Практическое введение в первичные индексы ClickHouse
Введение
В этом руководстве мы подробно разберём индексацию в ClickHouse. Мы наглядно покажем и детально обсудим:
- чем индексация в ClickHouse отличается от традиционных систем управления реляционными базами данных
- как ClickHouse строит и использует разрежённый первичный индекс таблицы
- какие существуют лучшие практики индексации в ClickHouse
При желании вы можете выполнить все приведённые в этом руководстве SQL-операторы и запросы к ClickHouse самостоятельно на своём компьютере. Инструкции по установке ClickHouse и началу работы см. в разделе Quick Start.
В этом руководстве основное внимание уделяется разрежённым первичным индексам ClickHouse.
Сведения о вторичных индексах пропуска данных в ClickHouse см. в разделе Руководство.
Набор данных
На протяжении всего руководства мы будем использовать пример анонимизированного набора данных о веб‑трафике.
- Мы будем использовать подмножество из 8,87 миллиона строк (событий) из этого набора данных.
- Несжатый объем данных составляет 8,87 миллиона событий и около 700 МБ. При хранении в ClickHouse они сжимаются примерно до 200 МБ.
- В нашем подмножестве каждая строка содержит три столбца, которые обозначают интернет‑пользователя (столбец
UserID), кликнувшего по URL (столбецURL) в определенный момент времени (столбецEventTime).
Имея эти три столбца, мы уже можем формулировать типичные запросы веб‑аналитики, например:
- «Каковы топ‑10 URL‑адресов, по которым данный пользователь кликал чаще всего?»
- «Каковы топ‑10 пользователей, которые чаще всего кликали по указанному URL?»
- «В какие моменты времени (например, дни недели) пользователь чаще всего кликает по определенному URL?»
Тестовая машина
Все показатели времени выполнения, приведённые в этом документе, основаны на локальном запуске ClickHouse 22.2.1 на MacBook Pro с чипом Apple M1 Pro и 16 ГБ оперативной памяти.
Полное сканирование таблицы
Чтобы увидеть, как выполняется запрос по нашему набору данных без первичного ключа, создадим таблицу (с движком таблиц MergeTree), выполнив следующий SQL DDL‑оператор:
Затем вставьте подмножество набора данных hits в таблицу с помощью следующего оператора SQL INSERT. Для этого используется табличная функция URL, чтобы загрузить подмножество полного набора данных, размещённого удалённо на clickhouse.com:
Ответ:
Вывод клиента ClickHouse показывает, что приведённый выше запрос вставил в таблицу 8,87 миллиона строк.
Наконец, чтобы упростить дальнейшее обсуждение в этом руководстве и сделать диаграммы и результаты воспроизводимыми, мы оптимизируем таблицу с помощью ключевого слова FINAL:
В целом после загрузки данных в таблицу обычно не требуется и не рекомендуется сразу её оптимизировать. Почему в данном примере это необходимо, станет понятно ниже.
Теперь выполним наш первый запрос веб-аналитики. Следующий запрос вычисляет топ-10 URL-адресов, по которым чаще всего кликает интернет-пользователь с UserID 749927693:
Ответ:
Вывод клиента ClickHouse показывает, что ClickHouse выполнил полное сканирование таблицы! Каждая из 8,87 миллиона строк нашей таблицы была построчно передана в ClickHouse. Такой подход не масштабируется.
Чтобы сделать этот процесс (значительно) более эффективным и (намного) быстрее, нам нужно использовать таблицу с подходящим первичным ключом. Это позволит ClickHouse автоматически (на основе столбцов первичного ключа) создать разреженный первичный индекс, который затем можно будет использовать для существенного ускорения выполнения нашего примерного запроса.
Проектирование индексов в ClickHouse
Проектирование индекса для колоссальных объёмов данных
В традиционных реляционных системах управления базами данных первичный индекс содержит по одной записи на каждую строку таблицы. В нашем наборе данных это привело бы к тому, что первичный индекс содержал бы 8,87 миллиона записей. Такой индекс позволяет быстро находить конкретные строки, что обеспечивает высокую эффективность запросов на поиск и точечных обновлений. Поиск записи в структуре данных B(+)-Tree имеет среднюю временную сложность O(log n); точнее, log_b n = log_2 n / log_2 b, где b — коэффициент ветвления B(+)-Tree, а n — количество индексируемых строк. Поскольку b обычно находится в диапазоне от нескольких сотен до нескольких тысяч, B(+)-Trees являются очень неглубокими структурами, и для поиска записей требуется мало дисковых обращений. Для 8,87 миллиона строк и коэффициента ветвления 1000 в среднем требуется 2,3 дисковых обращения. Эта возможность даётся не бесплатно: возникают дополнительные накладные расходы по диску и памяти, увеличиваются затраты на вставку при добавлении новых строк в таблицу и записей в индекс, а иногда требуется перебалансировка B-Tree.
Учитывая сложности, связанные с индексами на основе B-Tree, движки таблиц в ClickHouse используют иной подход. Семейство движков MergeTree Engine Family в ClickHouse спроектировано и оптимизировано для работы с огромными объёмами данных. Эти таблицы предназначены для приёма миллионов вставок строк в секунду и хранения очень больших объёмов данных (сотни петабайт). Данные быстро записываются в таблицу по частям, при этом в фоновом режиме применяются правила для слияния этих частей. В ClickHouse каждая часть имеет свой собственный первичный индекс. Когда части сливаются, сливаются и их первичные индексы. На очень больших масштабах, для которых спроектирован ClickHouse, крайне важно эффективно использовать диск и память. Поэтому вместо индексирования каждой строки первичный индекс для части содержит одну запись индекса (называемую «mark») на группу строк (называемую «granule») — эта техника называется разрежённый индекс.
Разрежённая индексация возможна благодаря тому, что ClickHouse хранит строки части на диске в порядке следования по столбцам первичного ключа. Вместо прямого поиска отдельных строк (как в индексе на основе B-Tree) разрежённый первичный индекс позволяет быстро (посредством двоичного поиска по записям индекса) определять группы строк, которые потенциально могут соответствовать запросу. Найденные группы потенциально подходящих строк (гранулы) затем параллельно передаются в движок ClickHouse для поиска совпадений. Такое устройство индекса позволяет сделать первичный индекс небольшим (он может и должен полностью помещаться в основной памяти), при этом заметно ускоряя выполнение запросов, особенно диапазонных запросов, типичных для аналитических сценариев.
Ниже подробно показано, как ClickHouse строит и использует свой разрежённый первичный индекс. Позже в статье мы обсудим лучшие практики выбора, удаления и упорядочивания столбцов таблицы, используемых для построения индекса (столбцов первичного ключа).
Таблица с первичным ключом
Создайте таблицу с составным первичным ключом по столбцам UserID и URL:
Подробности оператора DDL
Чтобы упростить последующее изложение в этом руководстве, а также сделать диаграммы и результаты воспроизводимыми, оператор DDL:
Задает составной ключ сортировки для таблицы с помощью предложения
ORDER BY.Явно контролирует, сколько записей будет содержать первичный индекс, с помощью настроек:
index_granularity: явно установлено в значение по умолчанию 8192. Это означает, что для каждой группы из 8192 строк первичный индекс будет иметь одну запись. Например, если таблица содержит 16384 строки, индекс будет иметь две записи.index_granularity_bytes: установлено в 0, чтобы отключить адаптивную гранулярность индекса. Адаптивная гранулярность индекса означает, что ClickHouse автоматически создает одну запись индекса для группы из n строк, если выполняется одно из следующих условий:Если
nменьше 8192 и совокупный размер данных строк для этихnстрок больше или равен 10 МБ (значение по умолчанию дляindex_granularity_bytes).Если совокупный размер данных строк для
nстрок меньше 10 МБ, ноnравно 8192.
compress_primary_key: установлено в 0, чтобы отключить сжатие первичного индекса. Это позволит нам при необходимости позже изучить его содержимое.
Первичный ключ в операторе DDL выше приводит к созданию первичного индекса на основе двух указанных ключевых столбцов.
Затем вставьте данные:
Ответ будет выглядеть примерно так:
И оптимизируйте таблицу:
Мы можем использовать следующий запрос для получения метаданных о таблице:
Ответ:
Вывод клиента ClickHouse показывает:
- Данные таблицы хранятся в широком формате в отдельном каталоге на диске, то есть для каждого столбца таблицы в этом каталоге создаётся один файл с данными (и один файл с метками).
- Таблица содержит 8,87 млн строк.
- Несжатый объём данных всех строк составляет 733,28 MB.
- Сжатый на диске объём данных всех строк составляет 206,94 MB.
- Таблица имеет первичный индекс с 1083 записями (называемыми «метками»), размер индекса — 96,93 KB.
- В сумме файлы данных и меток таблицы, а также файл первичного индекса занимают на диске 207,07 MB.
Данные хранятся на диске в порядке, определяемом столбцами первичного ключа
Наша таблица, которую мы создали выше, имеет
- составной первичный ключ
(UserID, URL)и - составной ключ сортировки
(UserID, URL, EventTime).
-
Если бы мы указали только ключ сортировки, то первичный ключ был бы неявно определён как совпадающий с ключом сортировки.
-
Чтобы эффективно использовать память, мы явно задали первичный ключ, который содержит только те столбцы, по которым выполняется фильтрация в наших запросах. Первичный индекс, основанный на первичном ключе, полностью загружается в оперативную память.
-
Для согласованности диаграмм в этом руководстве и для максимизации коэффициента сжатия мы определили отдельный ключ сортировки, который включает все столбцы нашей таблицы (если в столбце однородные данные располагаются рядом друг с другом, например за счёт сортировки, то эти данные сжимаются лучше).
-
Первичный ключ должен быть префиксом ключа сортировки, если оба они заданы.
Вставленные строки хранятся на диске в лексикографическом порядке по возрастанию по столбцам первичного ключа (и дополнительному столбцу EventTime из ключа сортировки).
ClickHouse позволяет вставлять несколько строк с одинаковыми значениями столбцов первичного ключа. В этом случае (см. строки 1 и 2 на диаграмме ниже) окончательный порядок определяется заданным ключом сортировки и, следовательно, значением столбца EventTime.
ClickHouse — это колоночная система управления базами данных. Как показано на диаграмме ниже,
- в представлении на диске используется один файл данных (*.bin) на каждый столбец таблицы, в котором все значения этого столбца хранятся в сжатом формате, и
- 8,87 миллиона строк хранятся на диске в лексикографическом порядке по возрастанию по столбцам первичного ключа (и дополнительным столбцам ключа сортировки), то есть в данном случае
- сначала по
UserID, - затем по
URL, - и, наконец, по
EventTime:
- сначала по
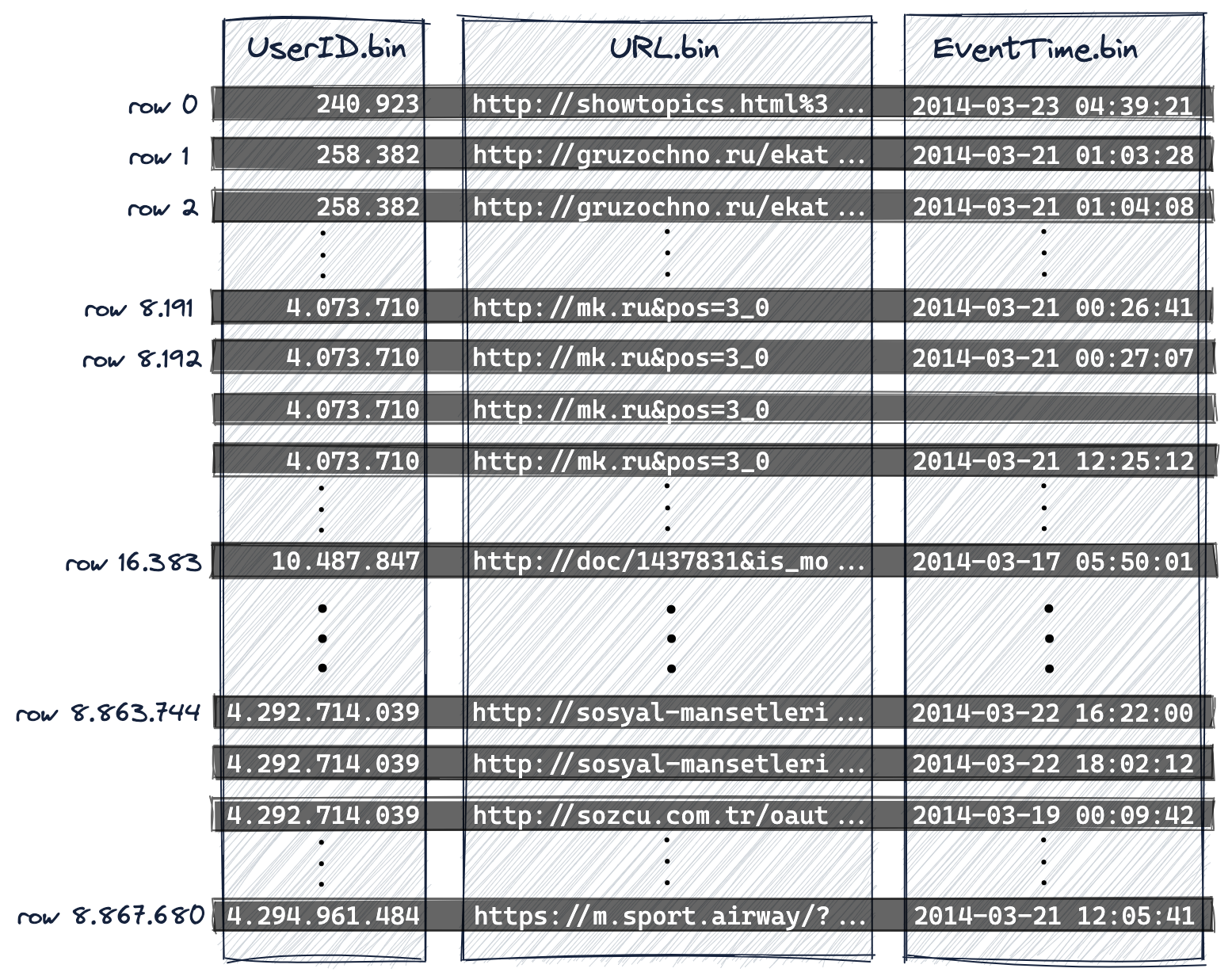
UserID.bin, URL.bin и EventTime.bin — это файлы данных на диске, в которых хранятся значения столбцов UserID, URL и EventTime.
