкой анализа производительности. Реальное использование OLAP-баз данных накладывает дополнительные "мягкие" требования. Например, вместо нишевого языка программирования пользователи часто предпочитают взаимодействовать с базами данных через выразительный диалект SQL с вложенными типами данных и широким набором обычных, агрегирующих и оконных функций. Аналитические базы данных также должны предоставлять развитые средства для анализа производительности системы в целом или отдельных запросов.
-
Надёжность промышленного уровня и гибкие варианты развертывания. Поскольку массовое аппаратное обеспечение ненадёжно, базы данных должны обеспечивать репликацию данных для защиты от сбоев узлов. Кроме того, базы данных должны работать на любом оборудовании — от старых ноутбуков до мощных серверов. Наконец, чтобы избежать накладных расходов на сборку мусора в программах на базе JVM и обеспечить производительность уровня "bare metal" (например, с использованием SIMD), базы данных в идеале развёртываются как нативные исполняемые файлы для целевой платформы.

Рисунок 1: временная шкала ClickHouse.
2 АРХИТЕКТУРА
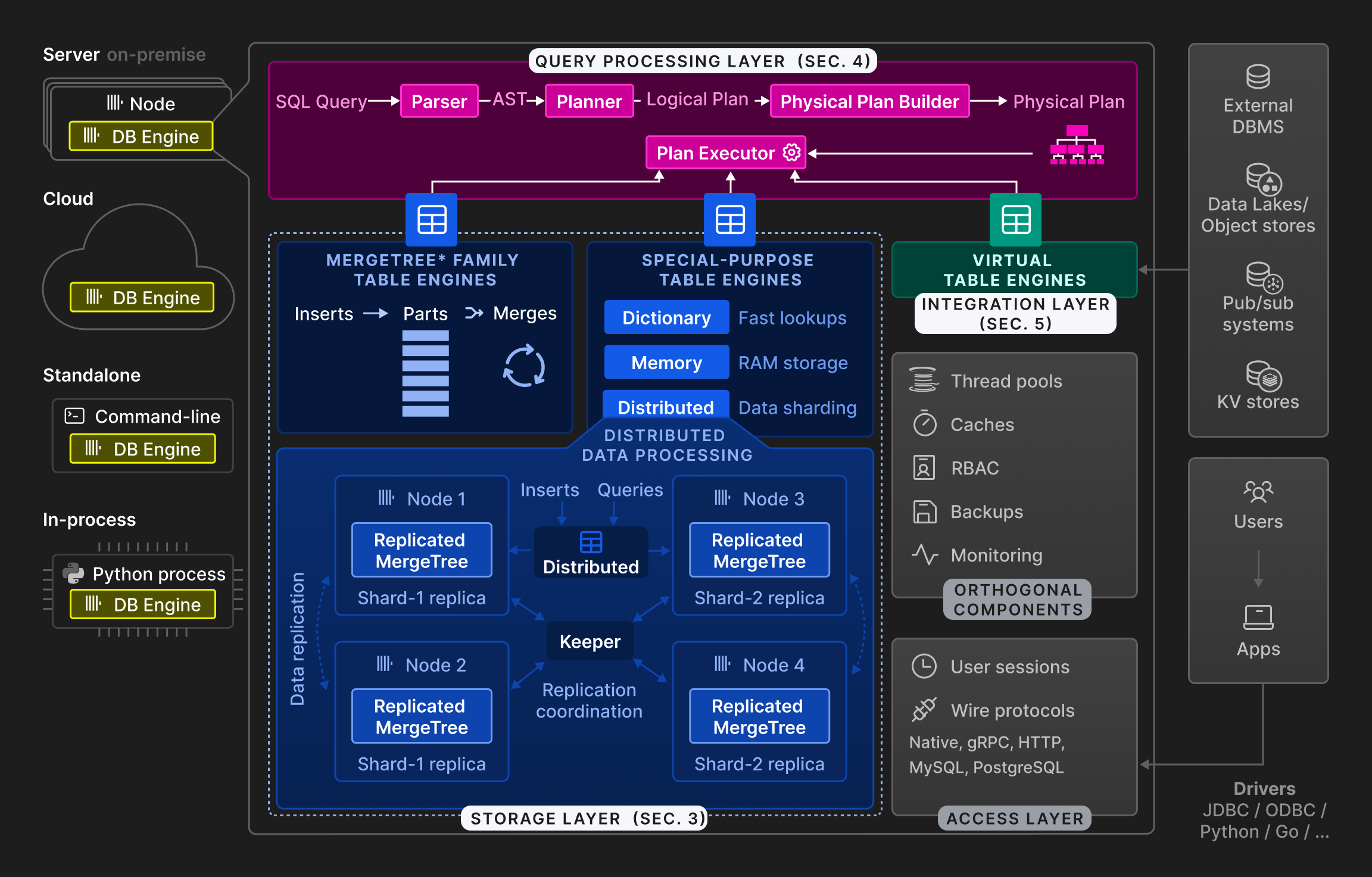
Рисунок 2: Высокоуровневая архитектура движка базы данных ClickHouse.
Как показано на рисунке 2, движок ClickHouse разделён на три основных слоя: слой обработки запросов (описан в разделе 4), слой хранения (раздел 3) и слой интеграции (раздел 5). Помимо этого, слой доступа управляет пользовательскими сессиями и взаимодействием с приложениями по различным протоколам. Существуют ортогональные компоненты для работы с потоками, кэширования, управления доступом на основе ролей, резервного копирования и непрерывного мониторинга. ClickHouse реализован на C++ в виде единственного статически слинкованного исполняемого файла без зависимостей.
Обработка запросов следует традиционной парадигме: разбор входящих запросов, построение и оптимизация логических и физических планов запросов, затем выполнение. ClickHouse использует векторизированную модель исполнения, похожую на MonetDB/X100 [11], в сочетании с оппортунистической компиляцией кода [53]. Запросы могут быть написаны на функционально богатом диалекте SQL, PRQL [76] или KQL системы Kusto [50].
Слой хранения состоит из различных движков таблиц, которые инкапсулируют формат и местоположение данных таблицы. Движки таблиц делятся на три категории. Первая категория — семейство движков таблиц ^^MergeTree^^, представляющее основной формат постоянного хранения данных в ClickHouse. Основываясь на идее деревьев LSM [60], таблицы разделяются на горизонтальные отсортированные ^^части^^, которые непрерывно сливаются фоновой задачей. Отдельные движки таблиц ^^MergeTree^^ различаются способом, которым процедура слияния комбинирует строки из своих входных ^^частей^^. Например, строки могут агрегироваться или заменяться, если они устарели.
Вторая категория — специализированные движки таблиц, используемые для ускорения или распределения выполнения запросов. В эту категорию входят хранимые в памяти движки таблиц ключ‑значение, называемые словарями. Словарь кэширует результат запроса, периодически выполняемого к внутреннему или внешнему источнику данных. Это существенно снижает задержки доступа в сценариях, где допустима определённая степень устаревания данных. Другие примеры специализированных движков таблиц включают чисто in-memory‑движок, используемый для временных таблиц, и движок ^^Distributed table^^ для прозрачного шардинга данных (см. ниже).
Третья категория движков таблиц — виртуальные движки таблиц для двунаправленного обмена данными с внешними системами, такими как реляционные базы данных (например, PostgreSQL, MySQL), системы публикации/подписки (например, Kafka, RabbitMQ [24]) или хранилища ключ‑значение (например, Redis). Виртуальные движки также могут взаимодействовать с озёрами данных (например, Iceberg, DeltaLake, Hudi [36]) или файлами в объектном хранилище (например, AWS S3, Google GCP).
ClickHouse поддерживает шардинг и репликацию таблиц по нескольким узлам ^^кластера^^ для обеспечения масштабируемости и доступности. Шардинг разбивает таблицу на набор шардов в соответствии с выражением шардинга. Отдельные шарды являются взаимно независимыми таблицами и, как правило, размещаются на разных узлах. Клиенты могут читать и писать шарды напрямую, то есть рассматривать их как отдельные таблицы, или использовать специализированный движок ^^Distributed table engine^^, который предоставляет глобальное представление всех шардов таблицы. Основное назначение шардинга — обработка наборов данных, превышающих ёмкость отдельных узлов (обычно несколько десятков терабайт данных). Другая цель шардинга — распределять нагрузку чтения/записи по таблице между несколькими узлами, то есть реализовывать балансировку нагрузки. Ортогонально этому, ^^шард^^ может быть реплицирован на несколько узлов для устойчивости к отказам узлов. Для этого у каждого движка ^^table engine^^ Merge-Tree* есть соответствующий движок ReplicatedMergeTree*, который использует многомастерную схему координации, основанную на консенсусе Raft [59] (реализованном в Keeper — полностью совместимой заменe Apache Zookeeper, написанной на C++), чтобы гарантировать, что у каждого ^^шарда^^ в каждый момент времени есть настраиваемое количество реплик. Раздел 3.6 подробно обсуждает механизм репликации. В качестве примера рисунок 2 показывает таблицу с двумя шардами, каждый из которых реплицирован на два узла.
Наконец, движок базы данных ClickHouse может работать в локальном (on-premise), облачном, автономном (standalone) или внутрипроцессном (in-process) режимах. В локальном режиме пользователи разворачивают ClickHouse как одиночный сервер или многосерверный ^^кластер^^ с шардингом и/или репликацией. Клиенты взаимодействуют с базой данных по нативному двоичному протоколу, по двоичным протоколам MySQL и PostgreSQL либо через HTTP REST API. Облачный режим представлен ClickHouse Cloud — полностью управляемым и автоматически масштабируемым DBaaS‑сервисом. Хотя в данном документе основное внимание уделяется локальному режиму, мы планируем описать архитектуру ClickHouse Cloud в последующей публикации. Автономный режим превращает ClickHouse в консольную утилиту для анализа и преобразования файлов, выступая SQL‑альтернативой Unix‑инструментам наподобие cat и grep. При этом не требуется предварительная конфигурация, но автономный режим ограничен одним сервером. Недавно был разработан внутрипроцессный режим под названием chDB [15] для интерактивных сценариев анализа данных, таких как ноутбуки Jupyter [37] с датафреймами Pandas [61]. Вдохновлённый DuckDB [67], chDB встраивает ClickHouse как высокопроизводительный OLAP‑движок в процесс‑хост. По сравнению с другими режимами это позволяет эффективно передавать исходные и результирующие данные между движком базы данных и приложением без копирования, поскольку они работают в одном адресном пространстве.
3 СЛОЙ ХРАНЕНИЯ
В этом разделе рассматриваются движки таблиц ^^MergeTree^^* как собственный формат хранения ClickHouse. Мы описываем их представление на диске и обсуждаем три метода отсечения данных в ClickHouse. Далее мы рассматриваем стратегии слияния, которые непрерывно преобразуют данные, не влияя на параллельные операции вставки. Наконец, мы объясняем, как реализованы операции обновления и удаления, а также дедупликация данных, репликация данных и соблюдение требований ACID.
3.1 Формат на диске
Каждая таблица в движке таблиц ^^MergeTree^^* организована как набор неизменяемых ^^частей^^ таблицы. Часть создаётся всякий раз, когда в таблицу вставляется набор строк. ^^Части^^ являются самодостаточными в том смысле, что они включают всю метаинформацию, необходимую для интерпретации их содержимого, без дополнительных обращений к центральному каталогу. Чтобы поддерживать низкое количество ^^частей^^ на таблицу, фоновая задача слияния периодически объединяет несколько меньших ^^частей^^ в более крупную часть, пока не будет достигнут настраиваемый размер части (по умолчанию 150 ГБ). Поскольку ^^части^^ отсортированы по столбцам ^^первичного ключа^^ таблицы (см. раздел 3.2), для слияния используется эффективная k‑путевая сортировка слиянием [40]. Исходные ^^части^^ помечаются как неактивные и в конечном итоге удаляются, как только их счётчик ссылок падает до нуля, т. е. когда ни один запрос больше не читает из них.
Строки могут вставляться в двух режимах. В синхронном режиме вставки каждый оператор INSERT создаёт новую часть и добавляет её в таблицу. Чтобы минимизировать накладные расходы на слияния, рекомендуется, чтобы клиенты базы данных вставляли строки пакетно, например по 20 000 строк за раз. Однако задержки, вызванные пакетированием на стороне клиента, часто неприемлемы, если данные должны анализироваться в режиме, близком к реальному времени. Например, сценарии наблюдаемости часто включают тысячи агентов мониторинга, непрерывно отправляющих небольшие объёмы событий и метрик. В таких сценариях можно использовать асинхронный режим вставки, при котором ClickHouse буферизует строки из нескольких входящих INSERT в одну и ту же таблицу и создаёт новую часть только после того, как размер буфера превысит настраиваемый порог или истечёт тайм-аут.
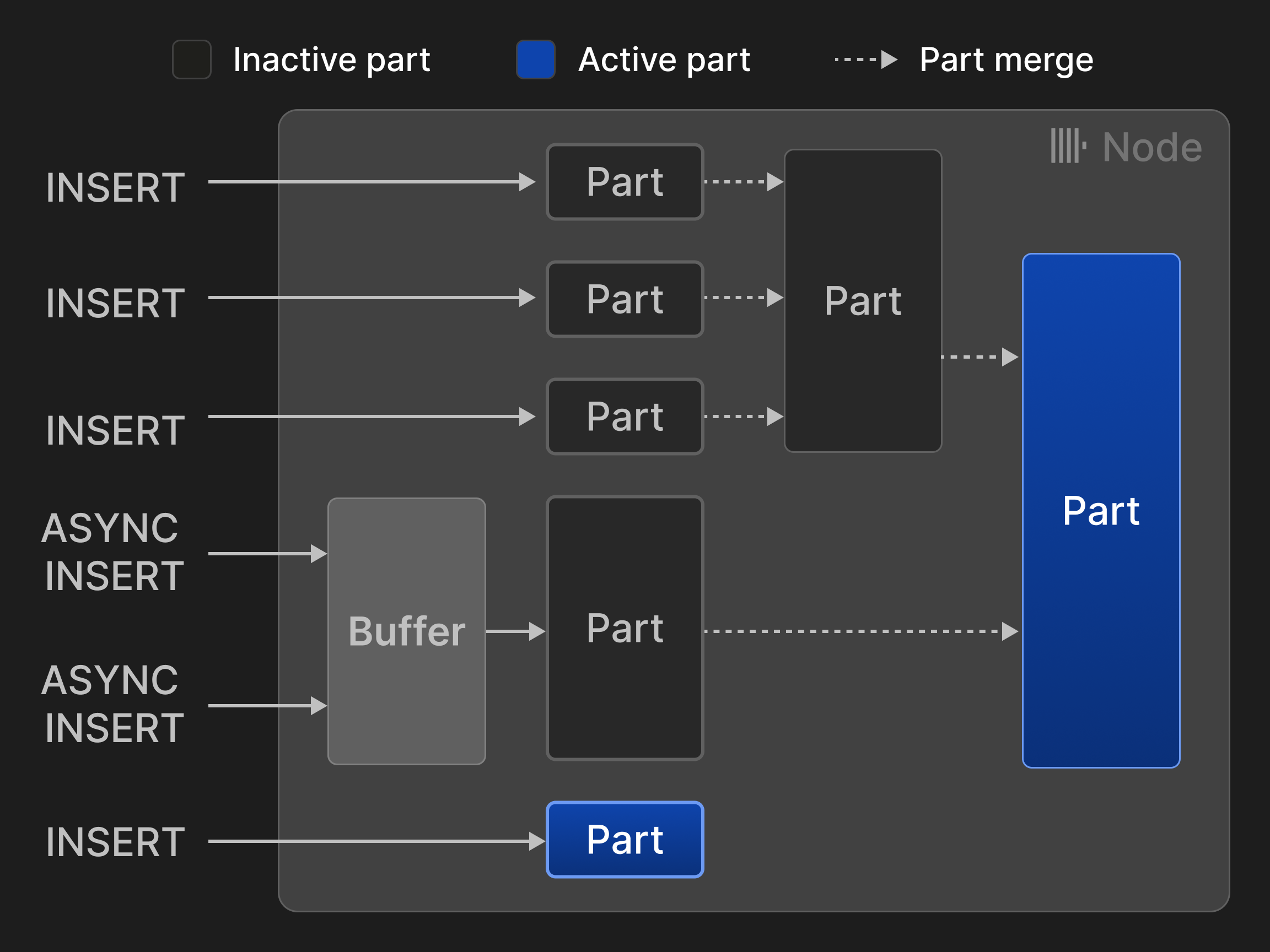
Рисунок 3: Вставки и слияния для таблиц с движком ^^MergeTree^^*.
