Репликация данных
В этом примере вы узнаете, как настроить простой кластер ClickHouse, который реплицирует данные. Настроено пять серверов. Два из них используются для хранения копий данных. Оставшиеся три сервера отвечают за координацию репликации данных.
Архитектура кластера, который вы будете настраивать, показана ниже:
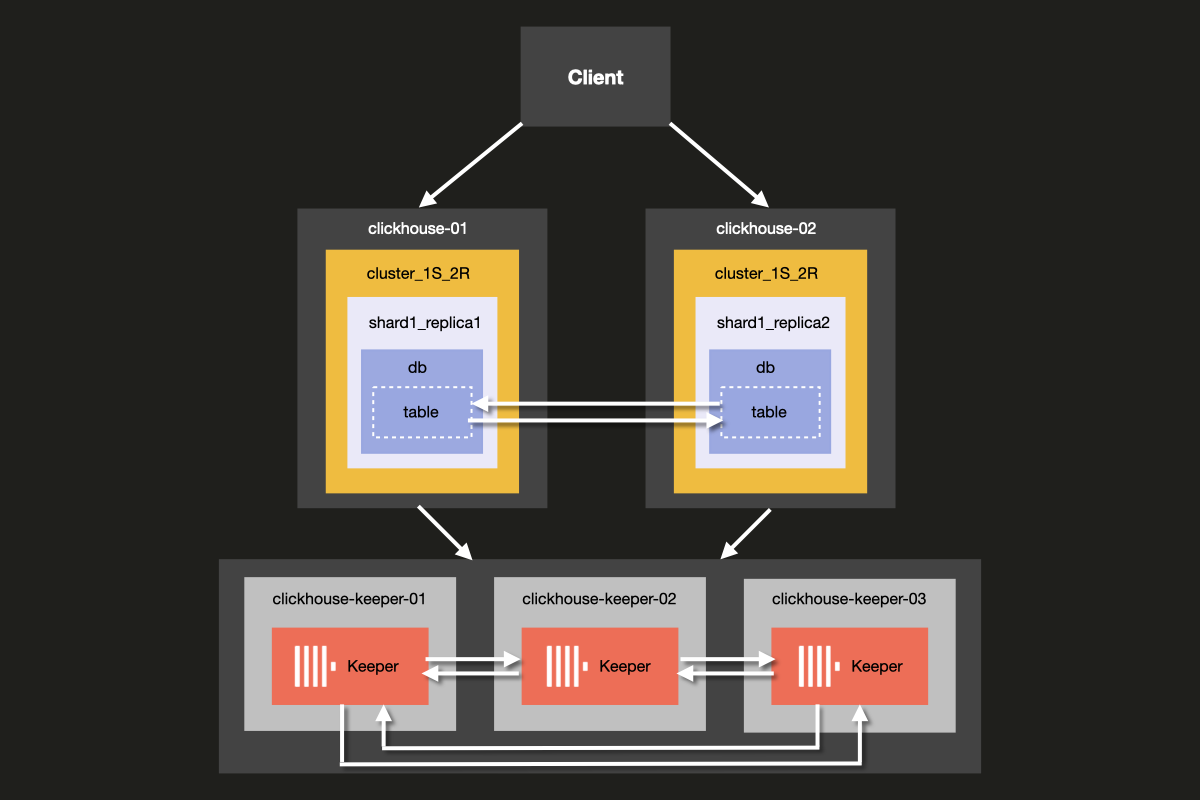
Хотя можно запускать ClickHouse Server и ClickHouse Keeper вместе на одном сервере, мы настоятельно рекомендуем использовать выделенные хосты для ClickHouse Keeper в продукционных средах — именно этот подход мы продемонстрируем в данном примере.
Серверы Keeper могут быть менее мощными, и в большинстве случаев 4 ГБ ОЗУ достаточно для каждого сервера Keeper, пока ваши серверы ClickHouse существенно не вырастут.
Предварительные требования
- Ранее вы уже развернули локальный сервер ClickHouse
- Вы знакомы с базовыми принципами настройки ClickHouse, в частности с файлами конфигурации
- На вашем компьютере установлен Docker
Настройка структуры каталогов и тестовой среды
Следующие шаги помогут вам настроить кластер с нуля. Если вы предпочитаете пропустить эти шаги и сразу перейти к запуску кластера, вы можете получить примерные файлы из репозитория ClickHouse Examples, каталог 'docker-compose-recipes'.