-
Поскольку первичный ключ задаёт лексикографический порядок строк на диске, таблица может иметь только один первичный ключ.
-
Мы нумеруем строки, начиная с 0, чтобы соответствовать внутренней схеме нумерации строк в ClickHouse, которая также используется в сообщениях журнала.
Данные организованы в гранулы для параллельной обработки
Для обработки данные значения столбцов таблицы логически делятся на гранулы. Гранула — это наименьший неделимый набор данных, который в потоковом режиме передаётся в ClickHouse для обработки. Это означает, что вместо чтения отдельных строк ClickHouse всегда читает (потоково и параллельно) целую группу строк (гранулу).
Значения столбцов физически не хранятся внутри гранул: гранулы — это только логическая организация значений столбцов для обработки запросов.
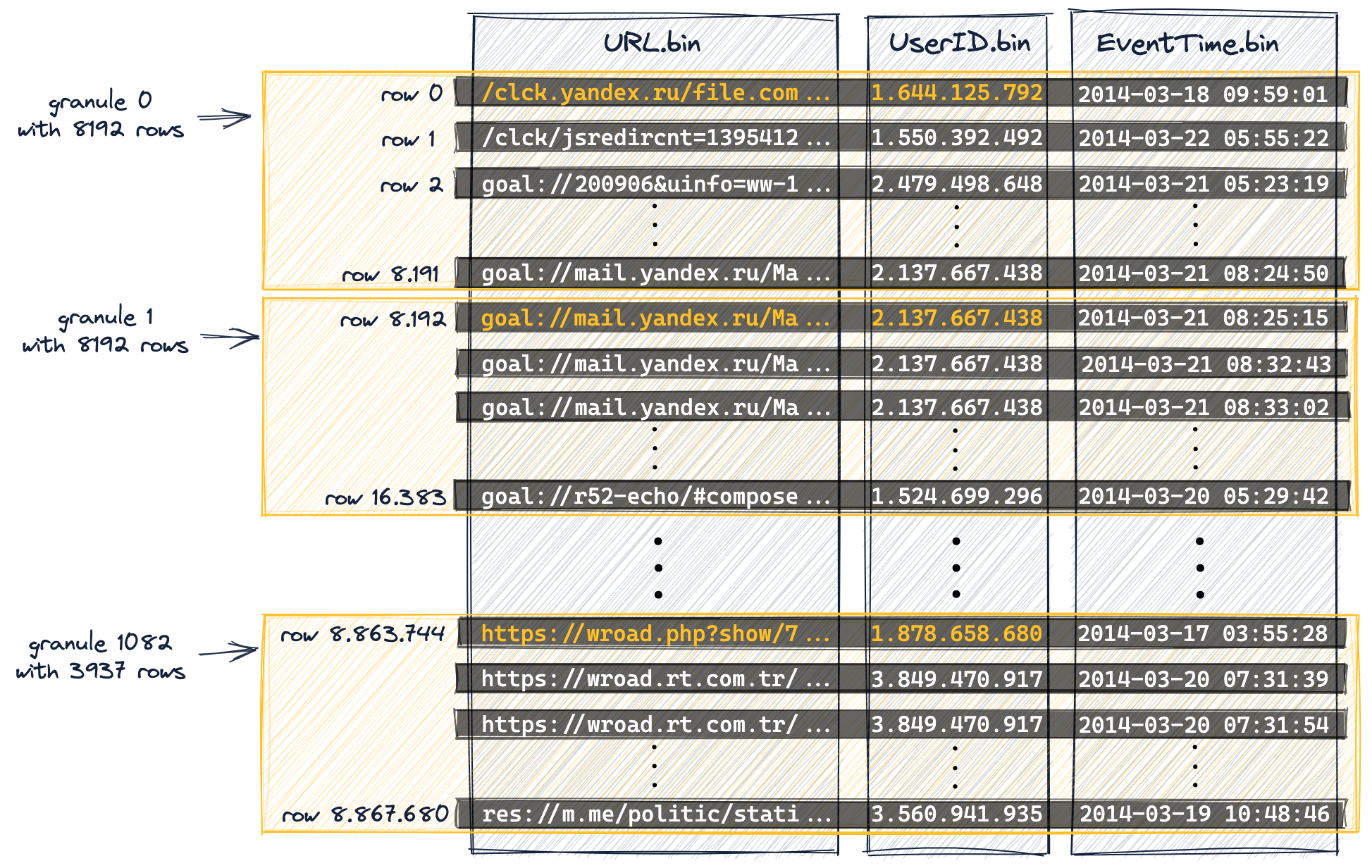
На следующей схеме показано, как (значения столбцов) 8,87 миллиона строк нашей таблицы
организованы в 1083 гранулы в результате того, что в DDL-выражении таблицы задана настройка index_granularity (установленная в значение по умолчанию 8192).
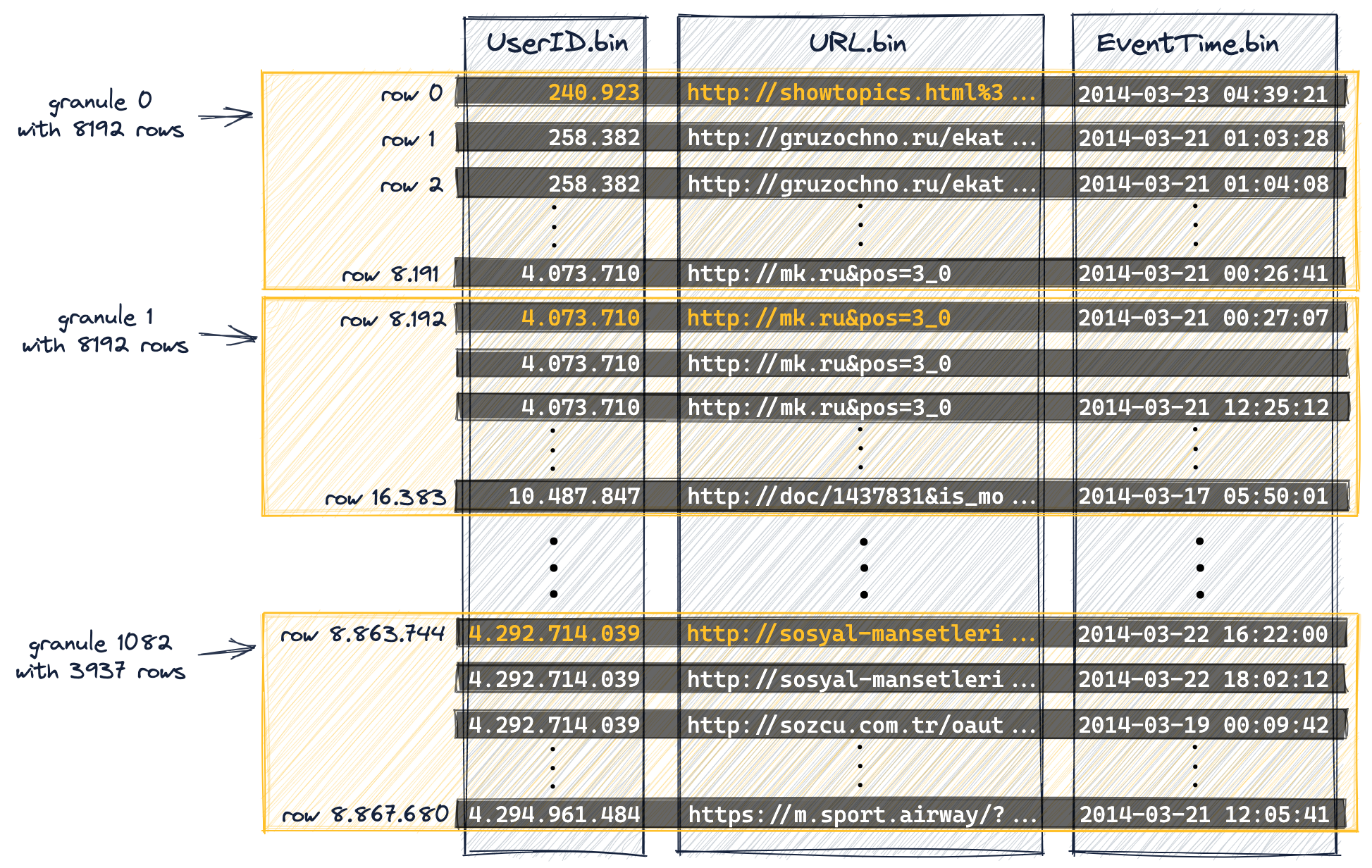
Первые (в физическом порядке на диске) 8192 строки (их значения столбцов) логически относятся к грануле 0, затем следующие 8192 строки (их значения столбцов) относятся к грануле 1 и так далее.
-
Последняя гранула (гранула 1082) «содержит» меньше чем 8192 строки.
-
В начале этого руководства, в разделе «DDL Statement Details», мы упоминали, что отключили адаптивную зернистость индекса (для упрощения обсуждений в этом руководстве, а также для того, чтобы сделать схемы и результаты воспроизводимыми).
Поэтому все гранулы (кроме последней) в нашей таблице-примере имеют одинаковый размер.
-
Для таблиц с адаптивной зернистостью индекса (зернистость индекса является адаптивной по умолчанию) размер некоторых гранул может быть меньше 8192 строк в зависимости от объёма данных в строках.
-
Мы отметили некоторые значения столбцов из наших столбцов первичного ключа (
UserID,URL) оранжевым цветом. Эти отмеченные оранжевым значения столбцов являются значениями столбцов первичного ключа первой строки каждой гранулы. Как мы увидим ниже, эти отмеченные оранжевым значения столбцов будут записями в первичном индексе таблицы. -
Мы нумеруем гранулы, начиная с 0, чтобы соответствовать внутренней схеме нумерации ClickHouse, которая также используется в сообщениях журнала.
У первичного индекса по одной записи на каждую гранулу
Первичный индекс создается на основе гранул, показанных на диаграмме выше. Этот индекс представляет собой несжатый файл с плоским массивом (primary.idx), содержащим так называемые числовые метки индекса, начинающиеся с 0.
Диаграмма ниже показывает, что индекс хранит значения столбцов первичного ключа (значения, выделенные оранжевым цветом на диаграмме выше) для первой строки каждой гранулы. Иными словами: первичный индекс хранит значения столбцов первичного ключа из каждой 8192-й строки таблицы (основанных на физическом порядке строк, определяемом столбцами первичного ключа). Например:
- первая запись индекса («mark 0» на диаграмме ниже) хранит значения столбцов ключа первой строки гранулы 0 с диаграммы выше,
- вторая запись индекса («mark 1» на диаграмме ниже) хранит значения столбцов ключа первой строки гранулы 1 с диаграммы выше и так далее.
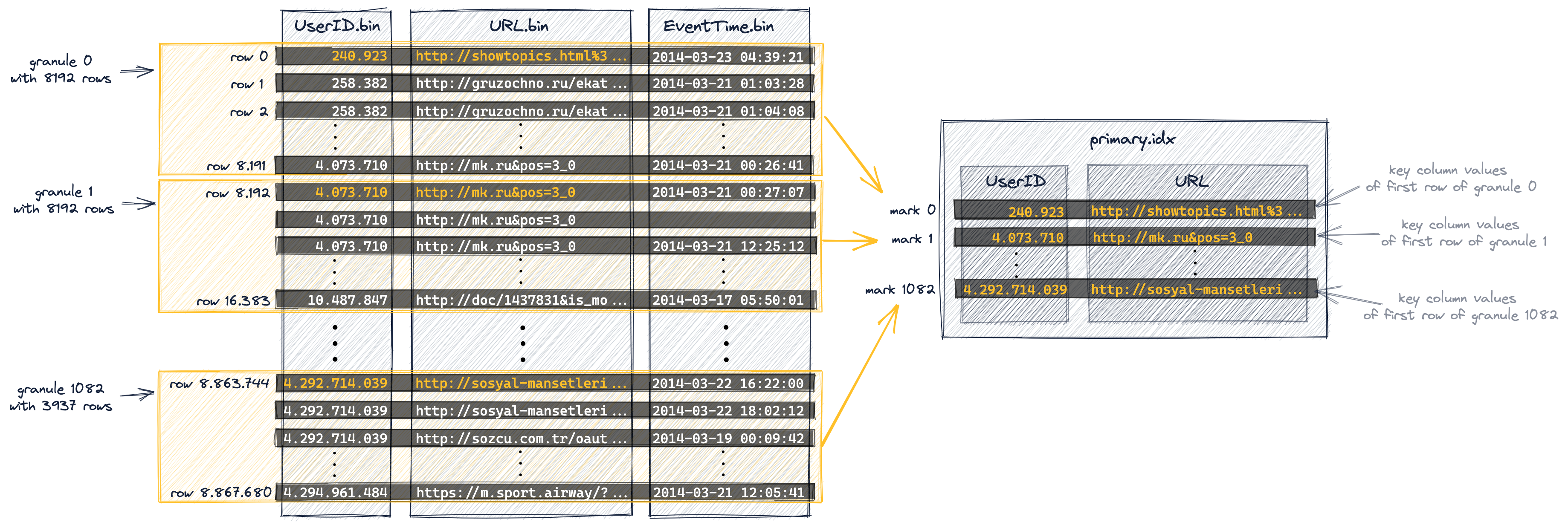
Всего индекс содержит 1083 записи для нашей таблицы с 8,87 миллионами строк и 1083 гранулами:

-
Для таблиц с adaptive index granularity в первичном индексе также хранится одна «финальная» дополнительная метка, которая фиксирует значения столбцов первичного ключа последней строки таблицы, но, поскольку мы отключили adaptive index granularity (чтобы упростить обсуждение в этом руководстве, а также сделать диаграммы и результаты воспроизводимыми), индекс нашей таблицы-примера не включает эту финальную метку.