Рисунок 3 иллюстрирует четыре синхронные и две асинхронные вставки в таблицу с движком ^^MergeTree^^*. Два слияния уменьшили количество активных ^^частей^^ с изначальных пяти до двух.
По сравнению с LSM‑деревьями [58] и их реализациями в различных базах данных [13, 26, [56]](#page-13-8), ClickHouse рассматривает все ^^части^^ как равноправные, вместо того чтобы организовывать их в иерархию. В результате слияния больше не ограничены ^^частями^^ на одном и том же уровне. Поскольку при этом также отсутствует неявная хронологическая упорядоченность ^^частей^^, требуются альтернативные механизмы для обновлений и удалений, не основанные на «надгробиях» (tombstones) (см. раздел 3.4). ClickHouse записывает вставки напрямую на диск, в то время как другие хранилища на основе LSM‑деревьев обычно используют журнал предварительной записи (см. раздел 3.7).
Часть соответствует директории на диске, содержащей по одному файлу для каждого столбца. В качестве оптимизации столбцы небольшой части (меньше 10 МБ по умолчанию) хранятся последовательно в одном файле для увеличения пространственной локальности чтения и записи. Строки части далее логически делятся на группы по 8192 записи, называемые гранулами. ^^Гранула^^ представляет собой наименьшую неделимую единицу данных, обрабатываемую операторами сканирования и поиска по индексу в ClickHouse. Однако чтение и запись данных на диске выполняются не на уровне ^^гранул^^, а на уровне блоков, которые объединяют несколько соседних гранул в пределах столбца. Новые блоки формируются на основе настраиваемого размера в байтах на ^^блок^^ (по умолчанию 1 МБ), то есть количество гранул в ^^блоке^^ является переменным и зависит от типа данных столбца и распределения. Блоки дополнительно сжимаются для уменьшения их размера и затрат на ввод‑вывод. По умолчанию ClickHouse использует LZ4 [75] в качестве универсального алгоритма сжатия, но пользователи также могут указывать специализированные кодеки, такие как Gorilla [63] или FPC [12] для данных с плавающей запятой. Алгоритмы сжатия также можно компоновать в цепочки. Например, можно сначала уменьшить логическую избыточность числовых значений с помощью delta‑кодирования [23], затем выполнить ресурсоёмкое сжатие и, наконец, зашифровать данные с помощью кодека AES. Блоки распаковываются «на лету» при загрузке их с диска в память. Чтобы обеспечить быстрый произвольный доступ к отдельным гранулам несмотря на сжатие, ClickHouse дополнительно хранит для каждого столбца отображение, которое сопоставляет каждому идентификатору ^^гранулы^^ смещение её содержащего сжатого ^^блока^^ в файле столбца и смещение ^^гранулы^^ в несжатом ^^блоке^^.
Столбцы могут дополнительно кодироваться с помощью ^^dictionary^^-кодирования [2, 77, [81]](#page-13-12) или становиться допускающими значения NULL с помощью двух специальных обёрточных типов данных: LowCardinality(T) заменяет исходные значения столбца целочисленными идентификаторами и таким образом значительно снижает накладные расходы на хранение для данных с небольшим числом уникальных значений. Nullable(T) добавляет внутреннюю битовую маску к столбцу T, указывая, являются ли значения столбца NULL или нет.
Наконец, таблицы могут быть секционированы по диапазону, по хэшу или по принципу round-robin с использованием произвольных выражений секционирования. Чтобы включить отсечение партиций, ClickHouse дополнительно хранит минимальные и максимальные значения выражения секционирования для каждой партиции. Пользователи могут дополнительно создавать более продвинутую статистику по столбцам (например, статистику HyperLogLog [30] или t-digest [28]), которая также предоставляет оценки числа уникальных значений.
3.2 Прореживание данных
В большинстве случаев сканирование петабайтов данных ради одного запроса слишком медленно и дорого. ClickHouse поддерживает три техники прореживания данных, которые позволяют пропускать большую часть строк при поиске и тем самым существенно ускорять запросы.
Во‑первых, пользователи могут определить индекс ^^primary key^^ для таблицы. Столбцы ^^primary key^^ задают порядок сортировки строк внутри каждой части, то есть индекс локально кластеризован. Дополнительно ClickHouse для каждой части хранит отображение от значений столбцов ^^primary key^^ в первой строке каждой ^^granule^^ к идентификатору этой ^^granule^^, то есть индекс разреженный [31]. Получающаяся структура данных обычно достаточно мала, чтобы полностью размещаться в памяти, например, для индексации 8,1 миллиона строк требуется всего 1000 записей. Основное назначение ^^primary key^^ — вычисление предикатов равенства и диапазонных предикатов для часто фильтруемых столбцов с использованием двоичного поиска вместо последовательного сканирования (раздел 4.4). Локальная сортировка также может использоваться при слиянии частей и оптимизации запросов, например, для агрегации на основе сортировки или для удаления операторов сортировки из физического плана выполнения, когда столбцы ^^primary key^^ образуют префикс столбцов сортировки.
Рисунок 4 показывает индекс ^^primary key^^ по столбцу EventTime для таблицы со статистикой показов страниц. Гранулы, удовлетворяющие диапазонному предикату в запросе, можно найти двоичным поиском по индексу ^^primary key^^ вместо последовательного сканирования EventTime.

Рисунок 4: Применение фильтров с помощью индекса ^^primary key^^.
Во‑вторых, пользователи могут создавать проекции таблицы, то есть альтернативные версии таблицы, содержащие те же строки, отсортированные по другому ^^primary key^^ [71]. Проекции позволяют ускорять запросы, которые фильтруют по столбцам, отличным от ^^primary key^^ основной таблицы, ценой увеличения накладных расходов на вставку, слияние и потребление места. По умолчанию проекции заполняются лениво только из ^^parts^^, вновь вставленных в основную таблицу, но не из уже существующих ^^parts^^, пока пользователь не материализует ^^projection^^ целиком. Оптимизатор запросов выбирает между чтением из основной таблицы или ^^projection^^ на основе оценки затрат ввода‑вывода. Если для части нет ^^projection^^, выполнение запроса возвращается к соответствующей части основной таблицы.
В‑третьих, пропускающие индексы представляют собой облегчённую альтернативу проекциям. Идея пропускающих индексов состоит в хранении небольших объёмов метаданных на уровне нескольких последовательных гранул, что позволяет избегать сканирования нерелевантных строк. Пропускающие индексы можно создавать для произвольных индексных выражений с настраиваемой гранулярностью, то есть количеством гранул в блоке ^^skipping index^^. Доступные типы ^^skipping index^^ включают: 1. Индексы min-max [51], хранящие минимальное и максимальное значения индексного выражения для каждого ^^block^^ индекса. Этот тип индекса хорошо работает для локально кластеризованных данных с небольшими абсолютными диапазонами, например, для слабо отсортированных данных. 2. Индексы set (множественные индексы), хранящие настраиваемое количество уникальных значений ^^block^^ индекса. Эти индексы лучше всего использовать с данными с небольшой локальной кардинальностью, то есть когда значения «скучены» вместе. 3. Индексы на основе фильтра Блума [9], строящиеся для строковых, токенных или n‑граммных значений с настраиваемой вероятностью ложноположительных срабатываний. Эти индексы поддерживают текстовый поиск [73], но, в отличие от индексов min-max и set, не могут использоваться для диапазонных или отрицательных предикатов.
3.3 Преобразование данных во время слияния
Сценарии бизнес-аналитики и наблюдаемости часто должны обрабатывать данные, генерируемые с постоянно высокой скоростью или рывками. При этом недавно сгенерированные данные, как правило, более важны для получения значимых аналитических выводов в режиме реального времени, чем исторические данные. Такие сценарии требуют, чтобы базы данных выдерживали высокие скорости ингестии данных, одновременно постоянно уменьшая объём исторических данных с помощью таких техник, как агрегация или «старение» данных. ClickHouse поддерживает непрерывное инкрементальное преобразование уже существующих данных с использованием различных стратегий слияния. Преобразование данных во время слияния не ухудшает производительность операторов INSERT, но не может гарантировать, что таблицы никогда не будут содержать нежелательные (например, устаревшие или неагрегированные) значения. При необходимости все преобразования, выполняемые во время слияния, могут быть применены во время выполнения запроса с помощью ключевого слова FINAL в операторах SELECT.
Слияния типа Replacing сохраняют только самую недавно вставленную версию кортежа на основе временной метки создания части, в которую он входит; более старые версии удаляются. Кортежи считаются эквивалентными, если у них одинаковые значения столбцов ^^primary key^^. Для явного контроля над тем, какой кортеж сохраняется, можно также указать специальный столбец версии для сравнения. Слияния типа Replacing обычно используются как механизм обновления при слиянии (как правило, в сценариях, где обновления происходят часто) или как альтернатива дедупликации данных во время вставки (см. раздел 3.5).
Слияния типа Aggregating объединяют строки с одинаковыми значениями столбцов ^^primary key^^ в одну агрегированную строку. Столбцы, не входящие в ^^primary key^^, должны иметь тип состояния частичной агрегации, которое содержит сводные значения. Два состояния частичной агрегации, например сумма и число для avg(), комбинируются в новое состояние частичной агрегации. Слияния типа Aggregating обычно используются в материализованных представлениях вместо обычных таблиц. Материализованные представления заполняются на основе запроса-преобразования к исходной таблице. В отличие от других баз данных, ClickHouse не обновляет материализованные представления периодически, целиком пересчитывая их по содержимому исходной таблицы. Вместо этого материализованные представления обновляются инкрементально результатом запроса-преобразования при вставке новой части в исходную таблицу.
Рисунок 5 показывает ^^материализованное представление^^, определённое на таблице со статистикой показов страниц. Для новых ^^частей^^, вставленных в исходную таблицу, запрос-преобразование вычисляет максимальные и средние задержки, сгруппированные по регионам, и вставляет результат в ^^материализованное представление^^. Агрегатные функции avg() и max() с суффиксом -State возвращают состояния частичной агрегации вместо фактических результатов. Слияние типа Aggregating, определённое для ^^материализованного представления^^, непрерывно комбинирует состояния частичной агрегации в разных ^^частях^^. Чтобы получить окончательный результат, пользователи консолидируют состояния частичной агрегации в ^^материализованном представлении^^ с помощью avg() и max() с суффиксом -Merge.
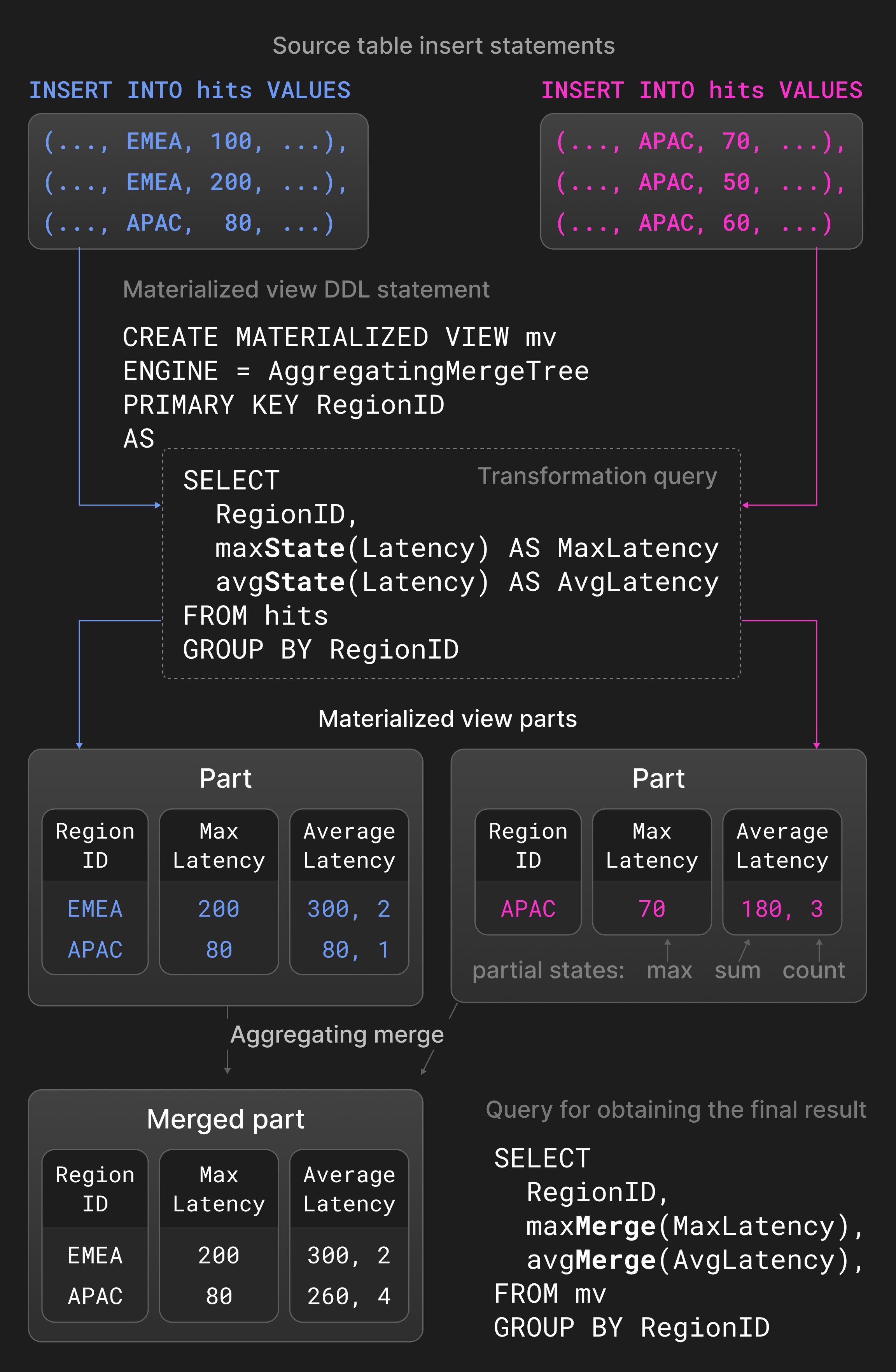
Рисунок 5: Слияния типа Aggregating в материализованных представлениях.