В этом руководстве вы будете использовать Docker Compose для развёртывания кластера ClickHouse. Эту конфигурацию можно адаптировать для работы на отдельных локальных машинах, виртуальных машинах или облачных инстансах.
Выполните следующие команды для создания структуры каталогов для этого примера:
Добавьте следующий файл docker-compose.yml в каталог cluster_1S_2R:
Создайте следующие подкаталоги и файлы:
- Каталог
config.dсодержит файл конфигурации сервера ClickHouseconfig.xml, в котором задаётся пользовательская конфигурация для каждого узла ClickHouse. Эта конфигурация объединяется с файлом конфигурации ClickHouseconfig.xmlпо умолчанию, который устанавливается вместе с каждым экземпляром ClickHouse. - Каталог
users.dсодержит файл конфигурации пользователейusers.xml, в котором задаётся пользовательская конфигурация для пользователей. Эта конфигурация объединяется с файлом конфигурации ClickHouseusers.xmlпо умолчанию, который устанавливается вместе с каждым экземпляром ClickHouse.
Рекомендуется использовать каталоги config.d и users.d при написании собственной
конфигурации, вместо того чтобы напрямую изменять конфигурацию по умолчанию
в /etc/clickhouse-server/config.xml и etc/clickhouse-server/users.xml.
Строка
Обеспечивает, что разделы конфигурации, определённые в каталогах config.d и users.d,
имеют приоритет над разделами конфигурации по умолчанию, заданными в файлах
config.xml и users.xml.
Настройка узлов ClickHouse
Настройка сервера
Теперь измените каждый пустой файл конфигурации config.xml, расположенный по пути
fs/volumes/clickhouse-{}/etc/clickhouse-server/config.d. Строки, выделенные
ниже, должны быть изменены для каждого узла отдельно:
| Каталог | Файл |
|---|---|
fs/volumes/clickhouse-01/etc/clickhouse-server/config.d | config.xml |
fs/volumes/clickhouse-02/etc/clickhouse-server/config.d | config.xml |
Каждый раздел указанного выше конфигурационного файла подробно описан ниже.
Сеть и логирование
Внешние подключения к сетевому интерфейсу разрешаются путем активации параметра listen_host. Это гарантирует, что сервер ClickHouse доступен для других хостов:
Порт HTTP API установлен в значение 8123:
TCP-порт для взаимодействия по собственному протоколу ClickHouse между clickhouse-client
и другими нативными инструментами ClickHouse, а также между clickhouse-server и другими экземплярами clickhouse-server
равен 9000:
Логирование настраивается в блоке <logger>. Данная конфигурация создаёт
отладочный журнал, который будет ротироваться при достижении размера 1000M три раза:
Дополнительную информацию о настройке логирования см. в комментариях стандартного файла конфигурации ClickHouse.
Конфигурация кластера
Конфигурация кластера задаётся в блоке <remote_servers>.
Здесь определено имя кластера cluster_1S_2R.
Блок <cluster_1S_2R></cluster_1S_2R> определяет топологию кластера
с помощью параметров <shard></shard> и <replica></replica> и служит
шаблоном для распределённых DDL-запросов — запросов, выполняемых на всём
кластере с использованием конструкции ON CLUSTER. По умолчанию распределённые DDL-запросы
разрешены, но их можно отключить параметром allow_distributed_ddl_queries.
internal_replication установлен в true, чтобы данные записывались только на одну из реплик.
Для каждого сервера задаются следующие параметры:
| Parameter | Description | Default Value |
|---|---|---|
host | Адрес удалённого сервера. Можно использовать доменное имя либо IPv4- или IPv6-адрес. Если указан домен, при запуске сервер выполняет DNS-запрос и сохраняет результат на всё время своей работы. Если DNS-запрос завершился с ошибкой, сервер не запускается. При изменении DNS-записи сервер необходимо перезапустить. | - |
port | TCP-порт для обмена сообщениями (tcp_port в конфигурации, обычно 9000). Не путать с http_port. | - |
Конфигурация Keeper
Секция <ZooKeeper> указывает ClickHouse, где запущен ClickHouse Keeper (или ZooKeeper).
Поскольку используется кластер ClickHouse Keeper, необходимо указать каждый узел <node> кластера
вместе с его именем хоста и номером порта с помощью тегов <host> и <port> соответственно.
Настройка ClickHouse Keeper описана на следующем шаге руководства.
Хотя ClickHouse Keeper можно запустить на том же сервере, что и ClickHouse Server, для production-окружений мы настоятельно рекомендуем использовать выделенные хосты для ClickHouse Keeper.