-
Файл первичного индекса полностью загружается в оперативную память. Если файл больше, чем доступный объем свободной памяти, ClickHouse выдаст ошибку.
Изучение содержимого первичного индекса
В самостоятельно управляемом кластере ClickHouse мы можем использовать табличную функцию file, чтобы изучить содержимое первичного индекса нашей примерной таблицы.
Для этого нам сначала нужно скопировать файл первичного индекса в user_files_path одного из узлов запущенного кластера:
- Шаг 1: Получить путь к части, которая содержит файл первичного индекса
- Шаг 2: Получить user_files_path Значение user_files_path по умолчанию в Linux —
- Шаг 3: Скопировать файл первичного индекса в user_files_path
SELECT path FROM system.parts WHERE table = 'hits_UserID_URL' AND active = 1на тестовой машине возвращает /Users/tomschreiber/Clickhouse/store/85f/85f4ee68-6e28-4f08-98b1-7d8affa1d88c/all_1_9_4.
/var/lib/clickhouse/user_files/и в Linux вы можете проверить, изменялось ли оно: $ grep user_files_path /etc/clickhouse-server/config.xml
На тестовой машине путь — /Users/tomschreiber/Clickhouse/user_files/
cp /Users/tomschreiber/Clickhouse/store/85f/85f4ee68-6e28-4f08-98b1-7d8affa1d88c/all_1_9_4/primary.idx /Users/tomschreiber/Clickhouse/user_files/primary-hits_UserID_URL.idx
Теперь мы можем изучить содержимое первичного индекса через SQL:
- Получить количество элементов
- Получить первые две метки индекса
- Получить последнюю метку индекса
SELECT count( )<br/>FROM file('primary-hits_UserID_URL.idx', 'RowBinary', 'UserID UInt32, URL String');
возвращает 1083SELECT UserID, URL<br/>FROM file('primary-hits_UserID_URL.idx', 'RowBinary', 'UserID UInt32, URL String')<br/>LIMIT 0, 2;возвращает
240923, http://showtopics.html%3...<br/> 4073710, http://mk.ru&pos=3_0
SELECT UserID, URL FROM file('primary-hits_UserID_URL.idx', 'RowBinary', 'UserID UInt32, URL String')<br/>LIMIT 1082, 1;
возвращает
4292714039 │ http://sosyal-mansetleri...Это в точности соответствует нашей диаграмме содержимого первичного индекса для нашей примерной таблицы:
Записи первичного ключа называются метками индекса, потому что каждая запись индекса помечает начало конкретного диапазона данных. В частности, для примерной таблицы:
-
Метки индекса по UserID:
Сохраняемые значения
UserIDв первичном индексе отсортированы по возрастанию.
Поэтому «метка 1» на диаграмме выше указывает, что значенияUserIDвсех строк таблицы в грануле 1 и во всех последующих гранулах гарантированно больше либо равны 4.073.710.
Как мы увидим позже, этот глобальный порядок позволяет ClickHouse использовать алгоритм бинарного поиска по меткам индекса первого столбца ключа, когда запрос фильтрует по первому столбцу первичного ключа.
-
Марки индекса для URL:
Сопоставимая кардинальность (cardinality) столбцов первичного ключа
UserIDиURLозначает, что марки индекса для всех столбцов ключа, начиная со второго, в общем случае лишь указывают диапазон данных до тех пор, пока значение предыдущего столбца ключа остаётся одинаковым для всех строк таблицы хотя бы в пределах текущего гранула.
Например, поскольку значения UserID в марке 0 и марке 1 на диаграмме выше различаются, ClickHouse не может предположить, что все значения URL всех строк таблицы в грануле 0 больше или равны'http://showtopics.html%3...'. Однако если бы значения UserID в марке 0 и марке 1 на диаграмме выше были одинаковыми (что означало бы, что значение UserID остаётся одинаковым для всех строк таблицы в пределах гранула 0), ClickHouse мог бы предположить, что все значения URL всех строк таблицы в грануле 0 больше или равны'http://showtopics.html%3...'.Последствия этого для производительности выполнения запросов мы рассмотрим подробнее позже.
Первичный индекс используется для отбора гранул
Теперь мы можем выполнять запросы с использованием первичного индекса.
Следующий запрос определяет топ-10 URL-адресов, по которым чаще всего кликали, для UserID 749927693.
Ответ:
Вывод клиента ClickHouse теперь показывает, что вместо полного сканирования таблицы в ClickHouse было обработано всего 8,19 тысячи строк.
Если включено трассировочное логирование, то в журнале сервера ClickHouse видно, что выполнялся двоичный поиск по 1083 меткам индекса UserID, чтобы определить гранулы, которые потенциально могут содержать строки, где значение столбца UserID равно 749927693. Это требует 19 шагов при средней временной сложности O(log2 n):
Мы видим в приведённом выше trace log, что только одна метка из 1083 имеющихся меток удовлетворила запросу.
Подробности trace log
Была идентифицирована метка 176 ('found left boundary mark' — включительно, 'found right boundary mark' — исключительно), и поэтому все 8192 строки из гранулы 176 (которая начинается со строки 1.441.792 — мы увидим это позже в этом руководстве) затем передаются в ClickHouse для поиска конкретных строк со значением столбца UserID, равным 749927693.
Мы также можем воспроизвести это, используя оператор EXPLAIN в нашем примере запроса:
Ответ будет выглядеть так:
Вывод клиента показывает, что одна из 1083 гранул была выбрана как потенциально содержащая строки со значением столбца UserID, равным 749927693.
Когда запрос фильтрует по столбцу, который является частью составного ключа и первым столбцом этого ключа, ClickHouse выполняет алгоритм двоичного поиска по индексным меткам этого ключевого столбца.
Как было сказано выше, ClickHouse использует разреженный первичный индекс для быстрой (через двоичный поиск) выборки гранул, которые могут содержать строки, удовлетворяющие запросу.
Это первая стадия (выбор гранул) выполнения запроса в ClickHouse.
На второй стадии (чтение данных) ClickHouse находит выбранные гранулы, чтобы передать все их строки в движок ClickHouse и найти строки, которые действительно удовлетворяют запросу.
В следующем разделе мы более подробно рассмотрим эту вторую стадию.
Файлы меток используются для определения местоположения гранул
На следующей диаграмме показана часть файла первичного индекса для нашей таблицы.

Как обсуждалось выше, с помощью двоичного поиска по 1083 меткам UserID в индексе была найдена метка 176. Соответствующая ей гранула 176, таким образом, может потенциально содержать строки со значением столбца UserID 749.927.693.
Подробности выбора гранулы
На диаграмме выше показано, что метка 176 — это первая запись индекса, для которой одновременно выполняются условия: минимальное значение UserID ассоциированной гранулы 176 меньше 749.927.693, а минимальное значение UserID гранулы 177 для следующей метки (метка 177) больше этого значения. Поэтому только соответствующая гранула 176 для метки 176 может потенциально содержать строки со значением столбца UserID 749.927.693.
Чтобы подтвердить (или опровергнуть), что в грануле 176 есть строки со значением столбца UserID 749.927.693, все 8192 строки, принадлежащие этой грануле, должны быть считаны в ClickHouse.
Для этого ClickHouse необходимо знать физическое местоположение гранулы 176.
В ClickHouse физические местоположения всех гранул для нашей таблицы хранятся в файлах меток. Аналогично файлам данных, для каждого столбца таблицы существует свой файл меток.
Следующая диаграмма показывает три файла меток UserID.mrk, URL.mrk и EventTime.mrk, которые хранят физические местоположения гранул для столбцов UserID, URL и EventTime таблицы.
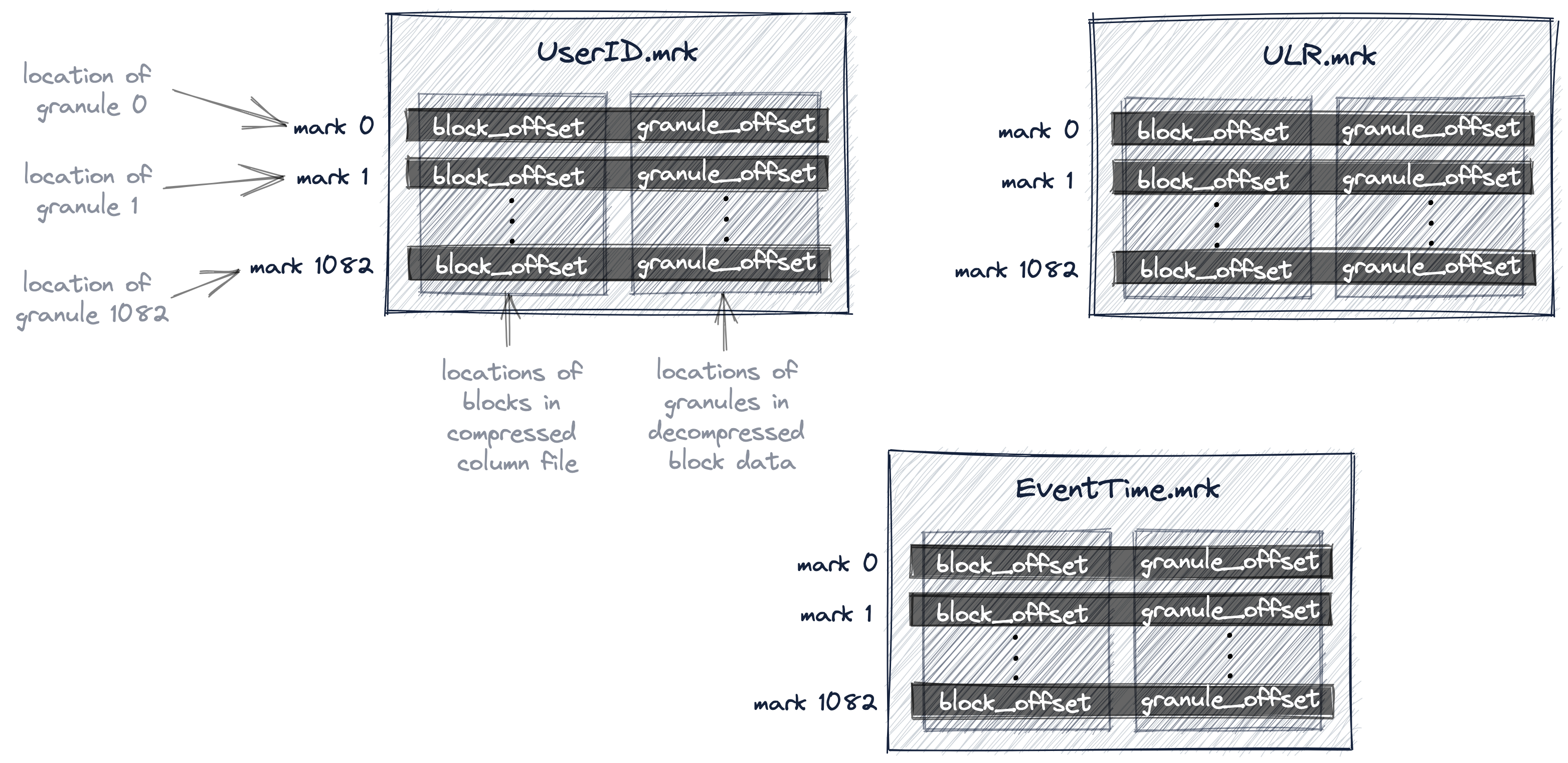
Мы обсудили, что первичный индекс — это плоский несжатый файловый массив (primary.idx), содержащий метки индекса, которые нумеруются начиная с 0.
Аналогично, файл меток — это также плоский несжатый файловый массив (*.mrk), содержащий метки, которые нумеруются начиная с 0.
После того как ClickHouse идентифицировал и выбрал метку индекса для гранулы, которая потенциально может содержать строки, удовлетворяющие запросу, в файлах меток может быть выполнен позиционный поиск по массиву для получения физических местоположений гранулы.
Каждая запись файла меток для конкретного столбца хранит два местоположения в виде смещений:
-
Первое смещение (
block_offsetна диаграмме выше) указывает на блок в сжатом столбцовом файле данных, который содержит сжатую версию выбранной гранулы. Этот сжатый блок потенциально содержит несколько сжатых гранул. Найденный сжатый блок файла при чтении распаковывается в основную память. -
Второе смещение (
granule_offsetна диаграмме выше) из файла меток определяет местоположение гранулы внутри распакованных данных блока.
Все 8192 строки, принадлежащие найденной распакованной грануле, затем передаются в ClickHouse для дальнейшей обработки.
- Для таблиц с широким форматом и без адаптивной зернистости индекса ClickHouse использует файлы меток
.mrk, как показано выше, которые содержат записи с двумя адресами длиной по 8 байт на запись. Эти записи являются физическими местоположениями гранул, все из которых имеют одинаковый размер.
Зернистость индекса по умолчанию является адаптивной (см. настройки), но для нашей примерной таблицы мы отключили адаптивную зернистость индекса (с целью упростить обсуждения в этом руководстве, а также сделать диаграммы и результаты воспроизводимыми). Наша таблица использует широкий формат, потому что размер данных больше, чем min_bytes_for_wide_part (по умолчанию 10 МБ для кластеров с самостоятельным управлением).