Слияния ^^TTL^^ (time-to-live) обеспечивают «старение» исторических данных. В отличие от удаляющих и агрегирующих слияний, слияния ^^TTL^^ обрабатывают только одну часть за раз. Слияния ^^TTL^^ определяются как набор правил с триггерами и действиями. Триггер — это выражение, вычисляющее временную метку для каждой строки, которая сравнивается с моментом времени запуска слияния ^^TTL^^. Хотя это позволяет пользователям управлять действиями на уровне отдельных строк, на практике мы считаем достаточным проверять, удовлетворяют ли все строки заданному условию, и выполнять действие над всей частью. Возможные действия включают: 1. переместить часть на другой том хранения (например, более дешёвое и медленное хранилище), 2. перекомпрессировать часть (например, более ресурсоёмким кодеком), 3. удалить часть и 4. выполнить roll-up, то есть агрегировать строки с использованием ключа группировки и агрегатных функций.
В качестве примера рассмотрим определение таблицы логов в Листинге 1. ClickHouse переместит ^^части^^ со значениями в столбце timestamp старше одной недели в медленное, но недорогое объектное хранилище S3.
Листинг 1: Перемещение части в объектное хранилище спустя неделю.
3.4 Обновления и удаления
Архитектура движков таблиц семейства ^^MergeTree^^* оптимизирована под сценарии с только добавлением данных, однако в некоторых случаях требуется периодически изменять существующие данные, например для соблюдения нормативных требований. Существуют два подхода к обновлению или удалению данных, и ни один из них не ^^блокирует^^ параллельные вставки.
Мутации переписывают все ^^части^^ таблицы на месте. Чтобы предотвратить временное двукратное увеличение размера таблицы (при удалении) или столбца (при обновлении), эта операция не является атомарной, то есть параллельные запросы SELECT могут читать как изменённые, так и неизменённые ^^части^^. Мутации гарантируют, что данные физически изменены к моменту завершения операции. Мутации удаления по‑прежнему дорогостоящи, так как они переписывают все столбцы во всех ^^частях^^.
В качестве альтернативы облегчённые удаления изменяют только внутренний столбец‑битовую карту, указывающий, удалена строка или нет. ClickHouse дополняет запросы SELECT дополнительным фильтром по этому столбцу‑битовой карте, чтобы исключить удалённые строки из результата. Физическое удаление строк происходит только при обычных слияниях в неопределённый момент времени в будущем. В зависимости от количества столбцов, облегчённые удаления могут быть значительно быстрее мутаций, ценой более медленных запросов SELECT.
Ожидается, что операции обновления и удаления, выполняемые над одной и той же таблицей, будут редкими и сериализованными, чтобы избежать логических конфликтов.
3.5 Идемпотентные вставки
Распространённая на практике проблема заключается в том, как клиентам обрабатывать тайм-ауты соединения после отправки данных на сервер для вставки в таблицу. В такой ситуации клиентам сложно определить, были ли данные успешно вставлены или нет. Традиционное решение — повторно отправить данные с клиента на сервер и полагаться на ограничения первичного ключа ^^primary key^^ или уникальные ограничения, чтобы отклонить повторные вставки. Базы данных выполняют необходимые точечные запросы быстро, используя структуры индексов на основе бинарных деревьев [39, [68]](#page-13-16), radix-деревьев [45] или хеш-таблиц [29]. Поскольку эти структуры данных индексируют каждую строку, их накладные расходы по памяти и обновлениям становятся неприемлемыми для больших наборов данных и высоких скоростей приёма.
ClickHouse предоставляет более лёгкую альтернативу, основанную на том, что каждая вставка в итоге создаёт часть. Более конкретно, сервер хранит хэши N последних вставленных ^^частей^^ (например, N=100) и игнорирует повторные вставки ^^частей^^ с известным хэшем. Хэши для нереплицируемых и реплицируемых таблиц хранятся локально и в Keeper соответственно. В результате вставки становятся идемпотентными, т.е. клиенты могут просто повторно отправить тот же пакет строк после тайм-аута и считать, что сервер займётся дедупликацией. Для более тонкого контроля над процессом дедупликации клиенты могут дополнительно передать токен вставки, который используется как хэш части. Хотя дедупликация на основе хэшей влечёт накладные расходы, связанные с хешированием новых строк, стоимость хранения и сравнения хэшей пренебрежимо мала.
3.6 Репликация данных
Репликация является необходимым условием высокой доступности (устойчивости к отказам узлов), а также используется для балансировки нагрузки и обновлений без простоя [14]. В ClickHouse репликация основана на понятии состояний таблиц, которые состоят из набора ^^частей^^ таблицы (раздел 3.1) и метаданных таблицы, таких как имена и типы столбцов. Узлы изменяют состояние таблицы с помощью трёх операций: 1. операции вставки добавляют новую часть к состоянию, 2. операции слияния добавляют новую часть и удаляют существующие ^^части^^ из состояния, 3. мутации и DDL-операторы добавляют ^^части^^ и/или удаляют ^^части^^ и/или изменяют метаданные таблицы в зависимости от конкретной операции. Операции выполняются локально на одном узле и записываются в виде последовательности переходов состояния в глобальном журнале репликации.
Журнал репликации обслуживается ансамблем из обычно трёх процессов ClickHouse Keeper, которые используют алгоритм консенсуса Raft [59] для обеспечения распределённого и отказоустойчивого координационного слоя для ^^кластера^^ узлов ClickHouse. Все узлы ^^кластера^^ изначально указывают на одну и ту же позицию в журнале репликации. Пока узлы выполняют локальные вставки, слияния, мутации и DDL-операторы, журнал репликации асинхронно воспроизводится на всех остальных узлах. В результате реплицируемые таблицы являются лишь в конечном счёте согласованными, то есть узлы могут временно читать старые состояния таблиц, пока они сходятся к последнему состоянию. Большинство упомянутых выше операций могут, как альтернатива, выполняться синхронно до тех пор, пока кворум узлов (например, большинство узлов или все узлы) не примет новое состояние.
В качестве примера рисунок 6 показывает изначально пустую реплицируемую таблицу в ^^кластере^^ из трёх узлов ClickHouse. Узел 1 сначала получает два оператора вставки и записывает их ( 1 2 ) в журнал репликации, хранящийся в ансамбле Keeper. Затем узел 2 воспроизводит первую запись журнала, извлекая её ( 3 ) и загружая новую часть с узла 1 ( 4 ), тогда как узел 3 воспроизводит обе записи журнала ( 3 4 5 6 ). Наконец, узел 3 объединяет обе ^^части^^ в новую часть, удаляет входные ^^части^^ и записывает запись о слиянии в журнал репликации ( 7 ).
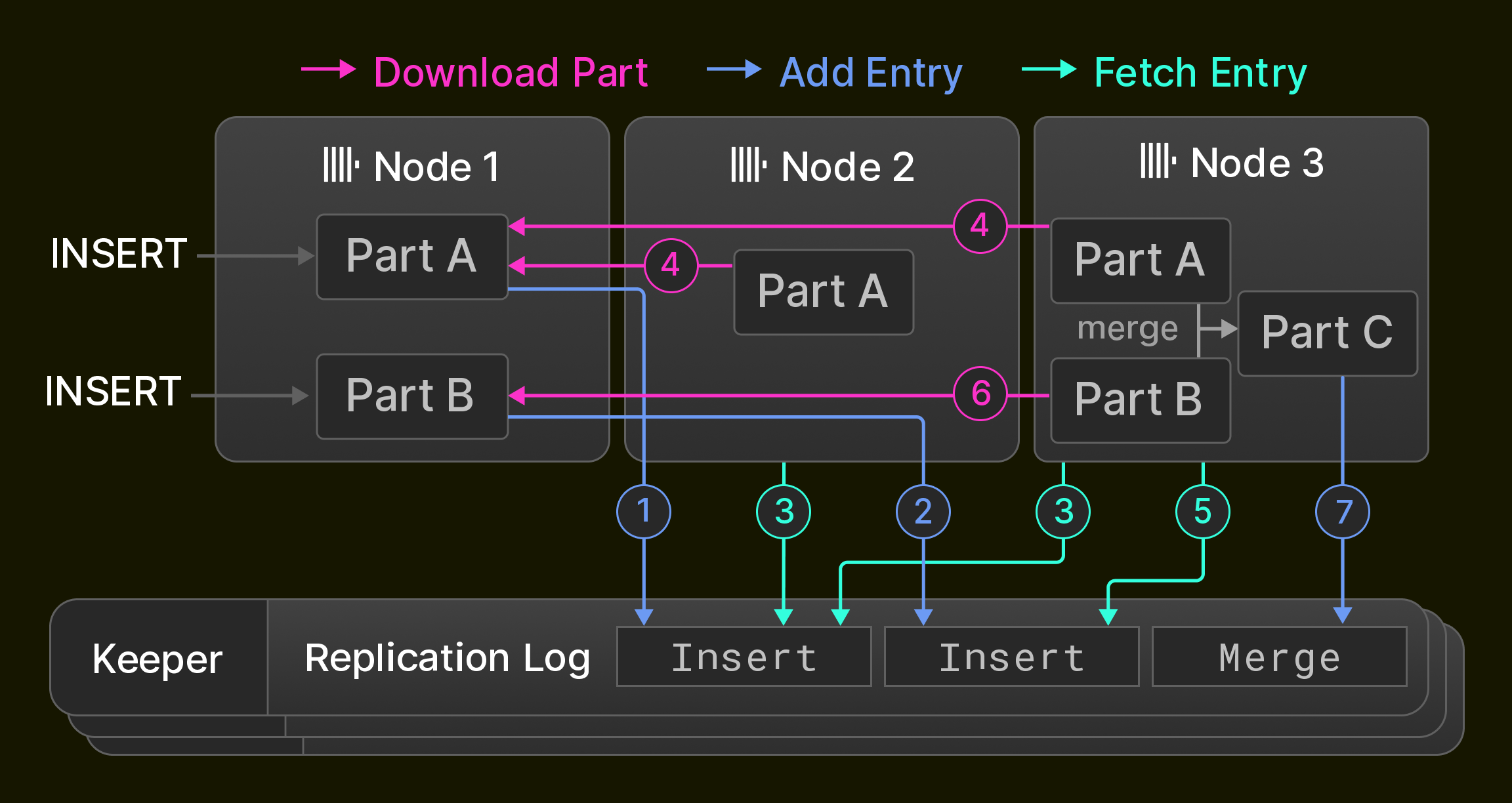
Рисунок 6. Репликация в ^^кластере^^ из трёх узлов.
Существуют три оптимизации для ускорения синхронизации: во‑первых, новые узлы, добавляемые в ^^кластер^^, не выполняют воспроизведение журнала репликации с нуля, вместо этого они просто копируют состояние узла, который записал последнюю запись журнала репликации. Во‑вторых, слияния воспроизводятся либо путём их повторения локально, либо путём получения результирующей части с другого узла. Точное поведение настраивается и позволяет балансировать потребление CPU и сетевого ввода‑вывода. Например, междатацентровая репликация обычно предпочитает локальные слияния для минимизации операционных затрат. В‑третьих, узлы воспроизводят взаимно независимые записи журнала репликации параллельно. Это включает, например, выборки новых ^^частей^^, последовательно вставленных в одну и ту же таблицу, или операции над разными таблицами.
3.7 Соответствие ACID
Чтобы максимально повысить производительность одновременных операций чтения и записи, ClickHouse по возможности избегает блокировок. Запросы выполняются над снимком всех ^^parts^^ во всех задействованных таблицах, созданным в начале выполнения запроса. Это гарантирует, что новые ^^parts^^, вставленные параллельными операциями INSERT или в результате слияний (раздел 3.1), не участвуют в выполнении запроса. Чтобы предотвратить одновременное изменение или удаление ^^parts^^ (раздел 3.4), на время выполнения запроса увеличивается счетчик ссылок на обрабатываемые ^^parts^^. Формально это соответствует изоляции на основе моментального снимка, реализованной вариантом MVCC [6], основанным на версионируемых ^^parts^^. В результате операторы в общем случае не являются ACID-соответствующими, за исключением редких случаев, когда параллельные операции записи на момент создания снимка затрагивают каждая лишь один ^^part^^.
На практике большинство сценариев использования ClickHouse для принятия решений с интенсивной записью допускают небольшой риск потери новых данных в случае отключения питания. База данных использует это, по умолчанию не форсируя фиксацию (fsync) недавно вставленных ^^parts^^ на диск, что позволяет ядру объединять операции записи ценой отказа от строгой ^^atomicity^^.
4 УРОВЕНЬ ОБРАБОТКИ ЗАПРОСОВ
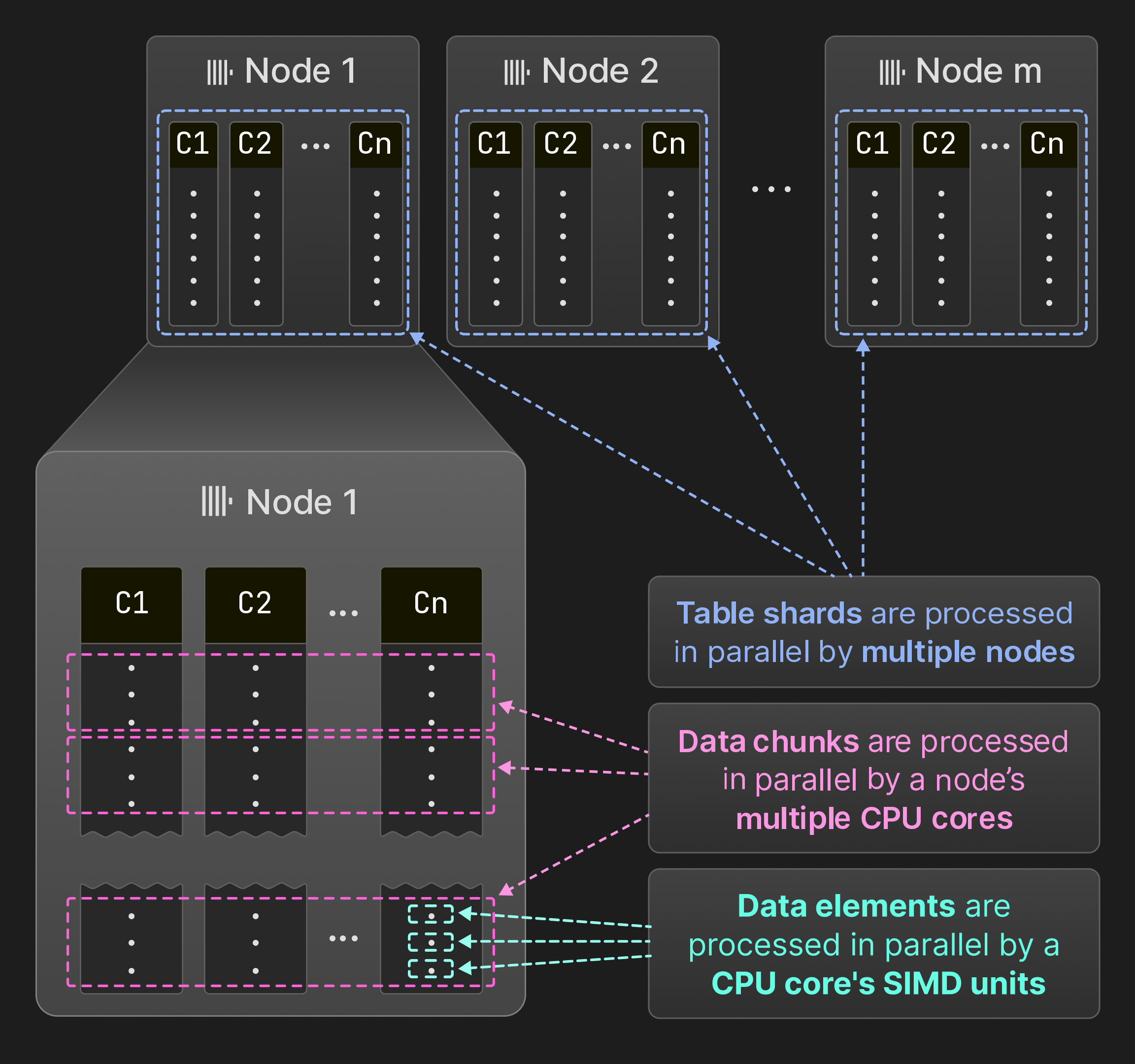
Рисунок 7: Параллелизация по SIMD‑блокам, ядрам и узлам.