Конфигурация макросов
Кроме того, секция <macros> используется для определения подстановки параметров для
реплицируемых таблиц. Они перечислены в system.macros и позволяют использовать подстановки
типа {shard} и {replica} в запросах.
Эти параметры определяются индивидуально в зависимости от конфигурации кластера.
Настройка пользователя
Теперь измените каждый пустой конфигурационный файл users.xml, расположенный в
fs/volumes/clickhouse-{}/etc/clickhouse-server/users.d, следующим образом:
| Содержание | Файл |
|---|---|
fs/volumes/clickhouse-01/etc/clickhouse-server/users.d | users.xml |
fs/volumes/clickhouse-02/etc/clickhouse-server/users.d | users.xml |
В данном примере пользователь по умолчанию настроен без пароля для упрощения. На практике это не рекомендуется.
В данном примере файл users.xml одинаков для всех узлов кластера.
Настройка ClickHouse Keeper
Настройка Keeper
Чтобы репликация работала, необходимо развернуть и настроить кластер ClickHouse Keeper. ClickHouse Keeper предоставляет систему координации для репликации данных, выступая полноценной заменой Zookeeper, который также может использоваться. Однако рекомендуется использовать ClickHouse Keeper, так как он обеспечивает более надежные гарантии, выше общую надежность и использует меньше ресурсов, чем ZooKeeper. Для высокой доступности и сохранения кворума рекомендуется запускать как минимум три узла ClickHouse Keeper.
ClickHouse Keeper может работать на любом узле кластера вместе с ClickHouse, хотя рекомендуется запускать его на выделенном узле, что позволяет масштабировать и управлять кластером ClickHouse Keeper независимо от кластера базы данных.
Создайте файлы keeper_config.xml для каждого узла ClickHouse Keeper,
используя следующую команду из корневого каталога примера:
Измените пустые файлы конфигурации, которые были созданы в каждом
каталоге узла fs/volumes/clickhouse-keeper-{}/etc/clickhouse-keeper. Выделенные ниже строки необходимо изменить так, чтобы они были уникальными для каждого узла:
| Каталог | Файл |
|---|---|
fs/volumes/clickhouse-keeper-01/etc/clickhouse-keeper | keeper_config.xml |
fs/volumes/clickhouse-keeper-02/etc/clickhouse-keeper | keeper_config.xml |
fs/volumes/clickhouse-keeper-03/etc/clickhouse-keeper | keeper_config.xml |
Каждый файл конфигурации будет содержать следующую уникальную конфигурацию (см. ниже).
server_id должен быть уникальным для данного узла ClickHouse Keeper
в кластере и соответствовать серверу <id>, определённому в разделе <raft_configuration>.
tcp_port — это порт, используемый клиентами ClickHouse Keeper.
Следующий раздел описывает настройку серверов, участвующих в кворуме для алгоритма консенсуса Raft:
ClickHouse Cloud снимает операционную нагрузку, связанную с управлением шардами и репликами. Платформа автоматически обеспечивает высокую доступность, репликацию и принятие решений о масштабировании. Вычислительные ресурсы и хранилище разделены и автоматически масштабируются по мере необходимости, не требуя ручной настройки и постоянного обслуживания.
Проверка настройки
Убедитесь, что Docker запущен на вашем компьютере.
Запустите кластер командой docker-compose up из корневого каталога cluster_1S_2R:
Вы увидите, как docker начнет загружать образы ClickHouse и Keeper, а затем запустит контейнеры:
Чтобы проверить, что кластер работает, подключитесь к clickhouse-01 или clickhouse-02 и выполните следующий запрос. Ниже приведена команда для подключения к первому узлу:
При успешном подключении вы увидите командную строку клиента ClickHouse:
Выполните следующий запрос, чтобы проверить, какие топологии кластера определены для каких хостов:
Выполните следующий запрос, чтобы проверить состояние кластера ClickHouse Keeper:
Команда mntr также часто используется для проверки того, что ClickHouse Keeper
запущен, и для получения информации о состоянии и взаимоотношениях трёх узлов Keeper.
В конфигурации, используемой в этом примере, три узла работают совместно.
Узлы выбирают лидера, а остальные узлы становятся ведомыми.
Команда mntr предоставляет информацию, связанную с производительностью, а также о том,
является ли конкретный узел лидером или ведомым.
Вам может потребоваться установить netcat, чтобы отправить команду mntr Keeper’у.
См. страницу nmap.org для получения информации о скачивании.