-
Для таблиц с широким форматом и с адаптивной зернистостью индекса ClickHouse использует файлы меток
.mrk2, которые содержат записи, аналогичные файлам меток.mrk, но с дополнительным третьим значением на запись: количеством строк гранулы, с которой связана текущая запись. -
Для таблиц с компактным форматом ClickHouse использует файлы меток
.mrk3.
Почему первичный индекс не содержит напрямую физические позиции гранул, соответствующие меткам индекса?
Потому что на очень большом масштабе, под который спроектирован ClickHouse, крайне важно эффективно использовать диск и оперативную память.
Файл первичного индекса должен помещаться в оперативную память.
В нашем примере запроса ClickHouse использовал первичный индекс и выбрал одну гранулу, которая может содержать строки, удовлетворяющие нашему запросу. Только для этой одной гранулы ClickHouse затем нужны физические позиции, чтобы потоково считывать соответствующие строки для дальнейшей обработки.
Кроме того, эта информация о смещениях нужна только для столбцов UserID и URL.
Информация о смещениях не нужна для столбцов, которые не используются в запросе, например EventTime.
Для нашего примера запроса ClickHouse нужны только два смещения физических позиций для гранулы 176 в файле данных UserID (UserID.bin) и два смещения физических позиций для гранулы 176 в файле данных URL (URL.bin).
Опосредование, обеспечиваемое файлами меток, позволяет избежать хранения непосредственно в первичном индексе записей о физических позициях всех 1083 гранул для всех трёх столбцов, тем самым избегая наличия в оперативной памяти лишних (потенциально неиспользуемых) данных.
Следующая диаграмма и текст ниже иллюстрируют, как в нашем примере запроса ClickHouse находит гранулу 176 в файле данных UserID.bin.
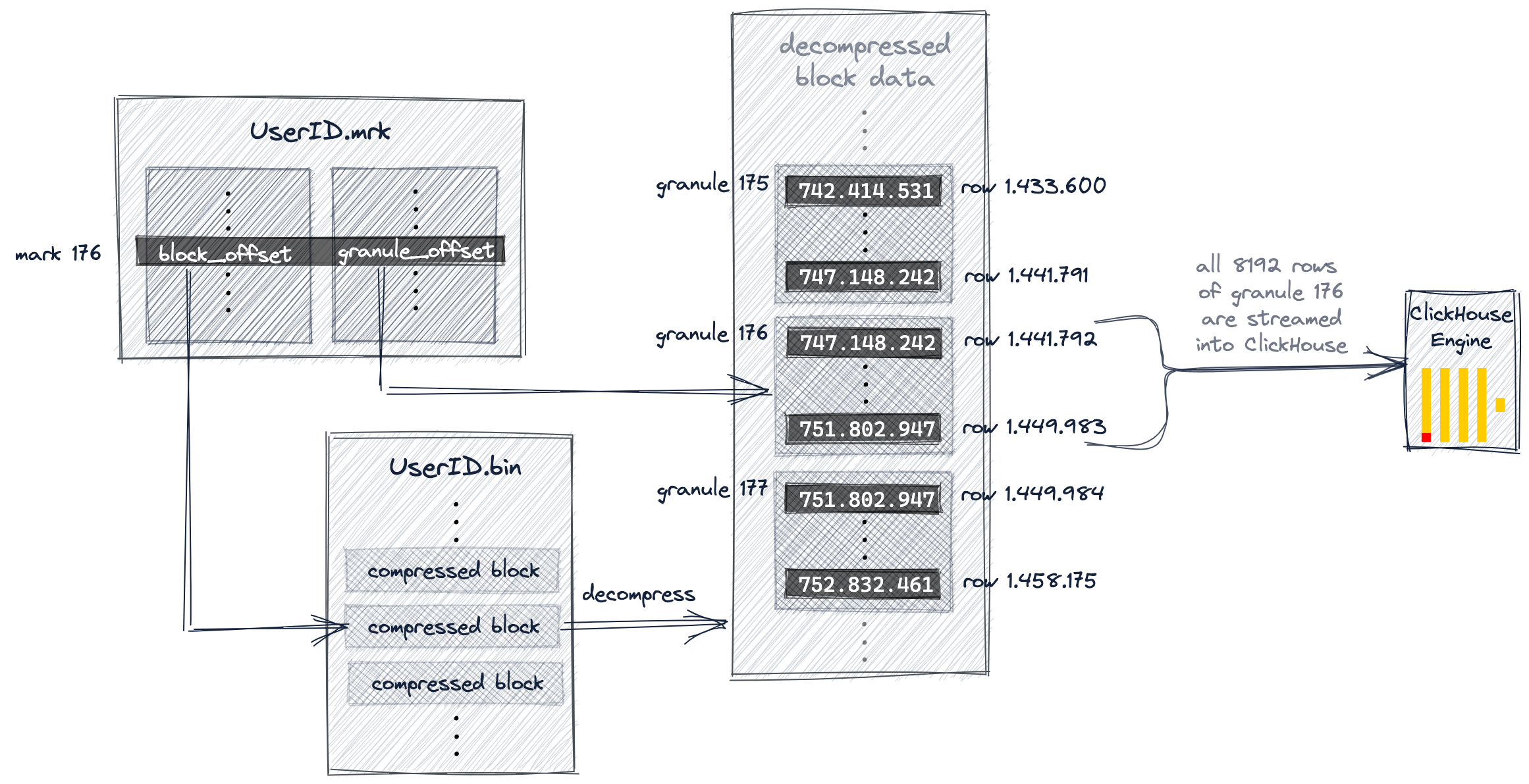
Ранее в этом руководстве мы обсуждали, что ClickHouse выбрал метку первичного индекса 176 и, следовательно, гранулу 176 как потенциально содержащую строки, соответствующие нашему запросу.
Теперь ClickHouse использует выбранный номер метки (176) из индекса для позиционного поиска по массиву в файле меток UserID.mrk, чтобы получить два смещения для поиска гранулы 176.
Как показано, первое смещение указывает на сжатый блок файла внутри файла данных UserID.bin, который, в свою очередь, содержит сжатую версию гранулы 176.
После того как найденный файловый блок распакован в оперативную память, второе смещение из файла меток может быть использовано для поиска гранулы 176 в несжатых данных.
ClickHouse нужно найти (и потоково считать все значения) гранулу 176 как из файла данных UserID.bin, так и из файла данных URL.bin, чтобы выполнить наш пример запроса (топ 10 URL-адресов с наибольшим числом кликов для интернет-пользователя с UserID 749.927.693).
Диаграмма выше показывает, как ClickHouse находит гранулу для файла данных UserID.bin.
Параллельно ClickHouse делает то же самое для гранулы 176 в файле данных URL.bin. Эти две соответствующие гранулы выравниваются и потоково передаются в движок ClickHouse для дальнейшей обработки, то есть агрегирования и подсчёта значений URL по группам для всех строк, где UserID равен 749.927.693, прежде чем, в конечном итоге, вывести 10 наибольших групп URL в порядке убывания счётчика.
Использование нескольких первичных индексов
Вторичные ключевые столбцы могут быть (не)эффективными
Когда запрос фильтрует данные по столбцу, который является частью составного ключа и при этом является первым ключевым столбцом, ClickHouse выполняет алгоритм бинарного поиска по индексным меткам этого ключевого столбца.
Но что происходит, когда запрос фильтрует данные по столбцу, который входит в составной ключ, но не является первым ключевым столбцом?
Мы рассматриваем сценарий, когда запрос явно не фильтрует данные по первому ключевому столбцу, а по вторичному ключевому столбцу.
Когда запрос фильтрует данные одновременно по первому ключевому столбцу и по любому другому ключевому столбцу (столбцам) после первого, ClickHouse выполняет бинарный поиск по индексным меткам первого ключевого столбца.
Используем запрос, который вычисляет топ-10 пользователей, наиболее часто переходивших по URL "http://public_search":
Вывод клиента показывает, что ClickHouse почти выполнил полное сканирование таблицы, несмотря на то, что столбец URL является частью составного первичного ключа! ClickHouse прочитал 8,81 миллиона строк из 8,87 миллиона строк таблицы.
Если параметр trace_logging включён, то в журнале сервера ClickHouse видно, что был использован универсальный алгоритм исключающего поиска по 1083 меткам индекса по URL, чтобы определить те гранулы, которые потенциально могут содержать строки со значением столбца URL "http://public_search":
Мы видим в приведённом выше примере трассировочного лога, что 1076 (по меткам) из 1083 гранул были выбраны как потенциально содержащие строки с совпадающим значением URL.
В результате 8,81 миллиона строк передаются на обработку движку ClickHouse (параллельно с использованием 10 потоков) для идентификации строк, которые фактически содержат значение URL "http://public_search".
Однако, как мы увидим далее, только 39 гранул из выбранных 1076 гранул на самом деле содержат совпадающие строки.
Хотя первичный индекс, основанный на составном первичном ключе (UserID, URL), был очень полезен для ускорения запросов, фильтрующих строки по конкретному значению UserID, этот индекс не оказывает существенной помощи в ускорении запроса, который фильтрует строки по конкретному значению URL.
Причина в том, что столбец URL не является первым столбцом ключа, и поэтому ClickHouse использует общий алгоритм исключающего поиска (вместо бинарного поиска) по меткам индекса столбца URL, и эффективность этого алгоритма зависит от разницы кардинальностей между столбцом URL и предшествующим ему столбцом ключа UserID.
Чтобы проиллюстрировать это, мы приведём некоторые детали того, как работает общий алгоритм исключающего поиска.
Универсальный алгоритм поиска с исключением
Ниже показано, как работает универсальный алгоритм поиска с исключением в ClickHouse, когда гранулы выбираются по вторичной колонке, где предшествующая ключевая колонка имеет низкую (или высокую) кардинальность.
В качестве примера для обоих случаев будем считать, что у нас есть:
- запрос, который ищет строки со значением URL = "W3";
- абстрактная версия нашей таблицы hits с упрощёнными значениями для UserID и URL;
- тот же составной первичный ключ (UserID, URL) для индекса. Это означает, что строки сначала упорядочены по значениям UserID. Строки с одинаковым значением UserID затем упорядочены по URL;
- размер гранулы равен двум, т.е. каждая гранула содержит две строки.
Мы выделили значения ключевого столбца для первых строк таблицы для каждой гранулы оранжевым цветом на диаграммах ниже.
Предшествующая ключевая колонка имеет низкую кардинальность
Предположим, что UserID имеет низкую кардинальность. В этом случае вероятно, что одно и то же значение UserID распределено по нескольким строкам таблицы и гранулам, а следовательно, и по нескольким меткам индекса. Для меток индекса с одинаковым UserID значения URL для этих меток отсортированы по возрастанию (потому что строки таблицы упорядочены сначала по UserID, а затем по URL). Это позволяет эффективно выполнять фильтрацию, как описано ниже:
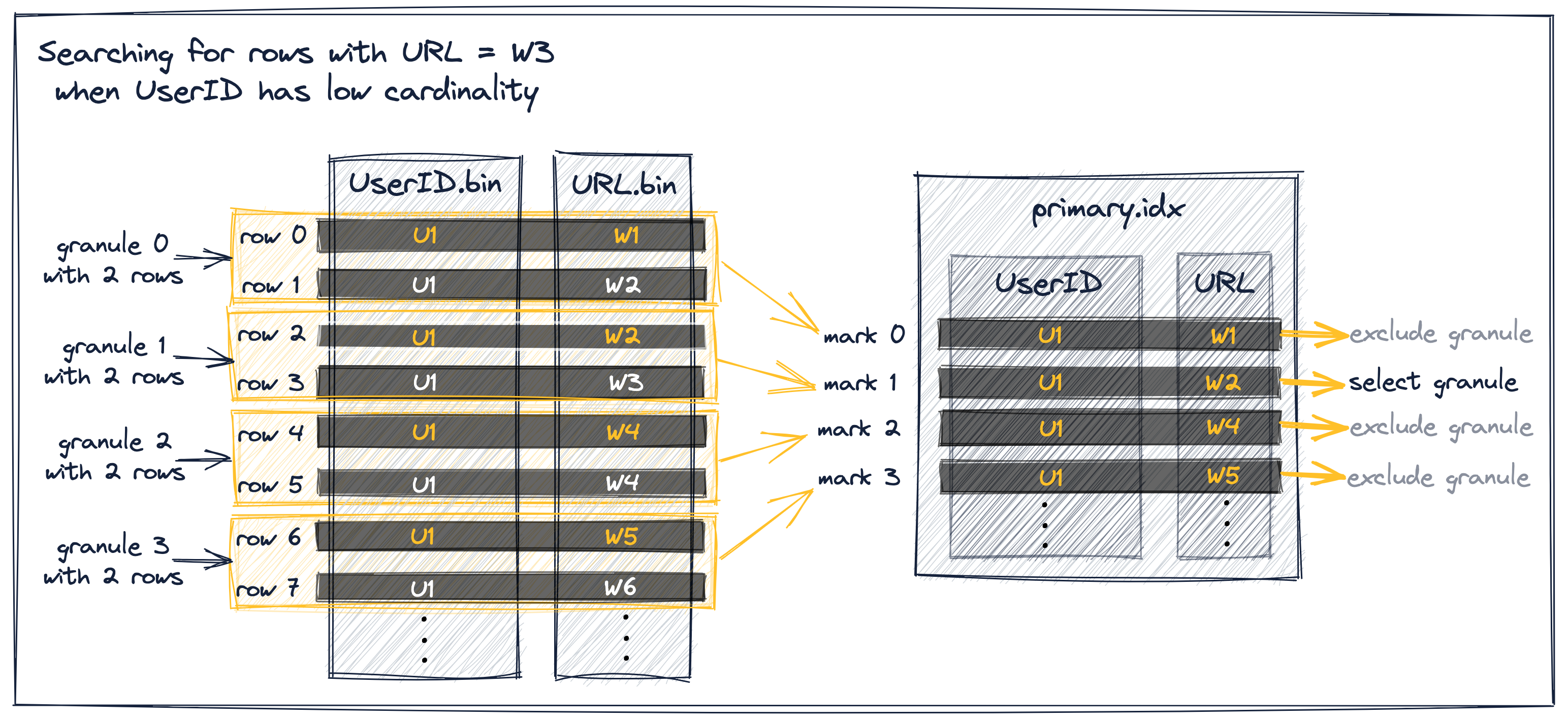
Существует три различных сценария процесса выбора гранул для наших абстрактных примерных данных на диаграмме выше:
-
Метка индекса 0, для которой значение URL меньше W3 и для которой значение URL непосредственно следующей метки индекса также меньше W3, может быть исключена, потому что метки 0 и 1 имеют одинаковое значение UserID. Обратите внимание, что это предусловие исключения гарантирует, что гранула 0 полностью состоит из значений UserID U1, так что ClickHouse может предположить, что максимальное значение URL в грануле 0 также меньше W3 и исключить гранулу.