Как показано на рисунке 7, ClickHouse параллелизует запросы на уровне элементов данных, блоков данных и шардов таблиц. Несколько элементов данных могут обрабатываться операторами одновременно с использованием SIMD‑инструкций. На одном узле движок выполнения запросов одновременно исполняет операторы в нескольких потоках. ClickHouse использует ту же модель векторизации, что и MonetDB/X100 [11], то есть операторы производят, передают и потребляют сразу несколько строк (блоков данных) вместо одиночных строк, чтобы минимизировать накладные расходы на вызовы виртуальных функций. Если исходная таблица разбита на непересекающиеся шарды, несколько узлов могут сканировать шарды одновременно. В результате все аппаратные ресурсы используются полностью, а обработка запросов может масштабироваться горизонтально за счёт добавления узлов и вертикально за счёт добавления ядер.
Оставшаяся часть этого раздела сначала более подробно описывает параллельную обработку на уровне элементов данных, блоков данных и ^^шардов^^. Затем мы представим отдельные ключевые оптимизации для максимального повышения производительности запросов. Наконец, мы обсудим, как ClickHouse управляет общими системными ресурсами при одновременном выполнении запросов.
4.1 SIMD-параллелизм
Передача нескольких строк между операторами создаёт возможность для векторизации. Векторизация либо основывается на вручную написанных intrinsic-функциях [64, [80]](#page-13-19), либо выполняется компилятором автоматически (auto-vectorization) [25]. Код, который выигрывает от векторизации, компилируется в разные вычислительные ядра (kernels). Например, внутренний горячий цикл оператора запроса может быть реализован в виде невекторизованного ядра, автоматически векторизованного ядра AVX2 и вручную векторизованного ядра AVX-512. Самое быстрое ядро выбирается во время выполнения на основе инструкции cpuid. Такой подход позволяет ClickHouse выполняться на системах возрастом до 15 лет (минимальное требование — SSE 4.2), при этом обеспечивая значительный прирост скорости на современном оборудовании.
4.2 Параллелизация на многоядерных системах
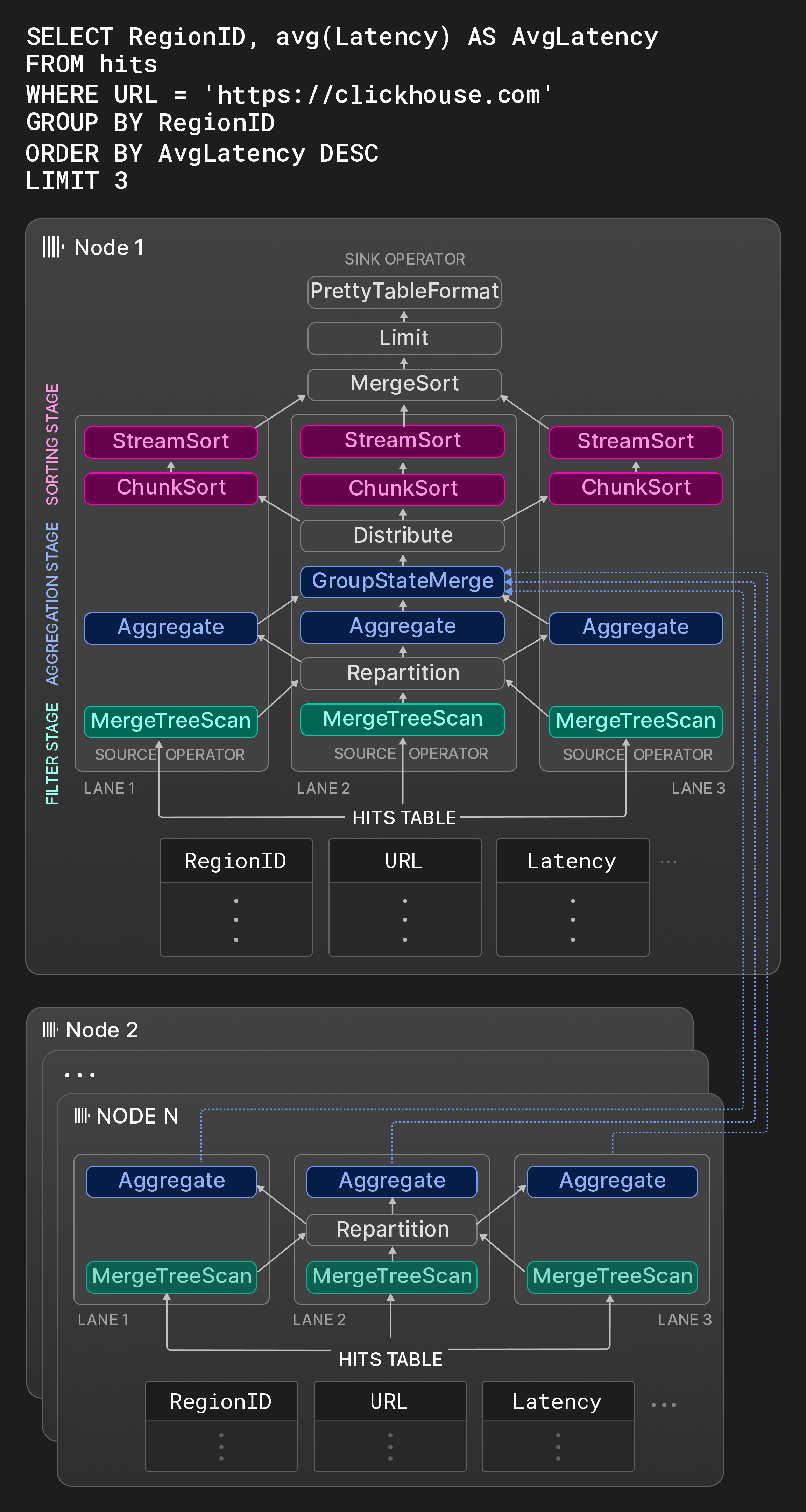
Рисунок 8: План физических операторов с тремя линиями.
ClickHouse следует традиционному подходу [31] преобразования SQL-запросов в ориентированный граф физических операторов плана. Вход плана операторов представлен особыми операторами-источниками, которые читают данные в нативном или любом из поддерживаемых сторонних форматов (см. раздел 5). Аналогично, специальный оператор-приёмник конвертирует результат в требуемый формат вывода. Физический план операторов разворачивается на этапе компиляции запроса в независимые линии выполнения на основе настраиваемого максимального числа рабочих потоков (по умолчанию — количества ядер) и размера исходной таблицы. Линии разбивают обрабатываемые параллельными операторами данные на непересекающиеся диапазоны. Чтобы максимально использовать возможности параллельной обработки, линии объединяются как можно позже.
В качестве примера, блок для узла 1 на рисунке 8 показывает граф операторов типичного OLAP-запроса к таблице со статистикой показов страниц. На первом этапе три непересекающихся диапазона исходной таблицы одновременно фильтруются. Оператор обмена Repartition динамически направляет полученные чанки между первым и вторым этапами, чтобы поддерживать равномерную загрузку потоков обработки. После первого этапа линии могут стать несбалансированными, если просканированные диапазоны имеют сильно различающиеся селективности. На втором этапе строки, прошедшие фильтрацию, группируются по RegionID. Операторы Aggregate поддерживают локальные группы результатов с RegionID в качестве группирующего столбца и суммой и счётчиком на группу в качестве частичного состояния агрегации для avg(). Локальные результаты агрегации в итоге объединяются оператором GroupStateMerge в глобальный результат агрегации. Этот оператор также является разрывом конвейера, т.е. третий этап может начаться только после полного вычисления результата агрегации. На третьем этапе группы результатов сначала делятся оператором обмена Distribute на три одинаковых по размеру непересекающихся раздела, которые затем сортируются по AvgLatency. Сортировка выполняется в три шага: сначала операторы ChunkSort сортируют отдельные чанки каждого раздела. Затем операторы StreamSort поддерживают локальный отсортированный результат, который объединяется с поступающими отсортированными чанками с помощью двухпутевой сортировки слиянием. Наконец, оператор MergeSort комбинирует локальные результаты с использованием k-путевой сортировки для получения окончательного результата.
Операторы являются конечными автоматами и соединены друг с другом через входные и выходные порты. Три возможных состояния оператора: need-chunk, ready и done. Для перехода из need-chunk в ready чанк помещается во входной порт оператора. Для перехода из ready в done оператор обрабатывает входной чанк и генерирует выходной чанк. Для перехода из done в need-chunk выходной чанк удаляется из выходного порта оператора. Первый и третий переходы состояний в двух соединённых операторах могут выполняться только в одном комбинированном шаге. Операторы-источники (операторы-приёмники) имеют только состояния ready и done (need-chunk и done).
Рабочие потоки непрерывно обходят физический план операторов и выполняют переходы состояний. Чтобы эффективнее использовать кэш CPU, план содержит подсказки о том, что один и тот же поток должен последовательно обрабатывать соседние операторы в одной линии. Параллельная обработка осуществляется как по горизонтали на непересекающихся входах внутри этапа (например, на рисунке 8 операторы Aggregate выполняются одновременно), так и по вертикали между этапами, не разделёнными разрывами конвейера (например, на рисунке 8 операторы Filter и Aggregate в одной линии могут выполняться одновременно). Чтобы избежать избыточного или недостаточного использования потоков при запуске новых запросов или завершении конкурентных запросов, степень параллелизма может изменяться в середине запроса между одним и максимальным числом рабочих потоков для запроса, заданным при его запуске (см. раздел 4.5).
Операторы могут дополнительно влиять на выполнение запроса во время работы двумя способами. Во-первых, операторы могут динамически создавать и подключать новые операторы. Это в основном используется для переключения на внешние алгоритмы агрегации, сортировки или соединения вместо отмены запроса, когда потребление памяти превышает настраиваемый порог. Во-вторых, операторы могут запрашивать перевод рабочих потоков в асинхронную очередь. Это обеспечивает более эффективное использование рабочих потоков при ожидании удалённых данных.
Движок выполнения запросов ClickHouse и параллелизм на основе мелких порций (morsel-driven parallelism) [44] схожи в том, что «ленты» обычно выполняются на разных ядрах / NUMA-сокетах, а рабочие потоки могут забирать задачи из других лент. Кроме того, отсутствует центральный компонент планировщика: вместо этого рабочие потоки выбирают задачи самостоятельно, непрерывно проходя по плану операторов. В отличие от параллелизма на основе мелких порций, ClickHouse «зашивает» максимальную степень параллелизма непосредственно в план и использует значительно более крупные диапазоны для разбиения исходной таблицы по сравнению с типичными размерами порций (morsel) порядка 100 000 строк. Хотя это в некоторых случаях может приводить к задержкам (например, когда время выполнения операторов фильтрации в разных лентах сильно различается), мы видим, что широкое использование операторов обмена, таких как Repartition, по крайней мере не позволяет подобным дисбалансам накапливаться между стадиями.
4.3 Параллелизация на нескольких узлах
Если исходная таблица запроса разбита на шарды, оптимизатор запросов на узле, получившем запрос (инициирующий узел), пытается выполнить как можно больше работы на других узлах. Результаты с других узлов могут встраиваться в разные точки плана запроса. В зависимости от запроса удалённые узлы могут: 1) передавать исходные столбцы таблицы в потоковом режиме на инициирующий узел, 2) фильтровать исходные столбцы и отправлять только прошедшие строки, 3) выполнять шаги фильтрации и агрегации и отправлять локальные группы результатов с частичными состояниями агрегирования или 4) выполнять весь запрос, включая фильтрацию, агрегацию и сортировку.
Узлы 2 ... N на Рисунке 8 показывают фрагменты плана, выполняемые на других узлах, содержащих шарды таблицы hits. Эти узлы фильтруют и группируют локальные данные и отправляют результаты на инициирующий узел. Оператор GroupStateMerge на узле 1 объединяет локальные и удалённые результаты до того, как группы результатов будут окончательно отсортированы.
4.4 Комплексная оптимизация производительности
В этом разделе представлены ключевые оптимизации производительности, применяемые на разных стадиях выполнения запроса.
Оптимизация запросов. Первый набор оптимизаций применяется к семантическому представлению запроса, полученному из AST запроса. Примеры таких оптимизаций включают свёртку констант (например, concat(lower('a'),upper('b')) превращается в 'aB'), вынесение скаляров из некоторых агрегатных функций (например, sum(a*2) превращается в 2 * sum(a)), устранение общих подвыражений и преобразование дизъюнкций фильтров равенства в IN-списки (например, x=c OR x=d превращается в x IN (c,d)). Оптимизированное семантическое представление запроса затем преобразуется в план логических операторов. Оптимизации поверх логического плана включают проталкивание фильтров, переупорядочивание вычисления функций и шагов сортировки в зависимости от того, какой из них оценивается как более затратный. Наконец, логический план запроса преобразуется в план физических операторов. Это преобразование может использовать особенности задействованных движков таблиц. Например, в случае движка таблиц ^^MergeTree^^, если столбцы ORDER BY образуют префикс ^^primary key^^, данные могут считываться в дисковом порядке, и операторы сортировки могут быть удалены из плана. Также, если группирующие столбцы в агрегировании образуют префикс ^^primary key^^, ClickHouse может использовать сортировочное агрегирование [33], т.е. напрямую агрегировать серии одинаковых значений во входных данных, уже отсортированных заранее. По сравнению с хеш-агрегированием сортировочное агрегирование значительно менее требовательно к памяти, и агрегированное значение может быть передано следующему оператору сразу после обработки серии.
Компиляция запросов. ClickHouse использует компиляцию запросов на основе LLVM для динамического объединения соседних операторов плана [38, [53]](#page-13-0). Например, выражение a * b + c + 1 может быть объединено в один оператор вместо трёх операторов. Помимо выражений, ClickHouse также использует компиляцию для одновременной оценки нескольких агрегатных функций (т.е. для GROUP BY) и для сортировки по более чем одному ключу сортировки. Компиляция запросов уменьшает количество виртуальных вызовов, удерживает данные в регистрах или кэшах CPU и помогает предсказателю переходов, так как нужно выполнять меньше кода. Кроме того, компиляция во время выполнения позволяет использовать широкий набор оптимизаций, таких как логические оптимизации и peephole-оптимизации, реализованные в компиляторах, и даёт доступ к самым быстрым доступным локально инструкциям CPU. Компиляция запускается только тогда, когда одно и то же обычное, агрегатное или сортировочное выражение выполняется разными запросами больше, чем заданное (конфигурируемое) число раз. Скомпилированные операторы запросов кешируются и могут переиспользоваться последующими запросами.[7]
Оценка индекса ^^primary key^^. ClickHouse оценивает условия WHERE с использованием индекса ^^primary key^^, если подмножество фильтрующих предложений в конъюнктивной нормальной форме условия образует префикс столбцов ^^primary key^^. Индекс ^^primary key^^ анализируется слева направо на лексикографически отсортированных диапазонах значений ключей. Фильтрующие предложения, соответствующие столбцу ^^primary key^^, оцениваются с использованием троичной логики: они либо все истинны, либо все ложны, либо часть истинна, а часть ложна для значений в диапазоне. В последнем случае диапазон разбивается на поддиапазоны, которые анализируются рекурсивно. Дополнительные оптимизации существуют для функций в фильтрующих условиях. Во-первых, у функций есть свойства, описывающие их монотонность, например, toDayOfMonth(date) является кусочно-монотонной внутри месяца. Свойства монотонности позволяют определить, выдаёт ли функция отсортированные результаты на отсортированных диапазонах входных значений ключа. Во-вторых, некоторые функции могут вычислять прообраз для заданного результата функции. Это используется для замены сравнений констант с вызовами функций от столбцов ключа на сравнение значения столбца ключа с прообразом. Например, toYear(k) = 2024 можно заменить на k >= 2024-01-01 && k < 2025-01-01.