Выполните приведённую ниже команду в оболочке на clickhouse-keeper-01, clickhouse-keeper-02 и
clickhouse-keeper-03, чтобы проверить состояние каждого узла Keeper. Команда
для clickhouse-keeper-01 показана ниже:
Ниже приведён пример ответа от ведомого узла:
Ниже приведён пример ответа от ведущего узла:
Таким образом, вы успешно настроили кластер ClickHouse с одним шардом и двумя репликами. На следующем шаге вы создадите таблицу в кластере.
Создание базы данных
Теперь, когда вы убедились, что кластер правильно настроен и работает, вы создадите ту же таблицу, что и в руководстве по примеру набора данных цен на недвижимость в Великобритании. Набор данных содержит около 30 миллионов записей о ценах на недвижимость в Англии и Уэльсе с 1995 года.
Подключитесь к клиенту каждого хоста, выполнив следующие команды в отдельных вкладках или окнах терминала:
Вы можете выполнить приведённый ниже запрос из clickhouse-client на каждом хосте, чтобы убедиться, что помимо стандартных баз данных других пока не создано:
Из клиента clickhouse-01 выполните следующий распределённый DDL-запрос с использованием
конструкции ON CLUSTER для создания новой базы данных uk:
Вы можете снова выполнить тот же запрос, что и ранее, из клиента каждого хоста,
чтобы убедиться, что база данных была создана во всём кластере, несмотря на то, что
запрос выполнялся только на clickhouse-01:
Создание таблицы в кластере
После создания базы данных создайте таблицу в кластере. Выполните следующий запрос из любого клиента узла:
Обратите внимание, что этот запрос идентичен запросу из исходной инструкции CREATE в
руководстве по примеру набора данных цен на недвижимость в Великобритании,
за исключением конструкции ON CLUSTER и использования движка ReplicatedMergeTree.
Конструкция ON CLUSTER предназначена для распределённого выполнения DDL-запросов (Data Definition Language),
таких как CREATE, DROP, ALTER и RENAME, что обеспечивает применение
изменений схемы на всех узлах кластера.
Движок ReplicatedMergeTree
работает так же, как обычный табличный движок MergeTree, но дополнительно реплицирует данные.
Вы можете выполнить приведённый ниже запрос из клиента clickhouse-01 или clickhouse-02, чтобы убедиться, что таблица создана на всех узлах кластера:
Вставка данных
Поскольку набор данных большой и его полный приём занимает несколько минут, сначала мы вставим только небольшое подмножество.
Вставьте меньший набор данных, используя следующий запрос из clickhouse-01:
Обратите внимание, что данные полностью реплицированы на каждом хосте:
Чтобы продемонстрировать, что происходит при сбое одного из хостов, создайте простую тестовую базу данных и тестовую таблицу на любом из хостов:
Как и в случае с таблицей uk_price_paid, мы можем вставлять данные с любого хоста:
Что произойдет, если один из хостов выйдет из строя? Чтобы смоделировать это, остановите
clickhouse-01, выполнив команду:
Проверьте, что хост недоступен, выполнив команду:
Теперь, когда clickhouse-01 остановлен, вставьте ещё одну строку данных в тестовую таблицу и выполните запрос к таблице:
Теперь перезапустите clickhouse-01 следующей командой (для подтверждения можно снова выполнить docker-compose ps):
Выполните запрос к тестовой таблице снова из clickhouse-01 после запуска docker exec -it clickhouse-01 clickhouse-client:
Если на данном этапе вы хотите загрузить полный набор данных о ценах на недвижимость в Великобритании для экспериментов, выполните следующие запросы:
Выполните запрос к таблице из clickhouse-02 или clickhouse-01:
Заключение
Преимущество такой топологии кластера заключается в том, что при наличии двух реплик ваши данные находятся на двух отдельных хостах. Если один хост выходит из строя, другая реплика продолжает обслуживать запросы к данным без каких‑либо потерь. Это устраняет единые точки отказа на уровне хранилища.
Когда один хост выходит из строя, оставшаяся реплика по‑прежнему может:
- Обрабатывать запросы на чтение без прерываний
- Принимать новые записи (в зависимости от настроек согласованности)
- Поддерживать доступность сервиса для приложений
Когда вышедший из строя хост снова становится доступен, он может:
- Автоматически синхронизировать недостающие данные с исправной реплики
- Возобновить нормальную работу без ручного вмешательства
- Быстро восстановить полную избыточность
В следующем примере мы рассмотрим, как настроить кластер из двух шардов, но с единственной репликой.