-
Метка индекса 1, для которой значение URL меньше (или равно) W3 и для которой значение URL непосредственно следующей метки индекса больше (или равно) W3, выбирается, потому что это означает, что гранула 1 потенциально может содержать строки с URL W3.
-
Метки индекса 2 и 3, для которых значение URL больше W3, могут быть исключены, поскольку метки первичного индекса хранят значения ключевого столбца для первой строки таблицы в каждой грануле, а строки таблицы на диске отсортированы по значениям ключевого столбца, следовательно, гранулы 2 и 3 не могут содержать значение URL W3.
Предшествующая ключевая колонка имеет высокую кардинальность
Когда UserID имеет высокую кардинальность, маловероятно, что одно и то же значение UserID распределено по нескольким строкам таблицы и гранулам. Это означает, что значения URL для меток индекса не являются монотонно возрастающими:
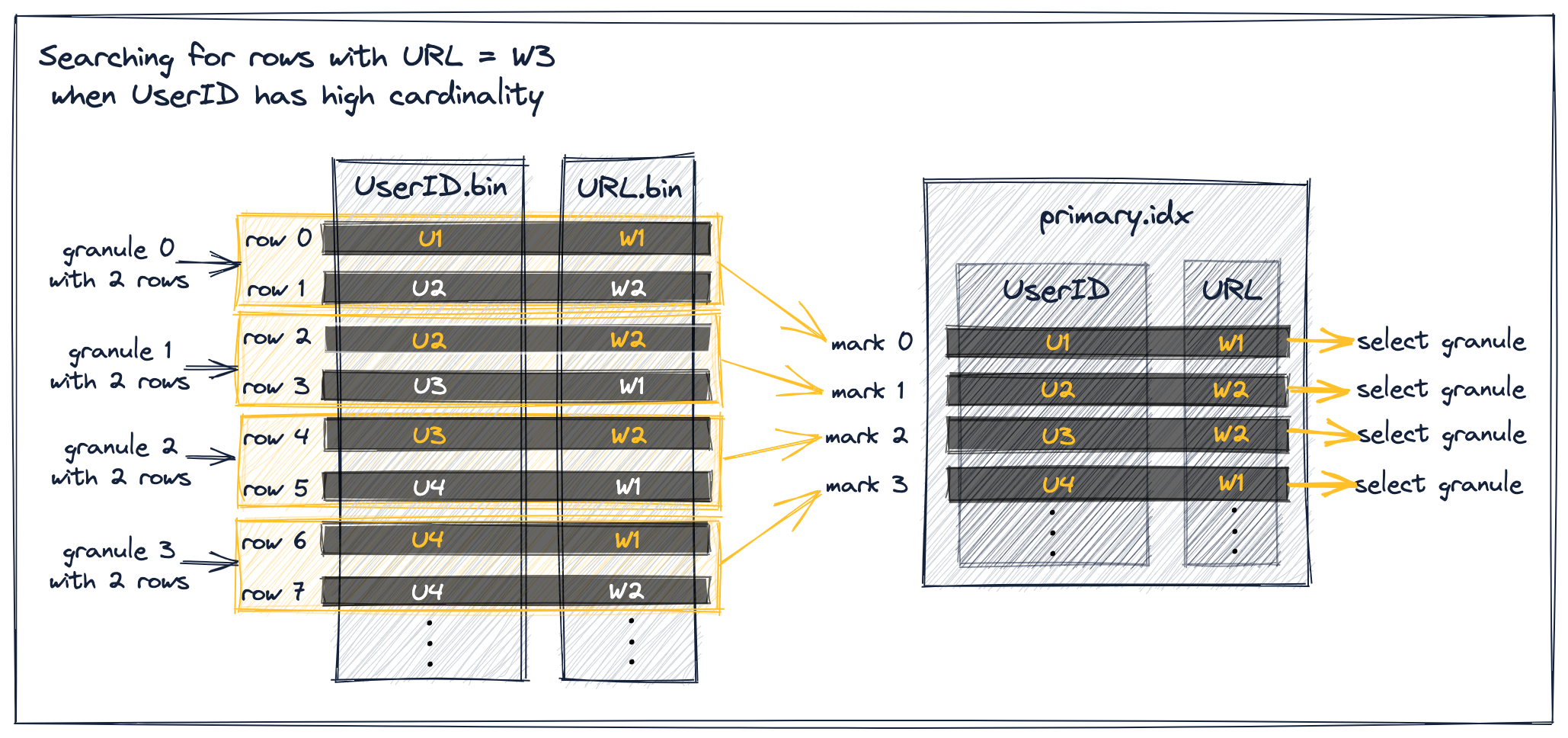
Как мы видим на диаграмме выше, все показанные метки, значения URL которых меньше W3, выбираются для потоковой передачи строк их соответствующих гранул в движок ClickHouse.
Это происходит потому, что, хотя все метки индекса на диаграмме подпадают под сценарий 1, описанный выше, они не удовлетворяют указанному предусловию исключения, согласно которому непосредственно следующая метка индекса должна иметь то же значение UserID, что и текущая метка, и, следовательно, не могут быть исключены.
Например, рассмотрим метку индекса 0, для которой значение URL меньше W3 и для которой значение URL непосредственно следующей метки индекса также меньше W3. Она не может быть исключена, потому что непосредственно следующая метка индекса 1 не имеет того же значения UserID, что и текущая метка 0.
В итоге это не позволяет ClickHouse делать предположения о максимальном значении URL в грануле 0. Вместо этого он должен предполагать, что гранула 0 потенциально содержит строки со значением URL W3 и вынужден выбрать метку 0.
Такая же ситуация имеет место для меток 1, 2 и 3.
Универсальный алгоритм поиска с исключением, который ClickHouse использует вместо алгоритма бинарного поиска, когда запрос фильтрует по столбцу, являющемуся частью составного ключа, но не первым столбцом ключа, наиболее эффективен, когда предшествующий ключевой столбец имеет низкую (или более низкую) кардинальность.
В нашем примерном наборе данных оба ключевых столбца (UserID, URL) имеют схожую высокую кардинальность, и, как уже объяснялось, универсальный алгоритм поиска с исключением не очень эффективен, когда предшествующий ключевой столбец для столбца URL имеет высокую (или схожую) кардинальность.
Примечание об индексе пропуска данных
Из-за схожей высокой кардинальности UserID и URL наша фильтрация запросов по URL также не дала бы существенного выигрыша от создания вторичного индекса пропуска данных на столбце URL
в нашей таблице с составным первичным ключом (UserID, URL).
Например, следующие два SQL-оператора создают и заполняют индекс пропуска данных minmax на столбце URL нашей таблицы:
ClickHouse создал дополнительный индекс, который хранит — для каждой группы из 4 последовательных гранул (обратите внимание на параметр GRANULARITY 4 в приведённой выше инструкции ALTER TABLE) — минимальное и максимальное значение URL:

Первая запись индекса ('mark 0' на диаграмме выше) хранит минимальное и максимальное значения URL для строк, принадлежащих первым 4 гранулам таблицы.
Вторая запись индекса ('mark 1') хранит минимальное и максимальное значения URL для строк, принадлежащих следующим 4 гранулам таблицы, и так далее.
(ClickHouse также создал специальный файл меток для индекса пропуска данных, который используется для определения местоположения групп гранул, связанных с метками индекса.)
Из-за аналогично высокой кардинальности UserID и URL этот вторичный индекс пропуска данных не может помочь в исключении гранул из выборки при выполнении запроса с фильтрацией по URL.
Конкретное значение URL, которое ищет запрос (т. е. 'http://public_search') с высокой вероятностью находится между минимальным и максимальным значением, сохранённым индексом для каждой группы гранул, что вынуждает ClickHouse выбирать группу гранул (поскольку они могут содержать строки, соответствующие запросу).
Необходимость использования нескольких первичных индексов
Таким образом, если мы хотим значительно ускорить наш пример запроса, который фильтрует строки с конкретным URL-адресом, нам нужно использовать первичный индекс, оптимизированный под этот запрос.
Если при этом мы хотим сохранить хорошую производительность нашего примера запроса, который фильтрует строки с конкретным значением UserID, нам нужно использовать несколько первичных индексов.
Ниже показаны способы добиться этого.
Варианты создания дополнительных первичных индексов
Если мы хотим существенно ускорить оба наших примерных запроса — как тот, который фильтрует строки по конкретному UserID, так и тот, который фильтрует строки по конкретному URL, — то нам нужно использовать несколько первичных индексов, выбрав один из трёх вариантов:
- Создание второй таблицы с другим первичным ключом.
- Создание материализованного представления на нашей существующей таблице.
- Добавление проекции к нашей существующей таблице.
Все три варианта фактически дублируют наши примерные данные в дополнительной таблице, чтобы изменить первичный индекс таблицы и порядок сортировки строк.
Однако эти три варианта различаются тем, насколько дополнительная таблица прозрачна для пользователя с точки зрения маршрутизации запросов и операторов INSERT.