Пропуск данных. ClickHouse старается избегать чтения данных во время выполнения запроса, используя структуры данных, представленные в разделе 3.2. Кроме того, фильтры по разным столбцам оцениваются последовательно в порядке убывания предполагаемой селективности на основе эвристик и (необязательной) статистики по столбцам. Только те блоки данных, которые содержат хотя бы одну подходящую строку, передаются к следующему предикату. Это постепенно уменьшает объём прочитанных данных и количество вычислений, выполняемых от предиката к предикату. Оптимизация применяется только тогда, когда присутствует хотя бы один высокоселективный предикат; в противном случае задержка выполнения запроса ухудшилась бы по сравнению с оценкой всех предикатов параллельно.
Хеш-таблицы. Хеш-таблицы являются фундаментальными структурами данных для агрегаций и хеш-соединений. Выбор правильного типа хеш-таблицы критически важен для производительности. ClickHouse создаёт различные хеш-таблицы (более 30 по состоянию на март 2024 года) из обобщённого шаблона хеш-таблицы, используя функцию хеширования, аллокатор, тип ячейки и политику изменения размера как точки вариации. В зависимости от типа данных группирующих столбцов, оцениваемой мощности множества ключей в хеш-таблице и других факторов для каждого оператора запроса индивидуально выбирается самая быстрая хеш-таблица. Дополнительные оптимизации, реализованные для хеш-таблиц, включают:
- двухуровневую организацию с 256 подтаблицами (на основе первого байта хеша) для поддержки очень больших множеств ключей,
- строковые хеш-таблицы [79] с четырьмя подтаблицами и разными функциями хеширования для строк разной длины,
- таблицы поиска, которые используют ключ непосредственно как индекс бакета (т. е. без хеширования), когда ключей немного,
- значения со встроенными хешами для более быстрого разрешения коллизий, когда сравнение дорогостоящее (например, строки, AST),
- создание хеш-таблиц на основе предсказанных размеров из статистики времени выполнения, чтобы избежать лишних изменений размера,
- выделение нескольких небольших хеш-таблиц с одинаковым жизненным циклом создания/уничтожения на одном фрагменте памяти (slab),
- мгновенную очистку хеш-таблиц для повторного использования с помощью счётчиков версий на уровне каждой хеш-таблицы и каждой ячейки,
- использование предвыборки CPU (__builtin_prefetch) для ускорения получения значений после хеширования ключа.
Соединения (joins). Поскольку изначально ClickHouse поддерживал соединения лишь в зачаточном виде, во многих сценариях исторически использовались денормализованные таблицы. Сегодня база данных предлагает все типы соединений, доступные в SQL (inner, left-/right/full outer, cross, as-of), а также различные алгоритмы соединений, такие как хеш-соединение (наивное, grace), сортировочно-слияющее соединение и индексное соединение для движков таблиц с быстрым поиском по ключу (обычно словари).
Так как соединения относятся к числу самых дорогостоящих операций в базе данных, важно иметь параллельные варианты классических алгоритмов соединений, желательно с настраиваемыми компромиссами между временем и памятью. Для хеш-соединений ClickHouse реализует неблокирующий алгоритм разделяемых партиций из [7]. Например, запрос на рисунке 9 вычисляет, как пользователи переходят между URL-адресами, с помощью самосоединения таблицы со статистикой по просмотрам страниц. Фаза построения соединения разбивается на три потока, охватывающие три непересекающихся диапазона исходной таблицы. Вместо глобальной хеш-таблицы используется партиционированная хеш-таблица. Обычно три рабочих потока определяют целевую партицию для каждой входной строки на стороне построения, вычисляя остаток от деления значения хеша. Доступ к партициям хеш-таблицы синхронизируется с помощью операторов обмена Gather. Фаза пробного поиска (probe) аналогично находит целевую партицию для своих входных кортежей. Хотя этот алгоритм добавляет по два дополнительных вычисления хеша на кортеж, он существенно снижает конкуренцию за блокировки в фазе построения в зависимости от количества партиций хеш-таблицы.
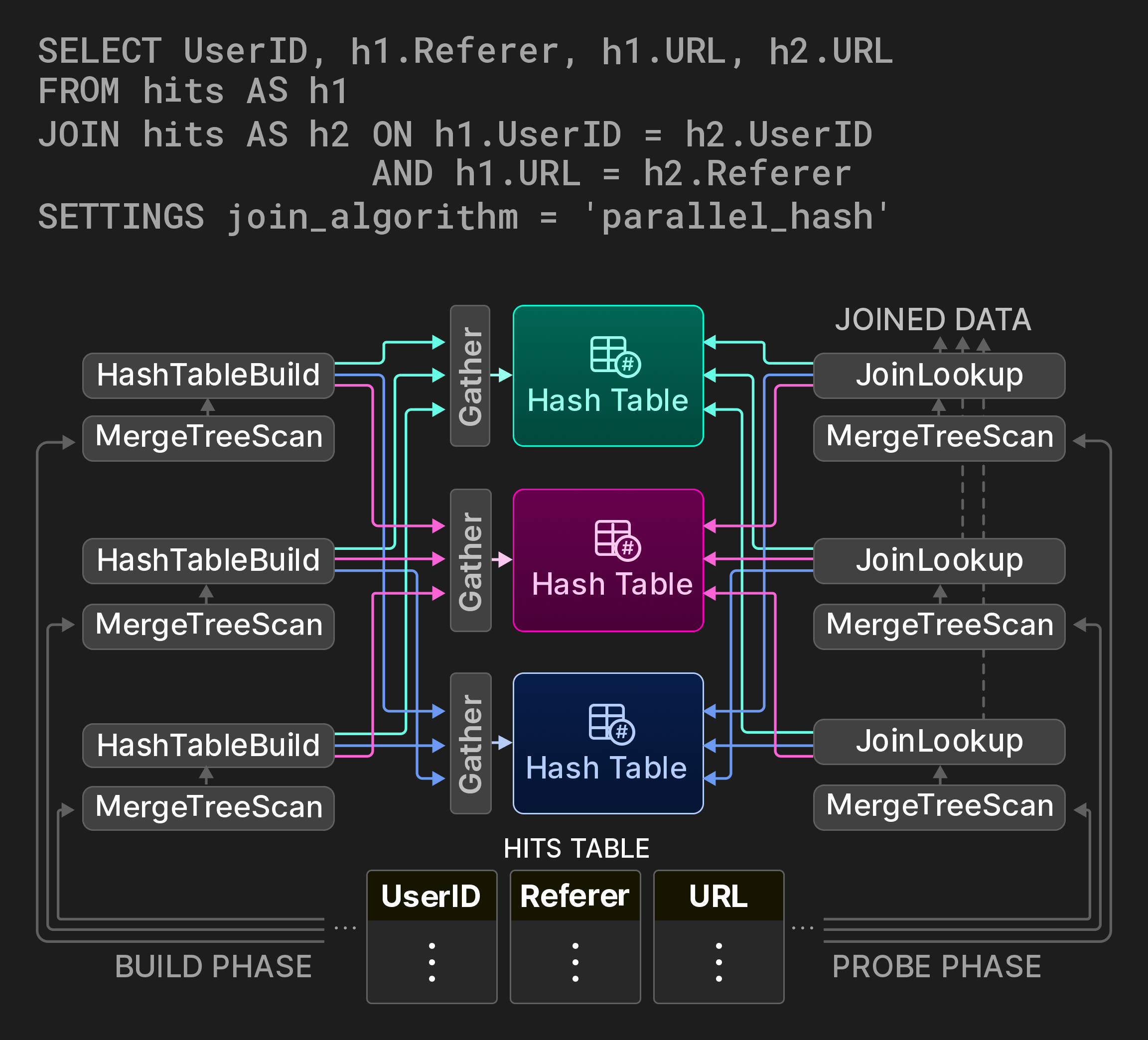
Рисунок 9: Параллельное хеш-соединение с тремя партициями хеш-таблицы.
4.5 Изоляция нагрузок
ClickHouse предоставляет управление параллелизмом, лимиты использования памяти и планирование ввода-вывода (I/O), что позволяет разделять запросы по классам рабочих нагрузок. Ограничивая использование общих ресурсов (CPU‑ядра, DRAM, дисковый и сетевой I/O) для конкретных классов нагрузок, система гарантирует, что эти запросы не будут влиять на другие критически важные бизнес‑запросы.
Управление параллелизмом предотвращает избыточное количество потоков в сценариях с большим числом параллельных запросов. Точнее, количество рабочих потоков на запрос динамически подстраивается исходя из заданного отношения к числу доступных CPU‑ядер.
ClickHouse отслеживает объём выделенной памяти в байтах на уровне сервера, пользователя и запроса, что позволяет задавать гибкие лимиты использования памяти. Механизм overcommit памяти позволяет запросам использовать дополнительную свободную память сверх гарантированной, при этом соблюдая лимиты памяти для других запросов. Кроме того, использование памяти для операций агрегирования, сортировки и соединения можно ограничить, что при превышении лимита памяти приводит к использованию внешних алгоритмов.
Наконец, планирование I/O позволяет ограничивать локальные и удалённые дисковые обращения для классов нагрузок на основе максимальной пропускной способности, числа активных запросов и политики (например, FIFO, SFC [32]).
5 ИНТЕГРАЦИОННЫЙ УРОВЕНЬ
Приложения для принятия решений в режиме реального времени часто зависят от эффективного и малозадержочного доступа к данным, расположенным в нескольких местах. Существуют два подхода к тому, чтобы сделать внешние данные доступными в OLAP-базе данных. При push-ориентированном доступе к данным сторонний компонент связывает базу данных с внешними хранилищами данных. Примером этого являются специализированные инструменты extract-transform-load (ETL), которые отправляют удалённые данные в целевую систему. В pull-ориентированной модели сама база данных подключается к удалённым источникам данных и извлекает данные для запросов во временные локальные таблицы или экспортирует данные во внешние системы. Хотя push-подходы более универсальны и распространены, они влекут за собой более сложную архитектуру и узкие места масштабирования. Напротив, удалённые подключения непосредственно из базы данных предоставляют интересные возможности, такие как объединения между локальными и удалёнными данными, при этом сохраняя архитектуру простой и сокращая время получения аналитических выводов.
Оставшаяся часть этого раздела рассматривает pull-ориентированные методы интеграции данных в ClickHouse, предназначенные для доступа к данным в удалённых местоположениях. Отметим, что идея удалённых подключений в SQL-базах данных не нова. Например, стандарт SQL/MED [35], представленный в 2001 году и реализованный в PostgreSQL с 2011 года [65], предлагает foreign data wrappers как единый интерфейс для управления внешними данными. Максимальная совместимость с другими хранилищами данных и форматами хранения является одной из целей проектирования ClickHouse. По состоянию на март 2024 года ClickHouse, насколько нам известно, предлагает наибольшее количество встроенных вариантов интеграции данных среди всех аналитических баз данных.
Внешние подключения. ClickHouse предоставляет 50+ интеграционных табличных функций и движков для подключения к внешним системам и хранилищам, включая ODBC, MySQL, PostgreSQL, SQLite, Kafka, Hive, MongoDB, Redis, объектные хранилища S3/GCP/Azure и различные data lake-хранилища. Мы далее разбиваем их на категории, показанные на следующем бонусном рисунке (не является частью исходной статьи vldb).
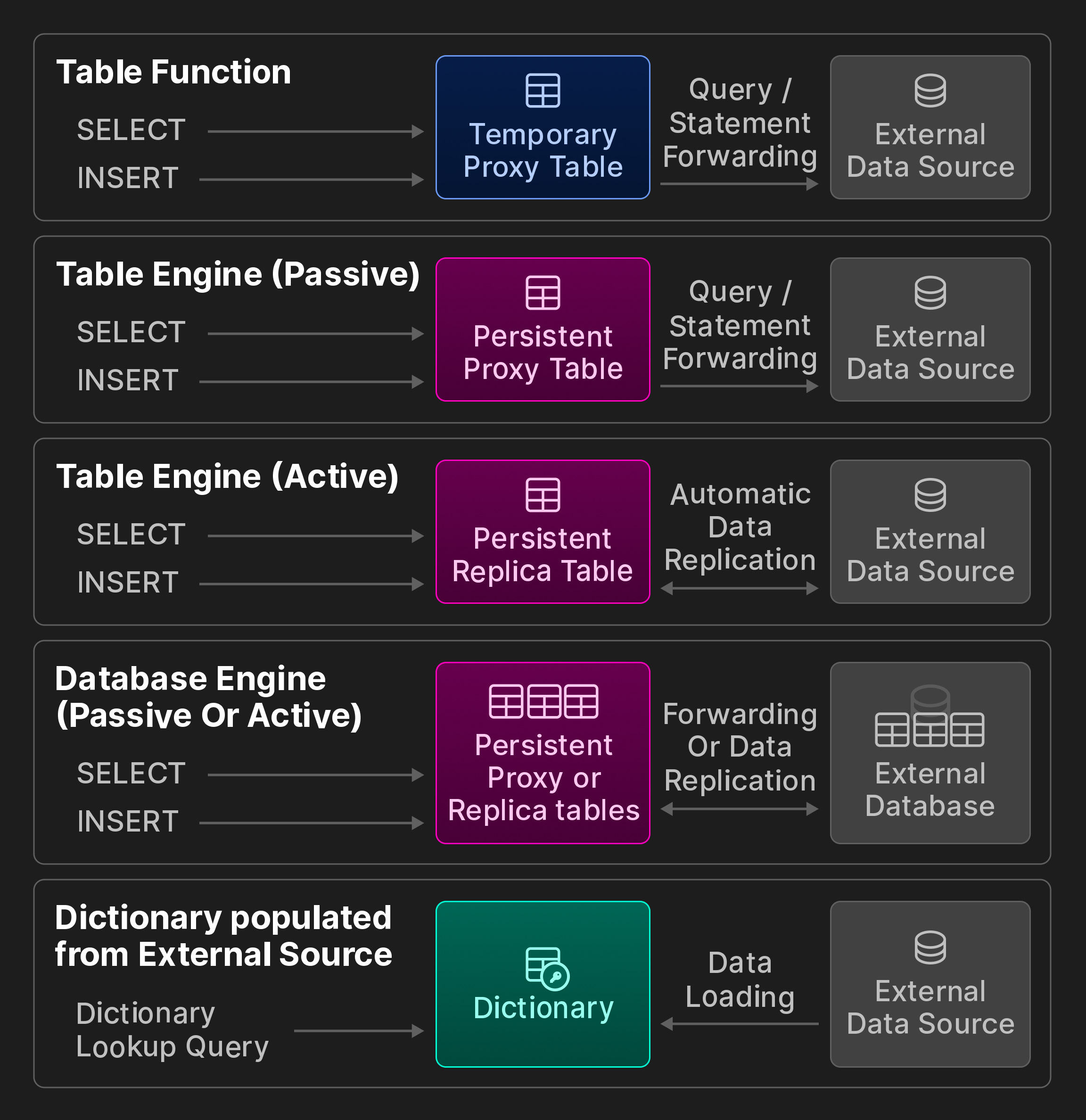
Бонусный рисунок: варианты интероперабельности ClickBench.