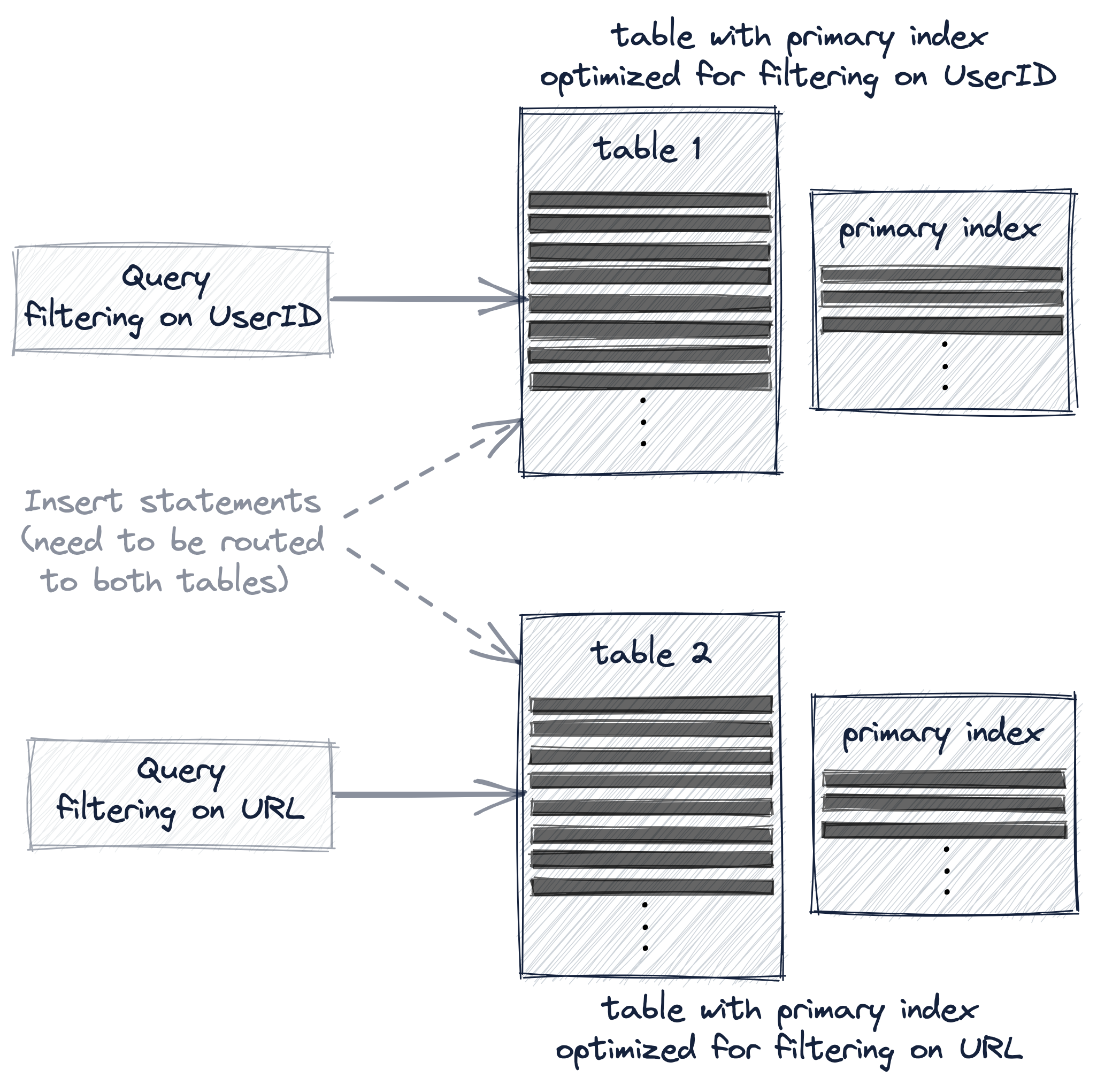
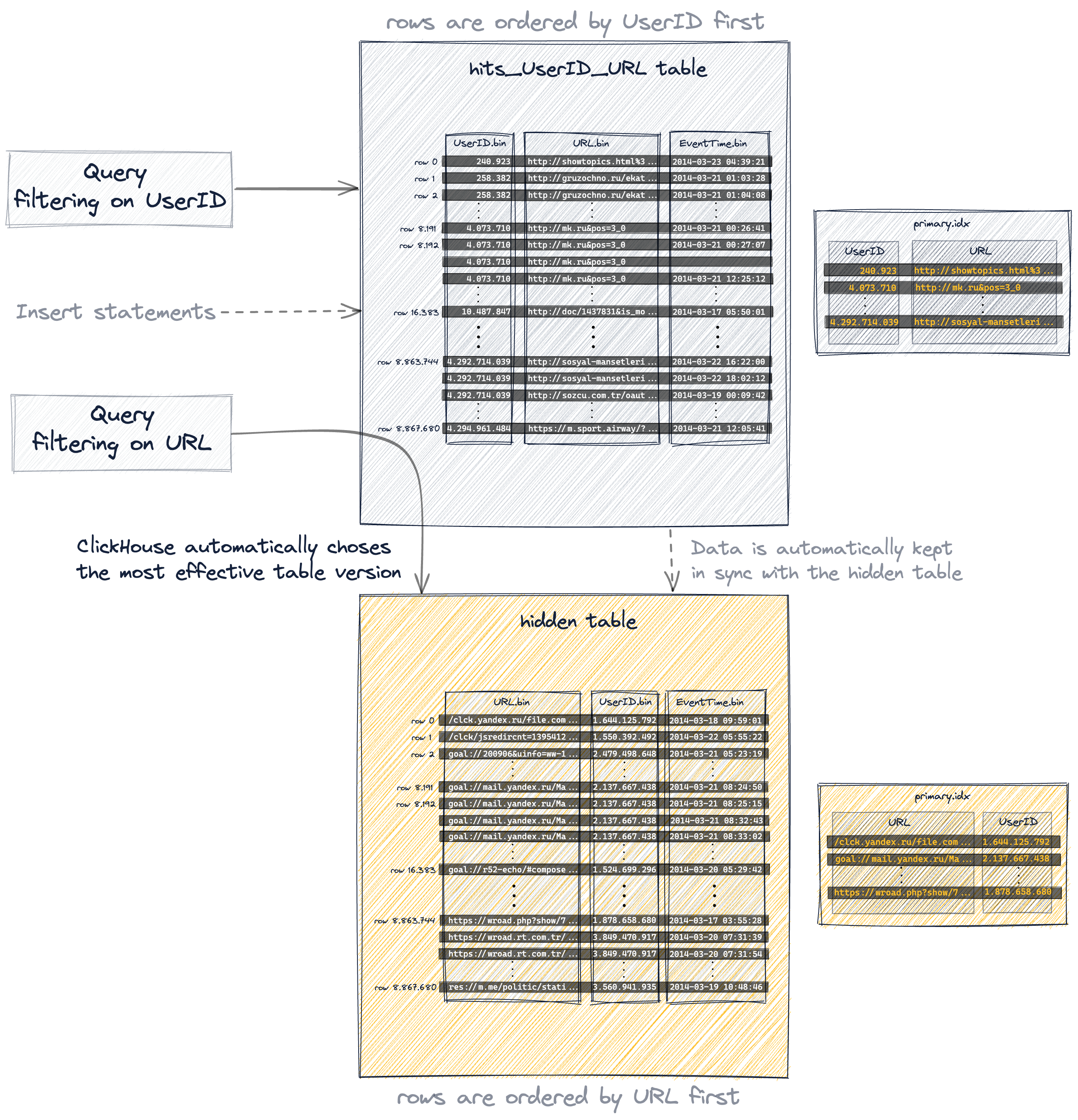
При создании второй таблицы с другим первичным ключом запросы должны явно отправляться в ту версию таблицы, которая лучше всего подходит для конкретного запроса, а новые данные должны явно вставляться в обе таблицы, чтобы поддерживать их в синхронном состоянии:
При использовании материализованного представления дополнительная таблица создаётся неявно, и данные автоматически поддерживаются синхронизированными между обеими таблицами:
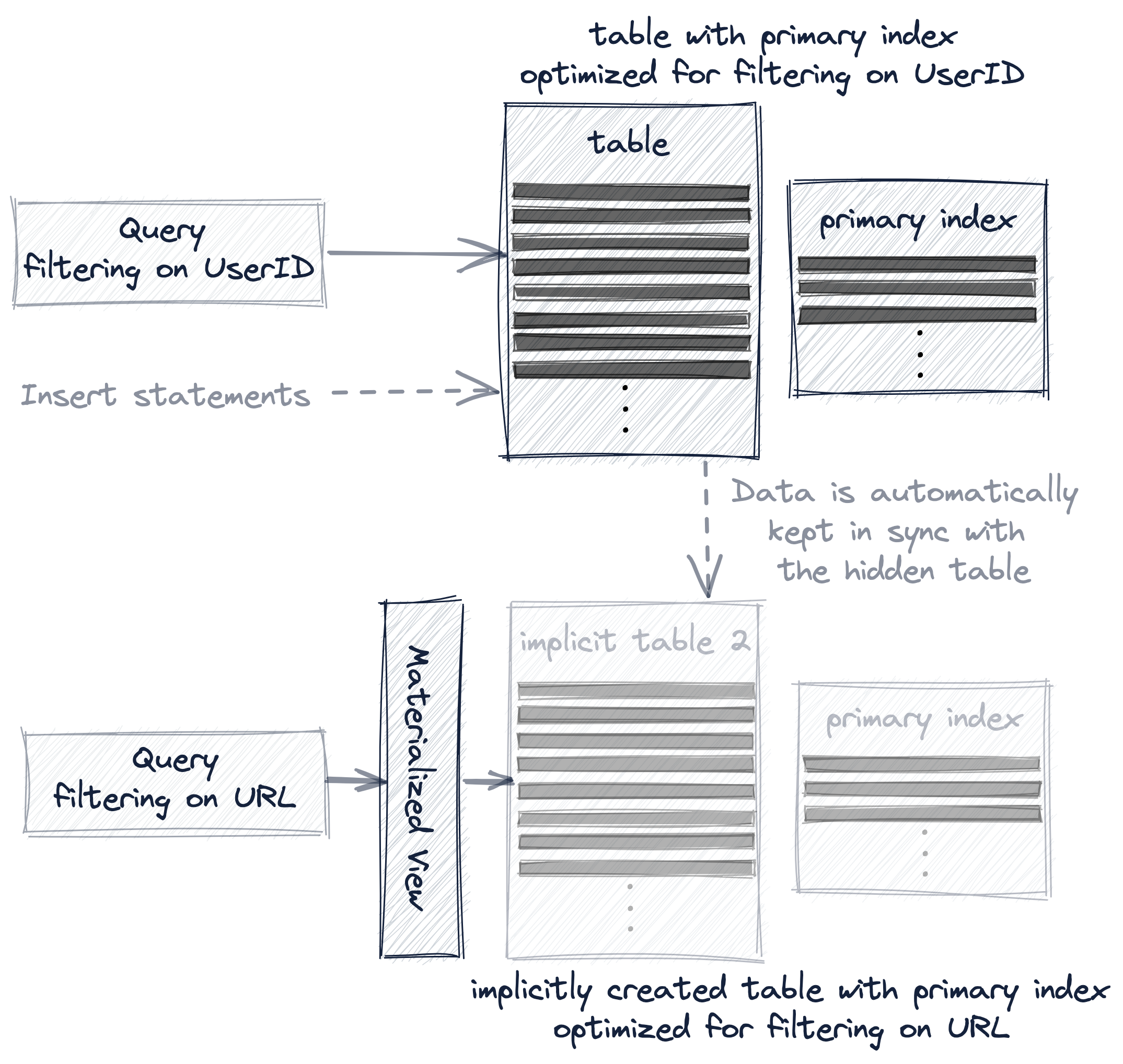
А проекция — наиболее прозрачный вариант, потому что помимо автоматического поддержания неявно созданной (и скрытой) дополнительной таблицы в актуальном состоянии при изменении данных, ClickHouse будет автоматически выбирать наиболее эффективную версию таблицы для запросов:
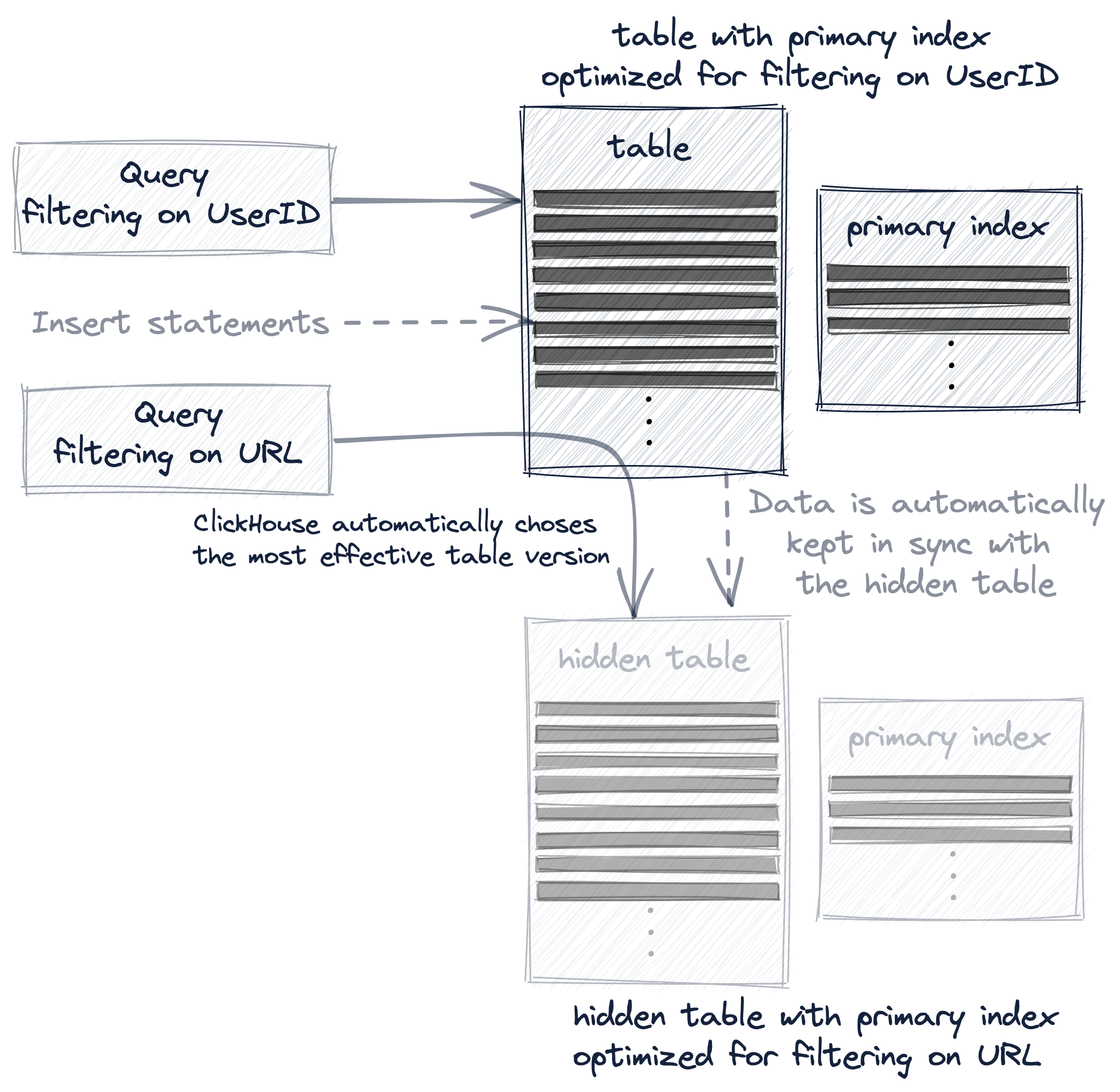
В дальнейшем мы подробнее рассмотрим эти три варианта создания и использования нескольких первичных индексов на реальных примерах.
Вариант 1: вторичные таблицы
Мы создаём новую вторичную таблицу, в которой меняем порядок столбцов первичного ключа по сравнению с исходной таблицей:
Вставьте все 8,87 миллиона строк из нашей исходной таблицы в дополнительную таблицу:
Ответ будет выглядеть так:
Наконец, оптимизируйте таблицу:
Поскольку мы поменяли порядок столбцов в первичном ключе, вставленные строки теперь хранятся на диске в другом лексикографическом порядке (по сравнению с нашей исходной таблицей), и, следовательно, 1083 гранулы этой таблицы теперь содержат другие значения, чем раньше:
В результате получился следующий первичный ключ:

Теперь его можно использовать для значительного ускорения выполнения нашего примерного запроса с фильтрацией по столбцу URL, чтобы вычислить топ-10 пользователей, которые чаще всего кликали по URL "http://public_search":
Ответ:
Теперь, вместо почти полного сканирования всей таблицы, ClickHouse выполнил этот запрос гораздо эффективнее.
С первичным индексом из исходной таблицы, где UserID был первым, а URL — вторым ключевым столбцом, ClickHouse использовал обобщённый алгоритм исключающего поиска по меткам индекса для выполнения этого запроса, и это было не очень эффективно из-за схожей высокой кардинальности UserID и URL.
При URL в качестве первого столбца в первичном индексе ClickHouse теперь выполняет двоичный поиск по меткам индекса. Соответствующая запись трассировки в журнале сервера ClickHouse подтверждает это:
ClickHouse выбрал только 39 меток индекса вместо 1076, которые были выбраны при использовании generic exclusion search.
Обратите внимание, что дополнительная таблица оптимизирована для ускорения выполнения нашего примерного запроса с фильтрацией по URL.
Подобно плохой производительности этого запроса с нашей исходной таблицей, наш пример запроса с фильтрацией по UserIDs также не будет выполняться эффективно с новой дополнительной таблицей, потому что теперь UserID является вторым столбцом ключа в первичном индексе этой таблицы и, следовательно, ClickHouse будет использовать generic exclusion search для выбора гранул, который не очень эффективен при сопоставимо высокой кардинальности UserID и URL.
Откройте блок с подробностями, чтобы увидеть детали.
Теперь у нас есть две таблицы, каждая из которых оптимизирована для ускорения запросов с фильтрацией по UserIDs и по URL соответственно:
Вариант 2: материализованное представление
Создайте материализованное представление на основе нашей существующей таблицы.
Ответ будет выглядеть примерно так:
- мы меняем порядок ключевых столбцов (по сравнению с исходной таблицей) в первичном ключе представления
- материализованное представление опирается на неявно созданную таблицу, порядок строк и первичный индекс которой основаны на заданном определении первичного ключа
- неявно созданная таблица отображается в результате запроса
SHOW TABLESи имеет имя, начинающееся с.inner - также возможно сначала явно создать таблицу-основание для материализованного представления, после чего представление может указывать на эту таблицу через предложение
TO [db].[table]в операторе - мы используем ключевое слово
POPULATE, чтобы немедленно заполнить неявно созданную таблицу всеми 8,87 миллионами строк из исходной таблицы hits_UserID_URL - если в исходную таблицу hits_UserID_URL вставляются новые строки, то эти строки автоматически вставляются и в неявно созданную таблицу
- фактически неявно созданная таблица имеет тот же порядок строк и тот же первичный индекс, что и вторичная таблица, которую мы создали явно:
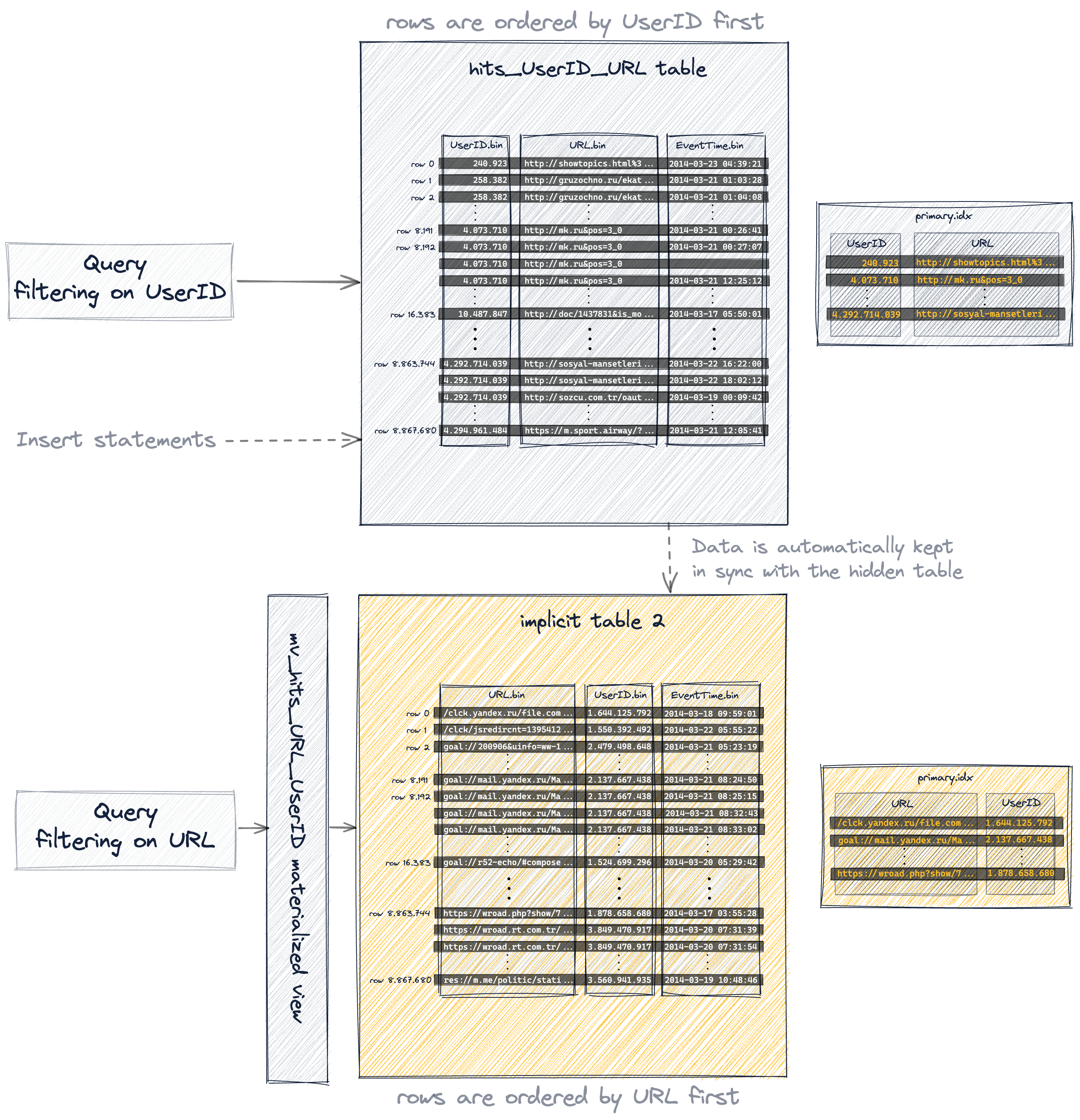
ClickHouse хранит файлы данных столбцов (.bin), файлы меток (.mrk2) и первичный индекс (primary.idx) неявно созданной таблицы в специальной папке внутри каталога данных сервера ClickHouse:
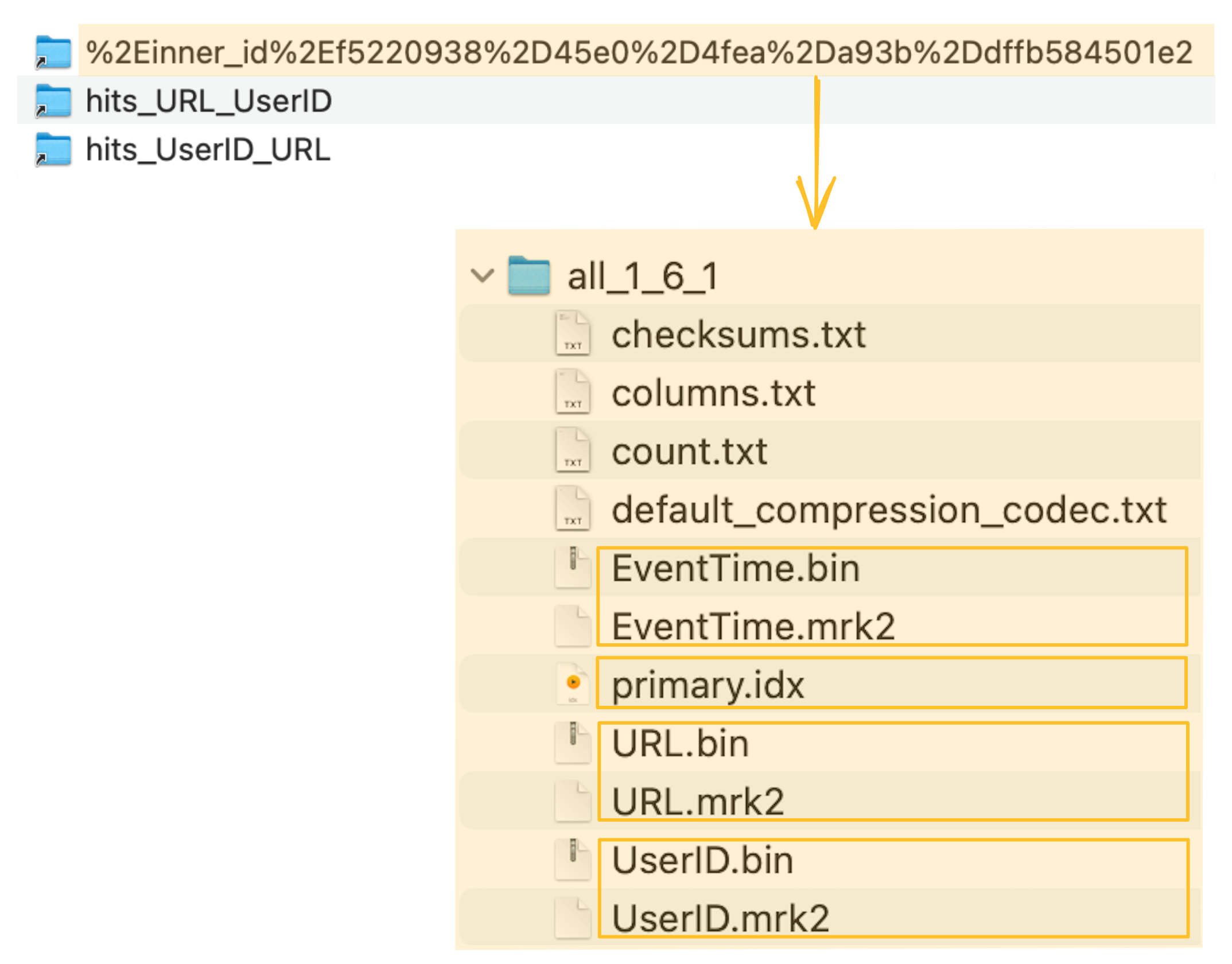
Неявно созданная таблица (и её первичный индекс), лежащая в основе материализованного представления, теперь может использоваться для значительного ускорения выполнения нашего примерного запроса с фильтрацией по столбцу URL:
Ответ:
Поскольку по сути неявно созданная таблица (и её первичный индекс), лежащая в основе материализованного представления, идентична вторичной таблице, которую мы создали явно, запрос выполняется столь же эффективно, как и с явно созданной таблицей.
Соответствующая запись трассировки в журнале сервера ClickHouse подтверждает, что ClickHouse выполняет двоичный поиск по меткам индекса:
Вариант 3: проекции
Создайте проекцию для нашей существующей таблицы:
Материализуйте проекцию:
- проекция создает скрытую таблицу, порядок строк и первичный индекс которой основаны на заданном в проекции предложении
ORDER BY - скрытая таблица не отображается в результате запроса
SHOW TABLES - мы используем ключевое слово
MATERIALIZE, чтобы немедленно заполнить скрытую таблицу всеми 8.87 миллионами строк из исходной таблицы hits_UserID_URL - если в исходную таблицу hits_UserID_URL добавляются новые строки, эти строки автоматически добавляются и в скрытую таблицу
- запрос всегда (синтаксически) нацелен на исходную таблицу hits_UserID_URL, но если порядок строк и первичный индекс скрытой таблицы позволяют более эффективно выполнить запрос, то будет использована именно эта скрытая таблица
- обратите внимание, что проекции не делают более эффективными запросы, использующие ORDER BY, даже если выражение ORDER BY совпадает с выражением ORDER BY в проекции (см. https://github.com/ClickHouse/ClickHouse/issues/47333)
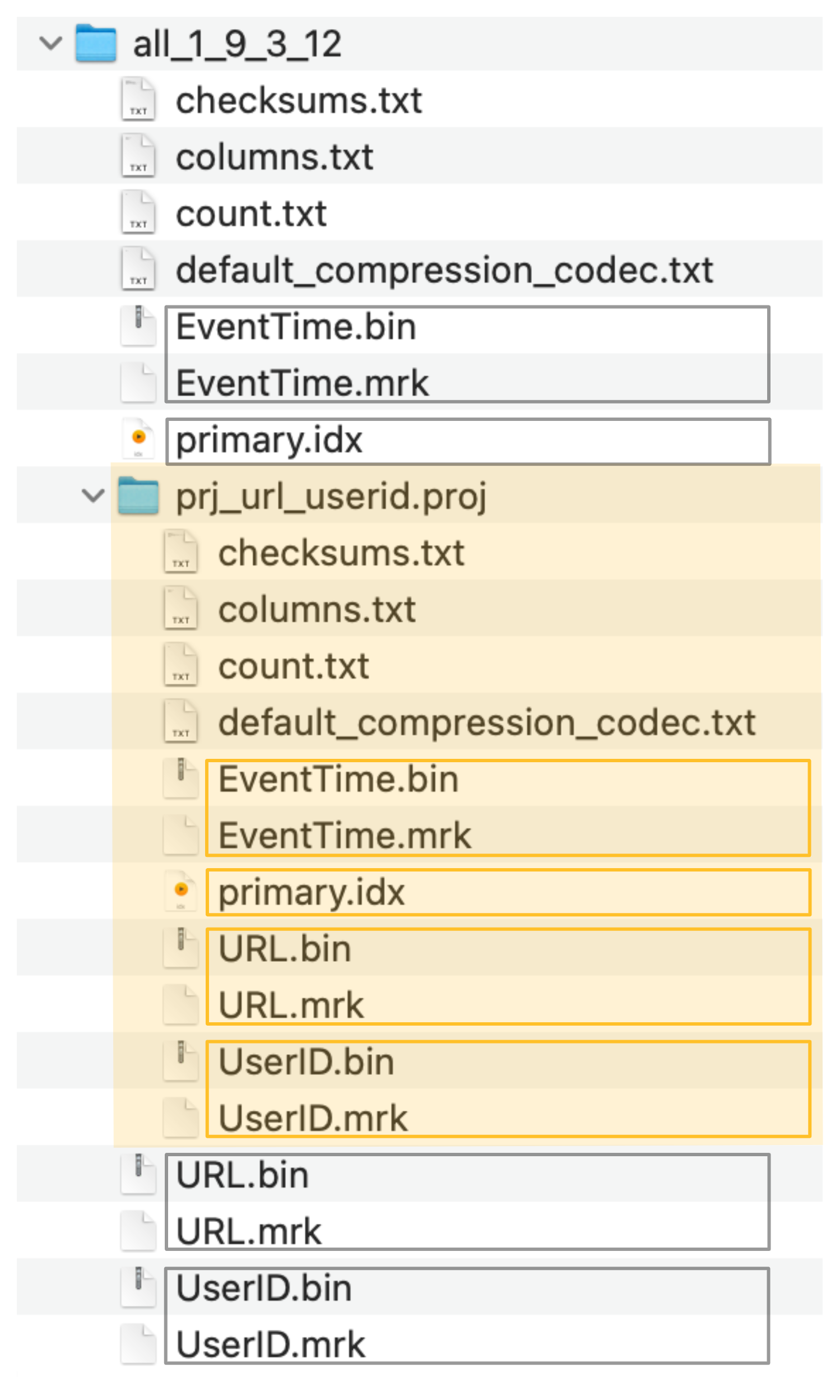
- фактически неявно созданная скрытая таблица имеет тот же порядок строк и первичный индекс, что и вторичная таблица, которую мы создали явным образом:
ClickHouse хранит файлы данных столбцов (.bin), файлы меток (.mrk2) и первичный индекс (primary.idx) скрытой таблицы в специальной папке (выделена оранжевым на скриншоте ниже) рядом с файлами данных, файлами меток и файлами первичного индекса исходной таблицы:
Скрытая таблица (и её первичный индекс), созданная проекцией, теперь может (неявно) использоваться для значительного ускорения выполнения нашего примерного запроса, выполняющего фильтрацию по столбцу URL. Обратите внимание, что запрос синтаксически нацелен на исходную таблицу, для которой определена проекция.