Временный доступ с помощью интеграционных табличных функций. Табличные функции могут вызываться в предложении FROM запросов SELECT для чтения удалённых данных при исследовательских ad-hoc-запросах. Альтернативно, их можно использовать для записи данных во внешние хранилища с помощью операторов INSERT INTO TABLE FUNCTION.
Постоянный доступ. Существует три способа создать постоянные соединения с удалёнными хранилищами данных и системами обработки.
Во-первых, интеграционные табличные движки представляют удалённый источник данных, такой как таблица MySQL, в виде постоянной локальной таблицы. Пользователи сохраняют определение таблицы с помощью синтаксиса CREATE TABLE AS в комбинации с запросом SELECT и табличной функцией. Можно указать пользовательскую схему, например, чтобы ссылаться только на подмножество удалённых столбцов, или использовать вывод схемы для автоматического определения имён столбцов и эквивалентных типов ClickHouse. Мы дополнительно различаем пассивное и активное поведение во время выполнения: пассивные табличные движки перенаправляют запросы во внешнюю систему и заполняют локальную прокси-таблицу результатом. Напротив, активные табличные движки периодически извлекают данные из внешней системы или подписываются на удалённые изменения, например, через протокол логической репликации PostgreSQL. В результате локальная таблица содержит полную копию удалённой таблицы.
Во-вторых, интеграционные движки баз данных отображают все таблицы схемы во внешнем хранилище данных в ClickHouse. В отличие от предыдущего варианта, они, как правило, требуют, чтобы удалённое хранилище данных было реляционной базой данных, и дополнительно предоставляют ограниченную поддержку операторов DDL.
В-третьих, словари могут заполняться с помощью произвольных запросов практически ко всем возможным источникам данных с использованием соответствующей интеграционной табличной функции или движка. Поведение во время выполнения является активным, поскольку данные извлекаются с фиксированными интервалами из удалённого хранилища.
Форматы данных. Для взаимодействия со сторонними системами современные аналитические базы данных также должны уметь обрабатывать данные в любом формате. Помимо собственного формата, ClickHouse поддерживает 90+ форматов, включая CSV, JSON, Parquet, Avro, ORC, Arrow и Protobuf. Каждый формат может быть входным форматом (который ClickHouse может читать), выходным форматом (который ClickHouse может экспортировать) или обоими. Некоторые ориентированные на аналитику форматы, такие как Parquet, также интегрированы с обработкой запросов, то есть оптимизатор может использовать встроенную статистику, а фильтры вычисляются непосредственно по сжатым данным.
Интерфейсы совместимости. Помимо собственного двоичного сетевого протокола и HTTP, клиенты могут взаимодействовать с ClickHouse через интерфейсы, совместимые с протоколами MySQL или PostgreSQL на уровне сетевого протокола. Эта функция совместимости полезна для предоставления доступа из проприетарных приложений (например, некоторых инструментов бизнес-аналитики), в которых поставщики ещё не реализовали нативное подключение к ClickHouse.
6 ПРОИЗВОДИТЕЛЬНОСТЬ КАК КЛЮЧЕВАЯ ХАРАКТЕРИСТИКА
В этом разделе рассматриваются встроенные средства анализа производительности и оценивается её уровень на основе реальных и бенчмарк-запросов.
6.1 Встроенные инструменты анализа производительности
Для исследования узких мест производительности в отдельных запросах или фоновых операциях доступен широкий набор инструментов. Пользователи взаимодействуют со всеми инструментами через единый интерфейс, основанный на системных таблицах.
Метрики сервера и запросов. Статистика на уровне сервера, например количество активных партиций, пропускная способность сети и коэффициенты попадания в кэш, дополняется статистикой по отдельным запросам, такой как количество прочитанных блоков или статистика использования индексов. Метрики рассчитываются синхронно (по запросу) или асинхронно с настраиваемой периодичностью.
Профилировщик с выборочным профилированием (sampling profiler). Стэки вызовов потоков сервера могут собираться с помощью профилировщика с выборочным профилированием. Результаты при необходимости могут экспортироваться во внешние инструменты, например визуализаторы флеймграфов.
Интеграция с OpenTelemetry. OpenTelemetry — это открытый стандарт для трассировки строк данных между несколькими системами обработки данных [8]. ClickHouse может генерировать логовые спаны OpenTelemetry с настраиваемой детализацией для всех этапов обработки запросов, а также собирать и анализировать логовые спаны OpenTelemetry из других систем.
Explain-запрос. Как и в других базах данных, запросы SELECT могут предваряться оператором EXPLAIN для детального анализа AST запроса, планов логических и физических операторов и поведения во время выполнения.
6.2 Бенчмарки
Несмотря на критику бенчмаркинга за недостаточную реалистичность [10, 52, 66, [74]](#page-13-24), он тем не менее полезен для выявления сильных и слабых сторон баз данных. Далее мы рассматриваем, как бенчмарки используются для оценки производительности ClickHouse.
6.2.1 Денормализованные таблицы
Запросы фильтрации и агрегации по денормализованным фактовым таблицам исторически представляют собой основной сценарий использования ClickHouse. Мы приводим времена выполнения ClickBench — типичной рабочей нагрузки такого рода, которая имитирует разовые и периодические отчетные запросы, используемые в анализе clickstream и трафика. Бенчмарк состоит из 43 запросов к таблице со 100 миллионами анонимизированных обращений к страницам, полученной от одной из крупнейших в вебе аналитических платформ. Онлайн‑дашборд [17] показывает измерения (время холодного/горячего выполнения, время импорта данных, размер на диске) для более чем 45 коммерческих и исследовательских СУБД по состоянию на июнь 2024 года. Результаты отправляются независимыми участниками на основе общедоступного набора данных и запросов [16]. Запросы тестируют последовательные и индексные пути доступа и регулярно выявляют реляционные операторы, ограниченные по CPU, вводу‑выводу или памяти.
Рисунок 10 показывает суммарные относительные времена холодного и горячего выполнения при последовательном выполнении всех запросов ClickBench в базах данных, часто используемых для аналитики. Измерения были выполнены на одноузловом экземпляре AWS EC2 c6a.4xlarge с 16 vCPU, 32 ГБ RAM и диском 5000 IOPS / 1000 MiB/s. Сопоставимые системы использовались для Redshift (ra3.4xlarge, 12 vCPU, 96 ГБ RAM) и Snowflake (warehouse size S: 2×8 vCPU, 2×16 ГБ RAM). Физический дизайн базы данных настроен лишь минимально: например, мы задаем первичные ключи, но не меняем сжатие отдельных столбцов, не создаем проекции или пропускающие индексы. Мы также очищаем кэш страниц Linux перед каждым запуском холодного запроса, но не настраиваем параметры базы данных или операционной системы. Для каждого запроса самое быстрое время выполнения среди всех баз данных используется как базовый уровень. Относительные времена выполнения запросов для других баз данных рассчитываются как ( + 10)/(_ + 10). Суммарное относительное время выполнения для базы данных — это геометрическое среднее по отношениям для отдельных запросов. Хотя исследовательская СУБД Umbra [54] показывает наилучшее общее время горячего выполнения, ClickHouse превосходит все остальные СУБД производственного уровня по времени выполнения как в горячем, так и в холодном режиме.
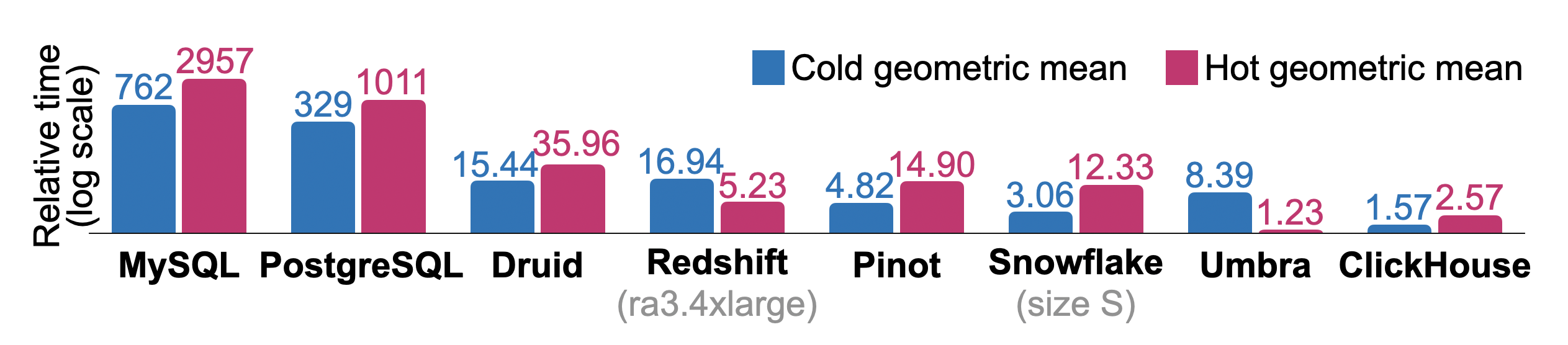
Рисунок 10. Относительные времена холодного и горячего выполнения ClickBench.
Чтобы отслеживать производительность запросов SELECT в более разнообразных нагрузках с течением времени, мы используем комбинацию из четырех бенчмарков под названием VersionsBench [19]. Этот бенчмарк выполняется раз в месяц, когда публикуется новый релиз, чтобы оценить его производительность [20] и выявить изменения в коде, которые потенциально ухудшили производительность. Отдельные бенчмарки включают: 1. ClickBench (описан выше), 2. 15 запросов MgBench [21], 3. 13 запросов к денормализованной фактовой таблице Star Schema Benchmark [57] с 600 миллионами строк, 4. 4 запроса к NYC Taxi Rides с 3,4 миллиарда строк [70].
Рисунок 11 показывает изменение времен выполнения VersionsBench для 77 версий ClickHouse в период с марта 2018 по март 2024 года. Чтобы компенсировать различия в относительном времени выполнения отдельных запросов, мы нормируем времена выполнения, используя геометрическое среднее с отношением к минимальному времени выполнения запроса по всем версиям в качестве веса. Производительность VersionsBench улучшилась в 1,72 раза за последние шесть лет. Даты релизов с долгосрочной поддержкой (LTS) отмечены на оси x. Хотя в некоторые периоды производительность временно ухудшалась, релизы LTS, как правило, имеют сопоставимую или более высокую производительность, чем предыдущая LTS‑версия. Существенное улучшение в августе 2022 года было вызвано техникой постолбцовой оценки фильтров, описанной в разделе 4.4.
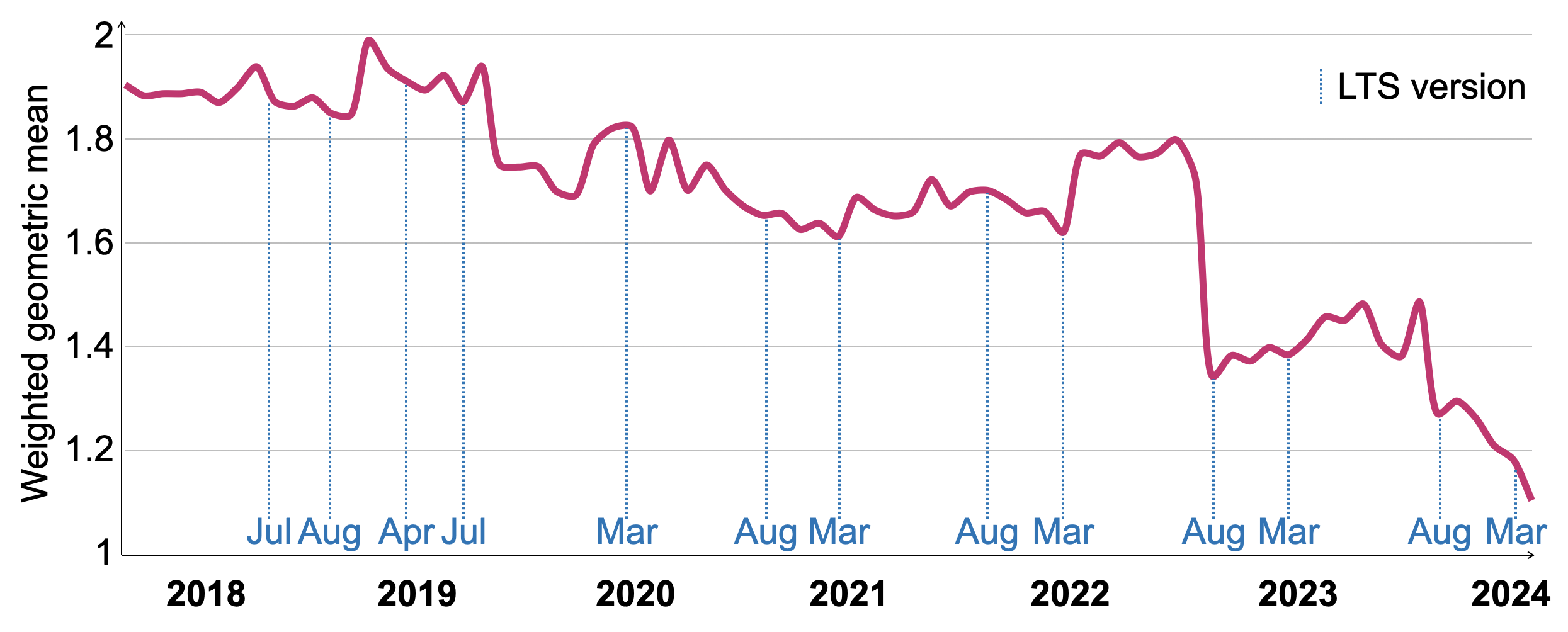
Рисунок 11. Относительные времена горячего выполнения VersionsBench 2018–2024.
6.2.2 Нормализованные таблицы
В классических хранилищах данных информация часто моделируется с использованием схем «звезда» или «снежинка». Мы приводим времена выполнения запросов TPC-H (scale factor 100), но отмечаем, что нормализованные таблицы являются относительно новым сценарием использования для ClickHouse. Рисунок 12 показывает «горячие» времена выполнения запросов TPC-H на основе алгоритма параллельного хеш-соединения, описанного в разделе 4.4. Измерения выполнялись на одновузловом экземпляре AWS EC2 c6i.16xlarge с 64 vCPU, 128 ГБ RAM и диском с 5000 IOPS / 1000 MiB/s. Фиксировался самый быстрый из пяти запусков. Для сравнения мы выполнили те же измерения в системе Snowfake сопоставимого размера (warehouse size L, 8×8 vCPU, 8×16 ГБ RAM). Результаты одиннадцати запросов исключены из таблицы: запросы Q2, Q4, Q13, Q17 и Q20–22 включают коррелированные подзапросы, которые по состоянию на версию ClickHouse v24.6 не поддерживаются. Запросы Q7–Q9 и Q19 зависят от расширенных оптимизаций на уровне плана для соединений, таких как переупорядочивание соединений и проталкивание предикатов соединения (оба по состоянию на ClickHouse v24.6 отсутствуют), чтобы обеспечить приемлемые времена выполнения. Автоматическая декорреляция подзапросов и улучшенная поддержка оптимизатора для соединений планируются к реализации в 2024 году [18]. Из оставшихся 11 запросов 5 (6) запросов выполнялись быстрее в ClickHouse (Snowfake). Поскольку вышеупомянутые оптимизации известны как критически важные для производительности [27], мы ожидаем, что после их реализации времена выполнения этих запросов будут дополнительно улучшены.