Ответ:
Поскольку скрытая таблица (и её первичный индекс), создаваемая проекцией, по сути идентична вторичной таблице, которую мы создали явно, запрос выполняется столь же эффективно, как и с явно созданной таблицей.
Соответствующая трассировочная запись в серверном журнале ClickHouse подтверждает, что ClickHouse выполняет двоичный поиск по меткам индекса:
Итоги
Первичный индекс нашей таблицы со составным первичным ключом (UserID, URL) был очень полезен для ускорения запроса с фильтрацией по UserID. Но этот индекс почти не помогает при ускорении запроса с фильтрацией по URL, несмотря на то, что столбец URL является частью составного первичного ключа.
И наоборот: Первичный индекс нашей таблицы со составным первичным ключом (URL, UserID) ускорял запрос с фильтрацией по URL, но не давал заметного ускорения для запроса с фильтрацией по UserID.
Из‑за похожей высокой кардинальности столбцов первичного ключа UserID и URL запрос, который фильтрует по второму столбцу ключа, почти не выигрывает от того, что второй столбец ключа включён в индекс.
Поэтому имеет смысл удалить второй столбец ключа из первичного индекса (что уменьшит потребление памяти индексом) и вместо этого использовать несколько первичных индексов.
Однако если столбцы ключа в составном первичном ключе сильно различаются по кардинальности, то для запросов полезно упорядочивать столбцы первичного ключа по кардинальности в порядке возрастания.
Чем больше разница в кардинальности между столбцами ключа, тем сильнее порядок этих столбцов в ключе влияет на эффективность. В следующем разделе мы это продемонстрируем.
Эффективный порядок столбцов ключа
В составном первичном ключе порядок столбцов ключа может существенно влиять на:
- эффективность фильтрации по вторичным столбцам ключа в запросах;
- коэффициент сжатия файлов данных таблицы.
Чтобы продемонстрировать это, мы будем использовать версию нашего примерного набора данных веб‑трафика,
где каждая строка содержит три столбца, которые показывают, был ли доступ интернет‑«пользователя» (столбец UserID) к URL (столбец URL) помечен как бот‑трафик (столбец IsRobot).
Мы будем использовать составной первичный ключ, содержащий все три вышеупомянутых столбца, который можно использовать для ускорения типичных запросов веб‑аналитики, вычисляющих
- какова доля (в процентах) трафика к конкретному URL, приходящаяся на ботов, или
- насколько мы уверены, что конкретный пользователь является (не является) ботом (какой процент трафика от этого пользователя считается (не) бот‑трафиком).
Мы используем этот запрос для вычисления кардинальностей трёх столбцов, которые мы хотим использовать в качестве столбцов ключа в составном первичном ключе (обратите внимание, что мы используем табличную функцию URL для разового запроса TSV‑данных без необходимости создавать локальную таблицу). Выполните этот запрос в clickhouse client:
Ответ:
Мы видим, что существует большая разница в кардинальности (числе различных значений), особенно между столбцами URL и IsRobot, и поэтому порядок этих столбцов в составном первичном ключе важен как для эффективного ускорения запросов, которые фильтруют по этим столбцам, так и для достижения оптимальных коэффициентов сжатия для файлов данных столбцов этой таблицы.
Чтобы продемонстрировать это, мы создадим две версии таблицы для наших данных анализа бот-трафика:
- таблицу
hits_URL_UserID_IsRobotс составным первичным ключом(URL, UserID, IsRobot), где мы упорядочиваем столбцы ключа по кардинальности по убыванию; - таблицу
hits_IsRobot_UserID_URLс составным первичным ключом(IsRobot, UserID, URL), где мы упорядочиваем столбцы ключа по кардинальности по возрастанию.
Создайте таблицу hits_URL_UserID_IsRobot с составным первичным ключом (URL, UserID, IsRobot):
И заполните её 8,87 млн строк:
Это ответ:
Далее создайте таблицу hits_IsRobot_UserID_URL со составным первичным ключом (IsRobot, UserID, URL):
И заполните её теми же 8,87 миллионами строк, которые мы использовали для предыдущей таблицы:
Ответ:
Эффективная фильтрация по вторичным столбцам ключа
Когда запрос фильтрует по крайней мере одному столбцу, который является частью составного ключа и является первым столбцом ключа, ClickHouse выполняет алгоритм бинарного поиска по индексным меткам ключевого столбца.
Когда запрос фильтрует (только) по столбцу, который является частью составного ключа, но не является первым столбцом ключа, ClickHouse использует универсальный алгоритм исключающего поиска по индексным меткам ключевого столбца.
Во втором случае порядок столбцов в составном первичном ключе имеет существенное значение для эффективности универсального алгоритма исключающего поиска.
Ниже приведён запрос, который фильтрует по столбцу UserID таблицы, где мы упорядочили столбцы ключа (URL, UserID, IsRobot) по кардинальности в порядке убывания:
Ответ:
Это тот же запрос к таблице, в которой ключевые столбцы (IsRobot, UserID, URL) упорядочены по возрастанию кардинальности:
Ответ:
Мы видим, что выполнение запроса значительно эффективнее и быстрее на таблице, в которой столбцы ключа отсортированы по кардинальности по возрастанию.
Причина в том, что generic exclusion search algorithm работает наиболее эффективно, когда гранулы выбираются по столбцу вторичного ключа, при этом предшествующий ему столбец ключа имеет более низкую кардинальность. Мы подробно показали это в предыдущем разделе данного руководства.
Оптимальный коэффициент сжатия файлов данных
Этот запрос сравнивает коэффициент сжатия столбца UserID в двух таблицах, созданных выше:
Вот ответ:
Мы видим, что коэффициент сжатия для столбца UserID значительно выше для таблицы, в которой мы упорядочили ключевые столбцы (IsRobot, UserID, URL) по возрастанию кардинальности.
Хотя в обеих таблицах хранится в точности один и тот же набор данных (мы вставили одинаковые 8,87 миллиона строк в обе таблицы), порядок ключевых столбцов в составном первичном ключе существенно влияет на то, сколько дискового пространства требуют сжатые данные в файлах данных столбцов таблицы:
- в таблице
hits_URL_UserID_IsRobotс составным первичным ключом(URL, UserID, IsRobot), где ключевые столбцы упорядочены по кардинальности по убыванию, файл данныхUserID.binзанимает 11.24 MiB дискового пространства; - в таблице
hits_IsRobot_UserID_URLс составным первичным ключом(IsRobot, UserID, URL), где ключевые столбцы упорядочены по кардинальности по возрастанию, файл данныхUserID.binзанимает всего 877.47 KiB дискового пространства.
Хороший коэффициент сжатия данных столбца таблицы на диске не только экономит место на диске, но и ускоряет запросы (особенно аналитические), которым требуется чтение данных из этого столбца, так как требуется меньше операций ввода-вывода для перемещения данных столбца с диска в основную память (файловый кэш операционной системы).
Далее мы покажем, почему для достижения хорошего коэффициента сжатия данных столбцов таблицы полезно упорядочивать столбцы первичного ключа по кардинальности по возрастанию.
Ниже представлена схема порядка строк на диске для первичного ключа, в котором ключевые столбцы упорядочены по кардинальности по возрастанию:

Мы уже обсуждали, что данные строк таблицы хранятся на диске, упорядоченные по столбцам первичного ключа.
На диаграмме выше строки таблицы (их значения столбцов на диске) сначала упорядочены по значению cl, а строки с одинаковым значением cl упорядочены по значению ch. И поскольку первый ключевой столбец cl имеет низкую кардинальность, вероятно, что существует несколько строк с одинаковым значением cl. Из этого, в свою очередь, следует, что значения ch также, с высокой вероятностью, будут упорядочены (локально — для строк с одинаковым значением cl).
Если в столбце похожие данные размещены близко друг к другу, например за счёт сортировки, то такие данные будут сжиматься лучше. В общем случае алгоритм сжатия выигрывает от длины последовательностей данных (чем больше данных он видит, тем лучше сжатие) и локальности (чем больше данные похожи друг на друга, тем лучше коэффициент сжатия).
В противоположность диаграмме выше, следующая диаграмма иллюстрирует порядок строк на диске для первичного ключа, в котором ключевые столбцы упорядочены по кардинальности по убыванию:

Теперь строки таблицы сначала упорядочены по их значению ch, а строки с одинаковым значением ch — по их значению cl.
Но поскольку первый ключевой столбец ch имеет высокую кардинальность, маловероятно, что вообще есть строки с одинаковым значением ch. А из‑за этого также маловероятно, что значения cl будут упорядочены (локально — для строк с одинаковым значением ch).
Следовательно, значения cl, скорее всего, находятся в случайном порядке и, соответственно, обладают плохой локальностью и коэффициентом сжатия.
Итоги
Для более эффективной фильтрации по вторичным ключевым столбцам в запросах и для улучшения степени сжатия файлов данных столбцов таблицы рекомендуется упорядочивать столбцы в первичном ключе по их кардинальности в порядке возрастания.
Эффективная идентификация отдельных строк
Хотя в общем случае это не лучший сценарий использования ClickHouse, иногда приложения, построенные поверх ClickHouse, должны уметь однозначно идентифицировать отдельные строки таблицы ClickHouse.
Интуитивным решением может быть использование столбца UUID с уникальным значением для каждой строки и использование этого столбца в качестве столбца первичного ключа для быстрого извлечения строк.
Для максимально быстрого извлечения столбец UUID должен быть первым столбцом ключа.
Мы обсуждали, что поскольку данные строк таблицы ClickHouse хранятся на диске в порядке, заданном столбцами первичного ключа, наличие столбца с очень высокой кардинальностью (например, столбца UUID) в первичном ключе или в составном первичном ключе перед столбцами с более низкой кардинальностью негативно влияет на коэффициент сжатия других столбцов таблицы.
Компромиссом между максимально быстрым извлечением и оптимальным сжатием данных является использование составного первичного ключа, в котором UUID является последним столбцом ключа, после столбцов с низкой (или более низкой) кардинальностью, обеспечивающих хороший коэффициент сжатия для части столбцов таблицы.
Конкретный пример
Одним конкретным примером является сервис текстовых вставок https://pastila.nl, который разработал Алексей Миловидов и о котором он написал в блоге.
При каждом изменении в текстовой области данные автоматически сохраняются в строку таблицы ClickHouse (одна строка на одно изменение).
Один из способов идентифицировать и получить (конкретную версию) вставленного содержимого — использовать хеш содержимого как UUID для строки таблицы, которая содержит это содержимое.
На следующей диаграмме показаны
- порядок вставки строк при изменении содержимого (например, из‑за нажатий клавиш при вводе текста в текстовую область) и
- порядок расположения на диске данных из вставленных строк, когда используется
PRIMARY KEY (hash):

Поскольку столбец hash используется как столбец первичного ключа,
- отдельные строки можно извлекать очень быстро, но
- строки таблицы (их данные столбцов) хранятся на диске в порядке возрастания (уникальных и случайных) значений хеша. Поэтому значения столбца с содержимым также хранятся в случайном порядке, без локальности данных, что приводит к неоптимальному коэффициенту сжатия файла данных столбца с содержимым.
Чтобы существенно улучшить коэффициент сжатия для столбца с содержимым и при этом сохранить быструю выборку отдельных строк, pastila.nl использует два хеша (и составной первичный ключ) для идентификации конкретной строки:
- хеш содержимого, как обсуждалось выше, который различается для разных данных, и
- локально-чувствительный хеш (отпечаток), который не меняется при небольших изменениях данных.
На следующей диаграмме показаны
- порядок вставки строк при изменении содержимого (например, из‑за нажатий клавиш при вводе текста в текстовую область) и
- порядок расположения на диске данных из вставленных строк, когда используется составной
PRIMARY KEY (fingerprint, hash):

Теперь строки на диске сначала упорядочены по fingerprint, а для строк с одинаковым значением fingerprint их значение hash определяет окончательный порядок.
Поскольку данные, отличающиеся только небольшими изменениями, получают одно и то же значение fingerprint, похожие данные теперь хранятся на диске близко друг к другу в столбце с содержимым. И это очень хорошо для коэффициента сжатия столбца с содержимым, так как алгоритм сжатия в целом выигрывает от локальности данных (чем более похожи данные, тем лучше коэффициент сжатия).
Компромисс состоит в том, что для выборки конкретной строки требуются два поля (fingerprint и hash), чтобы оптимально использовать первичный индекс, который получается из составного PRIMARY KEY (fingerprint, hash).