Рисунок 12: Время выполнения в «горячем» режиме (в секундах) для запросов TPC-H.
7 СВЯЗАННЫЕ РАБОТЫ
Аналитические базы данных в последние десятилетия вызывают большой академический и коммерческий интерес [1]. Ранние системы, такие как Sybase IQ [48], Teradata [72], Vertica [42] и Greenplum [47], характеризовались дорогими пакетными ETL‑задачами и ограниченной эластичностью из‑за их он‑премисного развертывания. В начале 2010‑х появление облачно‑нативных хранилищ данных и предложений в модели database-as-a-service (DBaaS), таких как Snowfake [22], BigQuery [49] и Redshift [4], радикально снизило стоимость и сложность аналитики для организаций, одновременно обеспечив высокую доступность и автоматическое масштабирование ресурсов. Совсем недавно аналитические ядра выполнения (например, Photon [5] и Velox [62]) стали предлагать унифицированную обработку данных для использования в различных аналитических, потоковых и машинно‑обучающих приложениях.
Наиболее близкими к ClickHouse по целям и принципам проектирования являются базы данных Druid [78] и Pinot [34]. Обе системы нацелены на аналитику в реальном времени с высокой скоростью ингестии данных. Как и в ClickHouse, таблицы разделяются на горизонтальные ^^части^^, называемые сегментами. В то время как ClickHouse непрерывно сливает мелкие ^^части^^ и при необходимости уменьшает объёмы данных с использованием техник из раздела 3.3, ^^части^^ в Druid и Pinot навсегда остаются неизменяемыми. Кроме того, Druid и Pinot требуют специализированных узлов для создания, модификации и поиска по таблицам, тогда как ClickHouse использует для этих задач монолитный исполняемый файл.
Snowfake [22] — популярное проприетарное облачное хранилище данных, основанное на архитектуре с общим диском. Его подход к разбиению таблиц на микропартиции схож с концепцией ^^частей^^ в ClickHouse. Snowfake использует гибридные PAX‑страницы [3] для постоянного хранения, тогда как формат хранения ClickHouse строго колонночный. Snowfake также делает упор на локальное кэширование и отсечение данных с использованием автоматически создаваемых лёгких индексов [31, [51]](#page-13-14) как источника высокой производительности. Аналогично первичным ключам в ClickHouse пользователи могут при необходимости создавать кластеризованные индексы для совместного размещения данных с одинаковыми значениями.
Photon [5] и Velox [62] — это движки выполнения запросов, предназначенные для использования как компоненты в сложных системах управления данными. Обеим системам на вход передаются планы запросов, которые затем выполняются на локальном узле над файлами формата Parquet (Photon) или Arrow (Velox) [46]. ClickHouse может потреблять и генерировать данные в этих универсальных форматах, но для хранения предпочитает собственный файловый формат. Хотя Velox и Photon не оптимизируют план запроса (Velox выполняет базовые оптимизации выражений), они используют техники адаптации во время выполнения, такие как динамическое переключение вычислительных ядер в зависимости от характеристик данных. Аналогичным образом операторы плана в ClickHouse
могут создавать другие операторы во время выполнения, в первую очередь для переключения на внешние операторы агрегации или соединения в зависимости от потребления памяти запросом. В статье о Photon отмечается, что архитектуры с генерацией кода [38, 41, [53]](#page-13-0) сложнее разрабатывать и отлаживать, чем интерпретируемые векторизованные архитектуры [11]. (Экспериментальная) поддержка генерации кода в Velox заключается в сборке и линковке разделяемой библиотеки, полученной из сгенерированного во время выполнения C++‑кода, тогда как ClickHouse взаимодействует напрямую с API компиляции по запросу LLVM.
DuckDB [67] также предназначен для встраивания в хост-процесс, но дополнительно предоставляет оптимизацию запросов и транзакции. Он был спроектирован для OLAP‑запросов, смешанных с эпизодическими OLTP‑запросами. Соответственно, в DuckDB выбран формат хранения DataBlocks [43], который использует легковесные методы сжатия, такие как сохраняющие порядок словари или frame-of-reference [2], чтобы обеспечить хорошую производительность при гибридных нагрузках. Напротив, ClickHouse оптимизирован для сценариев с добавлением данных без их изменения, то есть без обновлений и удалений или при их редком использовании. Блоки сжимаются с помощью тяжеловесных методов, таких как LZ4, при предположении, что пользователи активно применяют отсечение данных (data pruning) для ускорения частых запросов и что затраты на ввод‑вывод значительно превосходят затраты на декомпрессию для оставшихся запросов. DuckDB также предоставляет сериализуемые транзакции, основанные на схеме MVCC системы Hyper [55], тогда как ClickHouse предлагает только изоляцию моментального снимка (snapshot isolation).
8 CONCLUSION AND OUTLOOK
Мы представили архитектуру ClickHouse — открытой высокопроизводительной OLAP-базы данных. Благодаря оптимизированному для записи слою хранения и современному векторизованному движку выполнения запросов в его основе ClickHouse обеспечивает выполнение аналитических запросов в реальном времени по наборам данных петабайтного масштаба с высокой скоростью ингестии данных. Асинхронно объединяя и трансформируя данные в фоновом режиме, ClickHouse эффективно разделяет обслуживание данных и параллельные вставки. Его слой хранения позволяет агрессивно отсекать данные с помощью разрежённых первичных индексов, пропускающих индексов и таблиц-^^projection^^. Мы описали реализацию в ClickHouse операций обновления и удаления, идемпотентных вставок и репликации данных между узлами для обеспечения высокой доступности. Слой обработки запросов оптимизирует запросы, используя множество техник, и параллелизует выполнение по всем ресурсам сервера и ^^cluster^^. Интеграционные движки таблиц и функции обеспечивают удобный способ бесшовного взаимодействия с другими системами управления данными и форматами данных. На основе бенчмарков мы демонстрируем, что ClickHouse — одна из самых быстрых аналитических баз данных на рынке, и показываем существенные улучшения в производительности типичных запросов в реальных развертываниях ClickHouse на протяжении многих лет.
Все возможности и улучшения, запланированные на 2024 год, можно найти в публичной дорожной карте [18]. Среди запланированных улучшений — поддержка пользовательских транзакций, PromQL [69] как альтернативный язык запросов, новый тип данных для полуструктурированных данных (например, JSON), более совершенные оптимизации соединений на уровне плана выполнения, а также реализация облегчённых обновлений, дополняющих облегчённые удаления.
БЛАГОДАРНОСТИ
По состоянию на версию 24.6 запрос SELECT * FROM system.contributors возвращает 1994 человека, которые внесли вклад в развитие ClickHouse. Мы хотели бы поблагодарить всю инженерную команду ClickHouse Inc. и замечательное open-source‑сообщество ClickHouse за их тяжёлый труд и преданность совместному созданию этой базы данных.
Справочные материалы
- [1] Daniel Abadi, Peter Boncz, Stavros Harizopoulos, Stratos Idreaos и Samuel Madden. 2013. Проектирование и реализация современных колоночных систем управления базами данных. https://doi.org/10.1561/9781601987556
- [2] Daniel Abadi, Samuel Madden и Miguel Ferreira. 2006. Integrating Compression and Execution in Column-Oriented Database Systems. В материалах Международной конференции ACM SIGMOD по управлению данными 2006 года (SIGMOD '06). 671–682.https://doi.org/10.1145/1142473.1142548
- [3] Anastassia Ailamaki, David J. DeWitt, Mark D. Hill и Marios Skounakis. 2001. Weaving Relations for Cache Performance. В материалах 27-й Международной конференции по очень большим базам данных (VLDB '01). Morgan Kaufmann Publishers Inc., Сан-Франциско, Калифорния, США, 169–180.
- [4] Nikos Armenatzoglou, Sanuj Basu, Naga Bhanoori, Mengchu Cai, Naresh Chainani, Kiran Chinta, Venkatraman Govindaraju, Todd J. Green, Monish Gupta, Sebastian Hillig, Eric Hotinger, Yan Leshinksy, Jintian Liang, Michael McCreedy, Fabian Nagel, Ippokratis Pandis, Panos Parchas, Rahul Pathak, Orestis Polychroniou, Foyzur Rahman, Gaurav Saxena, Gokul Soundararajan, Sriram Subramanian и Doug Terry. 2022. Amazon Redshift: переосмысление. В материалах 2022 International Conference on Management of Data (Philadelphia, PA, USA) (SIGMOD '22). Association for Computing Machinery, New York, NY, USA, 2205–2217. https://doi.org/10.1145/3514221.3526045
- [5] Alexander Behm, Shoumik Palkar, Utkarsh Agarwal, Timothy Armstrong, David Cashman, Ankur Dave, Todd Greenstein, Shant Hovsepian, Ryan Johnson, Arvind Sai Krishnan, Paul Leventis, Ala Luszczak, Prashanth Menon, Mostafa Mokhtar, Gene Pang, Sameer Paranjpye, Greg Rahn, Bart Samwel, Tom van Bussel, Herman van Hovell, Maryann Xue, Reynold Xin и Matei Zaharia. 2022. Photon: высокопроизводительный движок выполнения запросов для lakehouse-систем («SIGMOD ’22»). Association for Computing Machinery, Нью-Йорк, Нью-Йорк, США, 2326–2339. https://doi.org/10.1145/3514221. 3526054
- [6] Philip A. Bernstein и Nathan Goodman. 1981. Concurrency Control in Distributed Database Systems. ACM Computing Survey 13, 2 (1981), 185–221. https://doi.org/10.1145/356842.356846
- [7] Spyros Blanas, Yinan Li и Jignesh M. Patel. 2011. Design and evaluation of main memory hash join algorithms for multi-core CPUs. В трудах 2011 года конференции ACM SIGMOD International Conference on Management of Data (Athens, Greece) (SIGMOD '11). Association for Computing Machinery, New York, NY, USA, с. 37–48. https://doi.org/10.1145/1989323.1989328
- [8] Daniel Gomez Blanco. 2023. Practical OpenTelemetry. Springer Nature.
- [9] Burton H. Bloom. 1970. Компромиссы между затратами памяти и временем при хеш-кодировании с допустимыми ошибками. Commun. ACM 13, 7 (1970), 422–426. https://doi.org/10.1145/362686. 362692
- [10] Peter Boncz, Thomas Neumann, and Orri Erling. 2014. Анализ TPC-H: скрытые смыслы и уроки, извлечённые из влиятельного бенчмарка. In Performance Characterization and Benchmarking. 61–76. https://doi.org/10.1007/978-3-319- 04936-6_5
- [11] Peter Boncz, Marcin Zukowski и Niels Nes. 2005. MonetDB/X100: Hyper-Pipelining Query Execution. В материалах конференции CIDR.
- [12] Martin Burtscher и Paruj Ratanaworabhan. 2007. Высокопроизводительное сжатие данных с плавающей запятой двойной точности. В сборнике: Data Compression Conference (DCC). 293–302. https://doi.org/10.1109/DCC.2007.44
- [13] Jef Carpenter и Eben Hewitt. 2016. Cassandra: исчерпывающее руководство (2-е издание). O'Reilly Media, Inc.
- [14] Бернадет Шаррон-Бост, Фернандо Педоне и Андре Шипер (ред.). 2010. Репликация: теория и практика. Springer-Verlag.
- [15] chDB. 2024. chDB — встраиваемый OLAP SQL-движок. Дата обращения: 2024-06-20. Доступно по адресу: https://github.com/chdb-io/chdb
- [16] ClickHouse. 2024. ClickBench: бенчмарк для аналитических баз данных. Дата обращения: 2024-06-20. URL: https://github.com/ClickHouse/ClickBench
- [17] ClickHouse. 2024. ClickBench: Comparative Measurements. Дата обращения: 2024-06-20. URL: https://benchmark.clickhouse.com
- [18] ClickHouse. 2024. Дорожная карта ClickHouse 2024 (GitHub). Дата обращения: 20.06.2024. URL: https://github.com/ClickHouse/ClickHouse/issues/58392
- [19] ClickHouse. 2024. Бенчмарк версий ClickHouse. Получено 2024-06-20 по адресу https://github.com/ClickHouse/ClickBench/tree/main/versions
- [20] ClickHouse. 2024. Результаты бенчмарка версий ClickHouse. Дата обращения: 2024-06-20. Доступно по ссылке: https://benchmark.clickhouse.com/versions/
- [21] Andrew Crotty. 2022. MgBench. Дата обращения: 2024-06-20 с https://github.com/ andrewcrotty/mgbench
- [22] Benoit Dageville, Thierry Cruanes, Marcin Zukowski, Vadim Antonov, Artin Avanes, Jon Bock, Jonathan Claybaugh, Daniel Engovatov, Martin Hentschel, Jiansheng Huang, Allison W. Lee, Ashish Motivala, Abdul Q. Munir, Steven Pelley, Peter Povinec, Greg Rahn, Spyridon Triantafyllis и Philipp Unterbrunner. 2016. Snowflake: эластичное хранилище данных. В материалах Международной конференции по управлению данными 2016 года (Сан-Франциско, Калифорния, США) (SIGMOD '16). Association for Computing Machinery, Нью-Йорк, штат Нью-Йорк, США, 215–226. https: //doi.org/10.1145/2882903.2903741
- [23] Patrick Damme, Annett Ungethüm, Juliana Hildebrandt, Dirk Habich, and Wolfgang Lehner. 2019. От всестороннего экспериментального обзора к стоимостной стратегии выбора легковесных алгоритмов сжатия целых чисел. ACM Trans. Database Syst. 44, 3, Article 9 (2019), 46 стр. https://doi.org/10.1145/3323991
- [24] Philippe Dobbelaere и Kyumars Sheykh Esmaili. 2017. Kafka versus RabbitMQ: сравнительное исследование двух эталонных промышленных реализаций паттерна Publish/Subscribe: Industry Paper (DEBS '17). Association for Computing Machinery, Нью-Йорк, штат Нью-Йорк, США, 227–238. https://doi.org/10.1145/3093742.3093908
- [25] Документация LLVM. 2024. Автовекторизация в LLVM. Дата обращения: 20.06.2024. Доступно по адресу https://llvm.org/docs/Vectorizers.html
- [26] Siying Dong, Andrew Kryczka, Yanqin Jin и Michael Stumm. 2021. RocksDB: эволюция приоритетов разработки в хранилище данных типа «ключ–значение», обслуживающем крупномасштабные приложения. ACM Transactions on Storage 17, 4, статья 26 (2021), 32 с. https://doi.org/10.1145/3483840
- [27] Markus Dreseler, Martin Boissier, Tilmann Rabl и Matthias Ufacker. 2020. Количественная оценка узких мест TPC-H и способов их оптимизации. Proc. VLDB Endow. 13, 8 (2020), 1206–1220. https://doi.org/10.14778/3389133.3389138
- [28] Ted Dunning. 2021. t-digest: эффективные оценки распределений. Software Impacts 7 (2021). https://doi.org/10.1016/j.simpa.2020.100049
- [29] Martin Faust, Martin Boissier, Marvin Keller, David Schwalb, Holger Bischof, Katrin Eisenreich, Franz Färber и Hasso Plattner. 2016. Сокращение занимаемого объёма и обеспечение уникальности с помощью хеш-индексов в SAP HANA. In Database and Expert Systems Applications. 137–151. https://doi.org/10.1007/978-3-319-44406- 2_11
- [30] Philippe Flajolet, Eric Fusy, Olivier Gandouet и Frederic Meunier. 2007. HyperLogLog: анализ почти оптимального алгоритма оценки мощности множества. В сб.: AofA: Analysis of Algorithms, DMTCS Proceedings, vol. AH, 2007 Conference on Analysis of Algorithms (AofA 07). Discrete Mathematics and Theoretical Computer Science, 137–156. https://doi.org/10.46298/dmtcs.3545
- [31] Hector Garcia-Molina, Jefrey D. Ullman, and Jennifer Widom. 2009. Системы баз данных. Полный курс (2-е изд.).
- [32] Pawan Goyal, Harrick M. Vin и Haichen Chen. 1996. Start-time fair queueing: алгоритм планирования для сетей коммутации пакетов с интегрированными службами. 26, 4 (1996), 157–168. https://doi.org/10.1145/248157.248171
- [33] Goetz Graefe. 1993. Методы выполнения запросов в больших базах данных. ACM Comput. Surv. 25, 2 (1993), 73–169. https://doi.org/10.1145/152610.152611
- [34] Jean-François Im, Kishore Gopalakrishna, Subbu Subramaniam, Mayank Shrivastava, Adwait Tumbde, Xiaotian Jiang, Jennifer Dai, Seunghyun Lee, Neha Pawar, Jialiang Li и Ravi Aringunram. 2018. Pinot: Realtime OLAP for 530 Million Users. В материалах 2018 International Conference on Management of Data (Houston, TX, USA) (SIGMOD '18). Association for Computing Machinery, New York, NY, USA, 583–594. https://doi.org/10.1145/3183713.3190661
- [35] ISO/IEC 9075-9:2001 2001. Информационные технологии — Язык баз данных — SQL — Часть 9: Управление внешними данными (SQL/MED). Стандарт. Международная организация по стандартизации.
- [36] Paras Jain, Peter Kraft, Conor Power, Tathagata Das, Ion Stoica и Matei Zaharia. 2023. «Анализ и сравнение систем хранения Lakehouse». CIDR.
- [37] Project Jupyter. 2024. Jupyter Notebooks. Дата обращения: 2024-06-20. Доступно по адресу https: //jupyter.org/
- [38] Timo Kersten, Viktor Leis, Alfons Kemper, Thomas Neumann, Andrew Pavlo и Peter Boncz. 2018. «Всё, что вы всегда хотели знать о скомпилированных и векторизованных запросах, но боялись спросить». Proc. VLDB Endow. 11, 13 (sep 2018), 2209–2222. https://doi.org/10.14778/3275366.3284966
- [39] Changkyu Kim, Jatin Chhugani, Nadathur Satish, Eric Sedlar, Anthony D. Nguyen, Tim Kaldewey, Victor W. Lee, Scott A. Brandt и Pradeep Dubey. 2010. FAST: быстрый архитектурно-ориентированный поиск по дереву на современных CPU и GPU. В материалах 2010 ACM SIGMOD International Conference on Management of Data (Indianapolis, Indiana, USA) (SIGMOD '10). Association for Computing Machinery, New York, NY, USA, 339–350. https://doi.org/10.1145/1807167.1807206
- [40] Donald E. Knuth. 1973. Искусство программирования, том 3: Сортировка и поиск. Addison-Wesley.
- [41] André Kohn, Viktor Leis и Thomas Neumann. 2018. Адаптивное выполнение скомпилированных запросов. В материалах 34-й Международной конференции IEEE по инженерии данных (ICDE), 2018. С. 197–208. https://doi.org/10.1109/ICDE.2018.00027
- [42] Andrew Lamb, Matt Fuller, Ramakrishna Varadarajan, Nga Tran, Ben Vandiver, Lyric Doshi и Chuck Bear. 2012. The Vertica Analytic Database: C-Store 7 Years Later. Proc. VLDB Endow. 5, 12 (авг. 2012), 1790–1801. https://doi.org/10. 14778/2367502.2367518
- [43] Harald Lang, Tobias Mühlbauer, Florian Funke, Peter A. Boncz, Thomas Neumann и Alfons Kemper. 2016. Data Blocks: гибридная обработка OLTP и OLAP на сжатом хранилище с применением векторизации и компиляции. В материалах 2016 International Conference on Management of Data (San Francisco, California, USA) (SIGMOD '16). Association for Computing Machinery, New York, NY, USA, 311–326. https://doi.org/10.1145/2882903.2882925
- [44] Viktor Leis, Peter Boncz, Alfons Kemper и Thomas Neumann. 2014. Morsel-driven parallelism: a NUMA-aware query evaluation framework for the manycore age. In Proceedings of the 2014 ACM SIGMOD International Conference on Management of Data (Snowbird, Utah, USA) (SIGMOD '14). Association for Computing Machinery, New York, NY, USA, 743–754. https://doi.org/10.1145/2588555. 2610507
- [45] Viktor Leis, Alfons Kemper, and Thomas Neumann. 2013. Адаптивное radix-дерево: ARTful-индексирование для баз данных в оперативной памяти. В 29-й Международной конференции IEEE по инженерии данных (ICDE), 2013. 38–49. https://doi.org/10.1109/ICDE. 2013.6544812
- [46] Chunwei Liu, Anna Pavlenko, Matteo Interlandi и Brandon Haynes. 2023. Подробный обзор распространённых открытых форматов данных для аналитических СУБД. 16, 11 (июль 2023), 3044–3056. https://doi.org/10.14778/3611479.3611507
- [47] Zhenghua Lyu, Huan Hubert Zhang, Gang Xiong, Gang Guo, Haozhou Wang, Jinbao Chen, Asim Praveen, Yu Yang, Xiaoming Gao, Alexandra Wang, Wen Lin, Ashwin Agrawal, Junfeng Yang, Hao Wu, Xiaoliang Li, Feng Guo, Jiang Wu, Jesse Zhang и Venkatesh Raghavan. 2021. Greenplum: гибридная база данных для транзакционных и аналитических рабочих нагрузок (SIGMOD '21). Association for Computing Machinery, Нью-Йорк, Нью-Йорк, США, 2530–2542. https: //doi.org/10.1145/3448016.3457562
- [48] Roger MacNicol и Blaine French. 2004. Sybase IQ Multiplex — система, разработанная для аналитики. В сборнике трудов Тридцатой Международной конференции по очень большим базам данных — том 30 (Торонто, Канада) (VLDB '04). VLDB Endowment, 1227–1230.
- [49] Sergey Melnik, Andrey Gubarev, Jing Jing Long, Geofrey Romer, Shiva Shivakumar, Matt Tolton, Theo Vassilakis, Hossein Ahmadi, Dan Delorey, Slava Min, Mosha Pasumansky и Jef Shute. 2020. Dremel: A Decade of Interactive SQL Analysis at Web Scale. Proc. VLDB Endow. 13, 12 (август 2020 г.), 3461–3472. https://doi.org/10.14778/3415478.3415568
- [50] Microsoft. 2024. Kusto Query Language. Дата обращения: 2024-06-20 с https: //github.com/microsoft/Kusto-Query-Language
- [51] Guido Moerkotte. 1998. Небольшие материализованные агрегаты: легковесная индексная структура для хранилищ данных. В материалах 24-й Международной конференции по базам данных очень большого объёма (VLDB '98). 476–487.
- [52] Jalal Mostafa, Sara Wehbi, Suren Chilingaryan и Andreas Kopmann. 2022. SciTS: бенчмарк для баз данных временных рядов в научных экспериментах и промышленном Интернете вещей. В трудах 34-й Международной конференции по управлению научными и статистическими базами данных (SSDBM '22). Статья 12. https: //doi.org/10.1145/3538712.3538723
- [53] Thomas Neumann. 2011. Эффективная компиляция эффективных планов запросов для современного оборудования. Proc. VLDB Endow. 4, 9 (июн 2011), 539–550. https://doi.org/10.14778/ 2002938.2002940
- [54] Thomas Neumann и Michael J. Freitag. 2020. Umbra: дисковая система с производительностью уровня in-memory. В: 10-я Conference on Innovative Data Systems Research (CIDR 2020), Amsterdam, The Netherlands, 12–15 января 2020 г., электронный сборник. www.cidrdb.org. http://cidrdb.org/cidr2020/papers/p29-neumanncidr20.pdf
- [55] Thomas Neumann, Tobias Mühlbauer и Alfons Kemper. 2015. Fast Serializable Multi-Version Concurrency Control for Main-Memory Database Systems. В материалах 2015 ACM SIGMOD International Conference on Management of Data (Melbourne, Victoria, Australia) (SIGMOD '15). Association for Computing Machinery, New York, NY, USA, 677–689. https://doi.org/10.1145/2723372. 2749436
- [56] LevelDB на GitHub. 2024. LevelDB. Дата обращения: 2024-06-20. https://github. com/google/leveldb
- [57] Patrick O'Neil, Elizabeth O'Neil, Xuedong Chen и Stephen Revilak. 2009. Бенчмарк Star Schema и индексирование расширенной таблицы фактов. В сборнике «Оценка производительности и бенчмаркинг». Springer Berlin Heidelberg, 237–252. https: //doi.org/10.1007/978-3-642-10424-4_17
- [58] Patrick E. O'Neil, Edward Y. C. Cheng, Dieter Gawlick, and Elizabeth J. O'Neil. 1996. Лог-структурированное дерево слияния (LSM-tree). Acta Informatica 33 (1996), 351–385. https://doi.org/10.1007/s002360050048
- [59] Diego Ongaro и John Ousterhout. 2014. В поисках понятного алгоритма консенсуса. В материалах конференции 2014 USENIX Annual Technical Conference (USENIX ATC'14). 305–320. https://doi.org/doi/10. 5555/2643634.2643666
- [60] Patrick O'Neil, Edward Cheng, Dieter Gawlick и Elizabeth O'Neil. 1996. Лог-структурированное дерево слияний (Log-Structured Merge-Tree, LSM-Tree). Acta Inf. 33, 4 (1996), 351–385. https: //doi.org/10.1007/s002360050048
- [61] Pandas. 2024. Pandas DataFrames. Дата обращения: 20.06.2024. URL: https://pandas. pydata.org/
- [62] Pedro Pedreira, Orri Erling, Masha Basmanova, Kevin Wilfong, Laith Sakka, Krishna Pai, Wei He и Biswapesh Chattopadhyay. 2022. Velox: унифицированный исполнительный движок Meta. Proc. VLDB Endow. 15, 12 (авг. 2022), 3372–3384. https: //doi.org/10.14778/3554821.3554829
- [63] Tuomas Pelkonen, Scott Franklin, Justin Teller, Paul Cavallaro, Qi Huang, Justin Meza и Kaushik Veeraraghavan. 2015. Gorilla: быстрая, масштабируемая база данных временных рядов в памяти. Proceedings of the VLDB Endowment 8, 12 (2015), 1816–1827. https://doi.org/10.14778/2824032.2824078
- [64] Orestis Polychroniou, Arun Raghavan и Kenneth A. Ross. 2015. Переосмысление векторизации SIMD для баз данных в оперативной памяти. В материалах Международной конференции ACM SIGMOD по управлению данными 2015 года (SIGMOD '15). 1493–1508. https://doi.org/10.1145/2723372.2747645
- [65] PostgreSQL. 2024. PostgreSQL - Foreign Data Wrappers. Дата обращения: 2024-06-20. https://wiki.postgresql.org/wiki/Foreign_data_wrappers
- [66] Mark Raasveldt, Pedro Holanda, Tim Gubner и Hannes Mühleisen. 2018. Fair Benchmarking Considered Difficult: Common Pitfalls in Database Performance Testing. В материалах Workshop on Testing Database Systems (Houston, TX, USA) (DBTest'18). Статья 2, 6 страниц. https://doi.org/10.1145/3209950.3209955
- [67] Mark Raasveldt и Hannes Mühleisen. 2019. DuckDB: встраиваемая аналитическая СУБД (SIGMOD '19). Association for Computing Machinery, Нью-Йорк, Нью-Йорк, США, 1981–1984. https://doi.org/10.1145/3299869.3320212
- [68] Jun Rao и Kenneth A. Ross. 1999. Cache Conscious Indexing for Decision-Support in Main Memory. Труды 25-й Международной конференции по очень большим базам данных (VLDB '99), Сан-Франциско, Калифорния, США, с. 78–89.
- [69] Navin C. Sabharwal и Piyush Kant Pandey. 2020. Работа с языком запросов Prometheus (PromQL). В книге Monitoring Microservices and Containerized Applications. https://doi.org/10.1007/978-1-4842-6216-0_5
- [70] Todd W. Schneider. 2022. Данные о такси и заказных перевозках в Нью-Йорке. Дата обращения: 2024-06-20. https://github.com/toddwschneider/nyc-taxi-data
- [71] Mike Stonebraker, Daniel J. Abadi, Adam Batkin, Xuedong Chen, Mitch Cherniack, Miguel Ferreira, Edmond Lau, Amerson Lin, Sam Madden, Elizabeth O'Neil, Pat O'Neil, Alex Rasin, Nga Tran и Stan Zdonik. 2005. C-Store: колоночная СУБД. В сборнике трудов 31-й международной конференции по очень большим базам данных (VLDB '05). 553–564.
- [72] Teradata. 2024. Teradata Database. Дата обращения: 2024-06-20. https://www. teradata.com/resources/datasheets/teradata-database
- [73] Frederik Transier. 2010. Algorithms and Data Structures for In-Memory Text Search Engines. Диссертация на соискание ученой степени доктора философии (PhD). https://doi.org/10.5445/IR/1000015824
- [74] Adrian Vogelsgesang, Michael Haubenschild, Jan Finis, Alfons Kemper, Viktor Leis, Tobias Muehlbauer, Thomas Neumann и Manuel Then. 2018. Get Real: How Benchmarks Fail to Represent the Real World. В сборнике трудов Workshop on Testing Database Systems (Houston, TX, USA) (DBTest'18). Статья 1, 6 стр. https://doi.org/10.1145/3209950.3209952
- [75] Сайт LZ4. 2024. LZ4. Дата обращения: 2024-06-20, URL: https://lz4.org/
- [76] Веб-сайт PRQL. 2024. PRQL. URL: https://prql-lang.org (дата обращения: 2024-06-20). [77] Till Westmann, Donald Kossmann, Sven Helmer, and Guido Moerkotte. 2000. Реализация и производительность сжатых баз данных. SIGMOD Rec.
- 29, 3 (сентябрь 2000), 55–67. https://doi.org/10.1145/362084.362137 [78] Fangjin Yang, Eric Tschetter, Xavier Léauté, Nelson Ray, Gian Merlino и Deep Ganguli. 2014. Druid: оперативное аналитическое хранилище данных в реальном времени. В сборнике трудов Международной конференции ACM SIGMOD 2014 по управлению данными (Snowbird, Utah, USA) (SIGMOD '14). Association for Computing Machinery, New York, NY, USA, 157–168. https://doi.org/10.1145/2588555.2595631
- [79] Tianqi Zheng, Zhibin Zhang и Xueqi Cheng. 2020. SAHA: адаптивная хеш-таблица для строк в аналитических базах данных. Applied Sciences 10, 6 (2020). https: //doi.org/10.3390/app10061915
- [80] Jingren Zhou и Kenneth A. Ross. 2002. Implementing Database Operations Using SIMD Instructions. В сборнике трудов Международной конференции ACM SIGMOD по управлению данными 2002 года (SIGMOD '02). 145–156. https://doi.org/10. 1145/564691.564709
- [81] Marcin Zukowski, Sandor Heman, Niels Nes и Peter Boncz. 2006. Super-Scalar RAM-CPU Cache Compression. В трудах 22-й Международной конференции по инженерии данных (ICDE '06). 59. https://doi.org/10.1109/ICDE. 2006.150
